系统的架构是整个系统的全貌,我们要了解的是系统包含的各个模块以及每个模块的指责和各个部分的相互关系。flink的架构如下图所示:
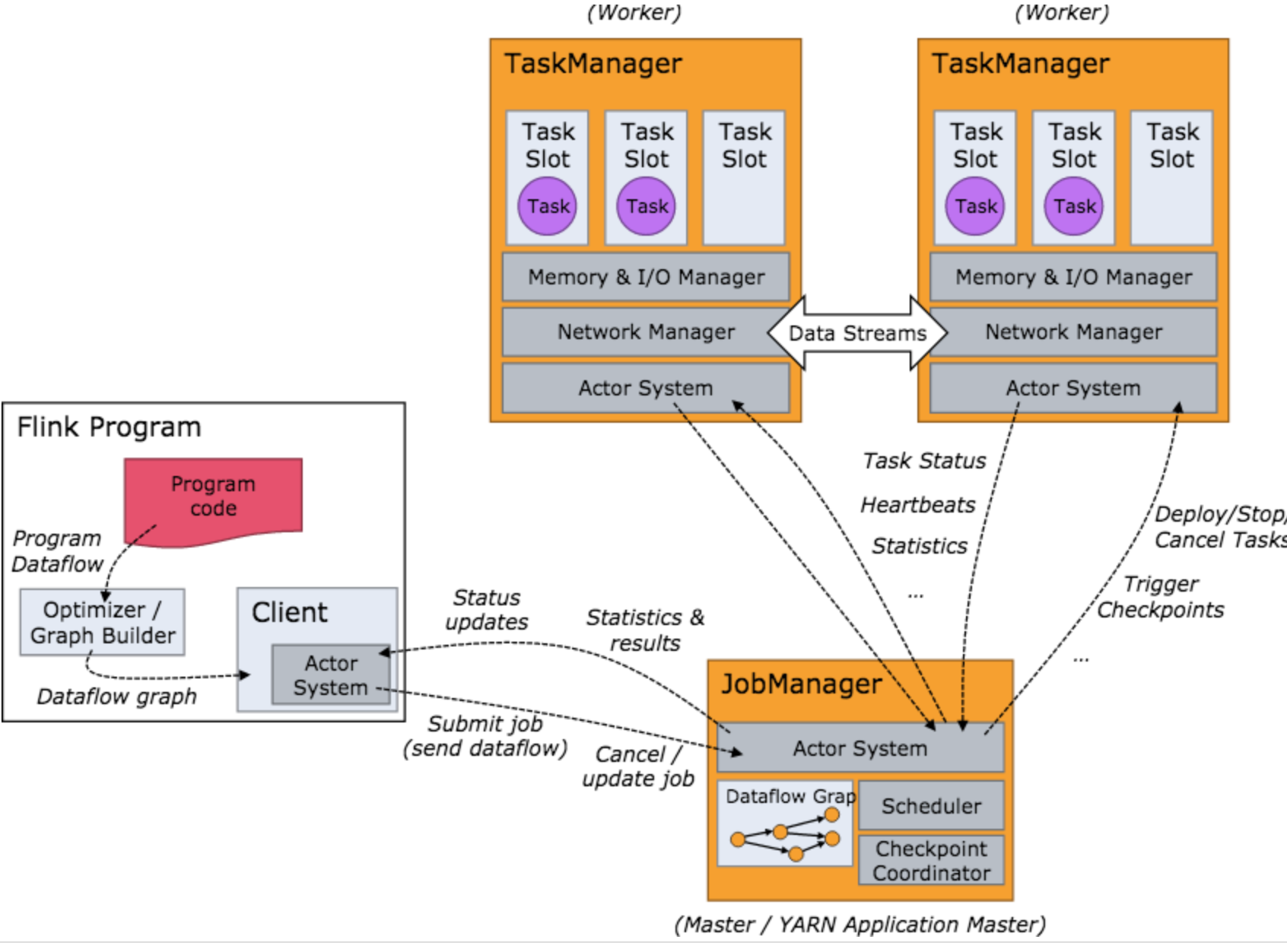
如图所示:flink系统包含三部分:client, jobmanager,taskmanager。
-
client
程序中编写使用的每个算子(map, flatmap等)都会解析为operate,Flink采用了类似责任链模式的方式对operator进行组合,client根据operate配置的责任链模式将生成程序的拓扑结构图StreamGraph,并转换为JobGraph,也就是task list,然后将JobGraph提交到jobmanager,并返回。 -
jobmanager
主要负责调度 Job 并协调 Task 做 checkpoint。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
当job执行的时候,jobmanager将和分发的任务保持通信,来对任务进行调度(启动下一个task,响应完成或失败的task)。
一个jobgraph代表一个包含一系列操作(operators用jobvertex表示)和中间数据(intermediateDataset)的数据流, 每个operator具有属性,比如说执行的并行度。除此之外,jobgraph包含一系列的和运行相关的库。
当jobmanager接收Jobgraph,当jobmanager将jobgrph转换为ExecutionGraph。ExecutionGraph是一个并行的Jobgrph。每一个jobVerter,将被转换为一个ExecutionVetex。一个并行度为100的operate将被转换为1个jobvertex和100个ExecutionVertices。ExecutionVertex追踪subtask的状态。一个jobvetex中转换的所有的ExecutionVertices,包含在一个ExecutionJobVertex中,维护一个状态。除了vertics,ExecutionGraph还包含termediateResult和inteermediateResultPations。
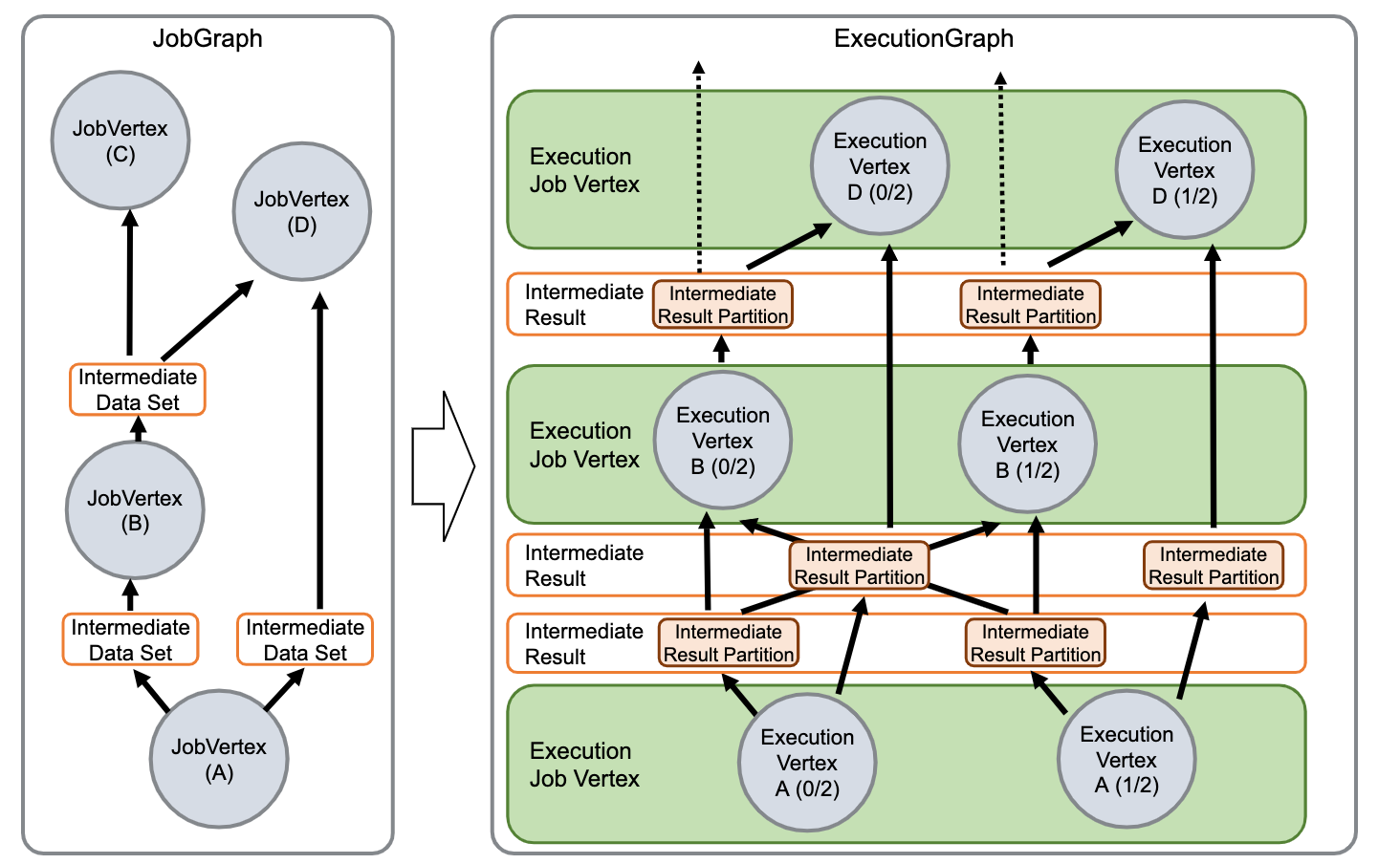
- Taskmanager
关键词:task, slot,pipeline
flink中的执行单元是task slot, 每个taskmanger中包含一个或者多个slot,Taskmanger在启动的时候就设置好了槽位数slot。每个slot能启动一个 Task线程,可以运行pipeline或并行任务。 一个pipeline包含多个连续的任务,比如第n个并行任务的MapFunction和ReduceFunction。flink通常执行的都是连续任务,无论是流式计算还是批处理都是经常发生的。Taskmanager从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
下面的图中,一个程序包含一个source,一个mapfunction和一个reducefunction。source和mapfunction执行的并行度为4,reducefunction的并行度为3.一个pipeline的执行顺序为source->map>reduce. 在一个2个包含3个slotTaskmanager的集群上,程序的执行图如下所示:

参考文档