Sharding-Sphere
简介
1、ShardingSphere是一套开源的分布式数据库中间件的解决方案
2、它由三个产品组成:Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar。
3、是关系型数据库中间件,合理在分布式环境下使用关系型数据库操作
Sharding-JDBC
轻量级Java框架,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架(如:JPA、Hibernate、mybatis、Spring JDBC Template或直接使用JDBC),
支持任何第三方的数据库连接池(如:DBCP、C3P0、BoneCP、Druid、HikariCP等),支持仍以实现JDBC规范的数据库(目前支持MySQL、Oracle、SQLServer、
PostgreSQL以及任何遵循SQL92标准的数据库)。
ShardingSphere-Proxy
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL 版本,它可以
使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
分库分表介绍
数据库的数据量是不可控的,随着时间和业务发展,造成表中数据越来越多,如果再去对数据库表CRUD操作时,造成性能问题
解决方案
- 从硬件上解决,增加硬盘、内存。(治标不治本)
- 分库分表
为了解决由于数据量过大而造成数据库性能降低问题。
分库分表方式
分库分表有两种方式:垂直切分和水平切分
垂直切分:垂直分表和垂直分库
水平切分:水平分表和水平分库
垂直切分
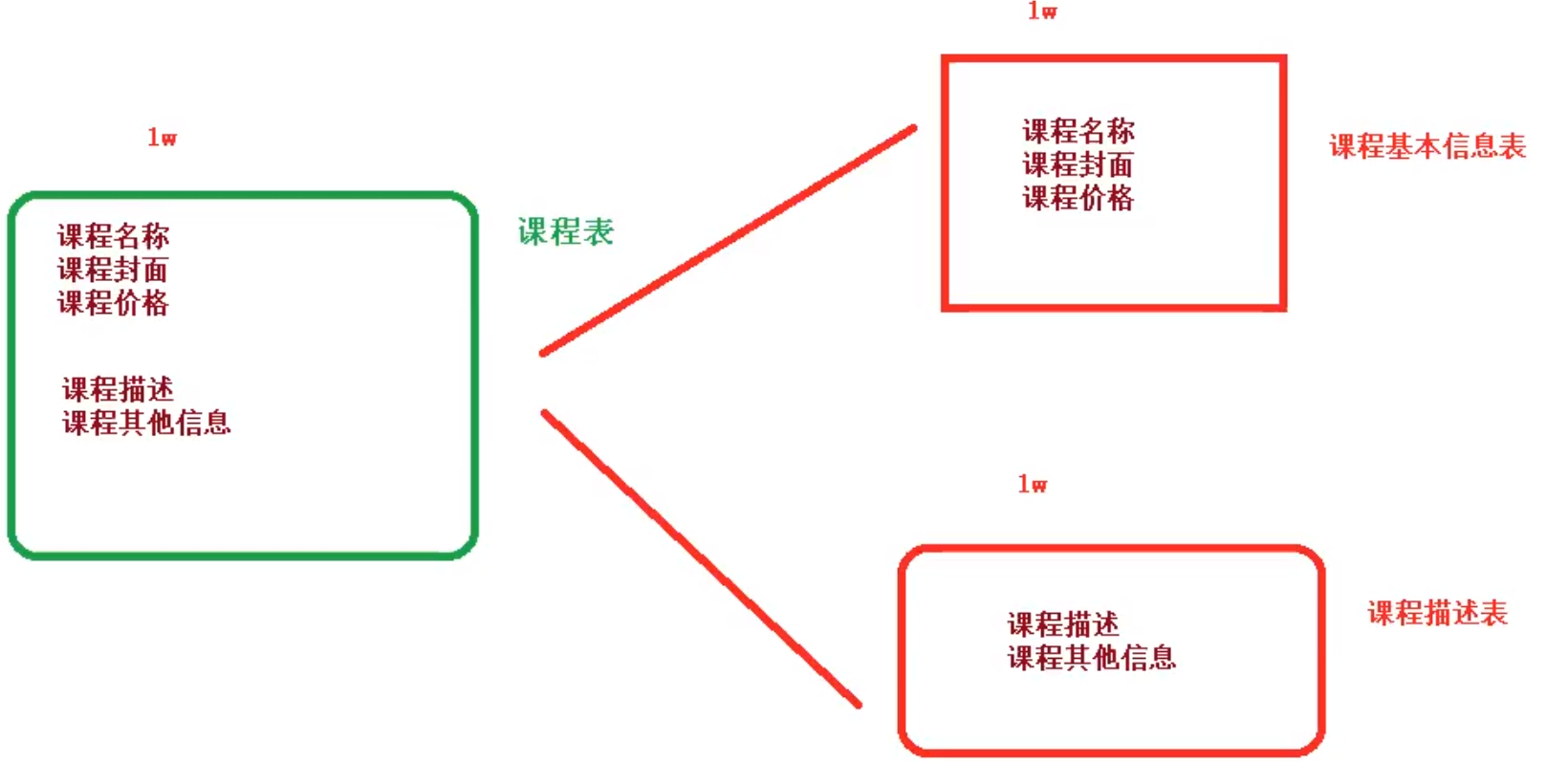
垂直分表
操作数据库中某张表,把这张表中一部分字段数据存到一张新表里面,再把这张表另一部分字段数据存到另外一张表里面
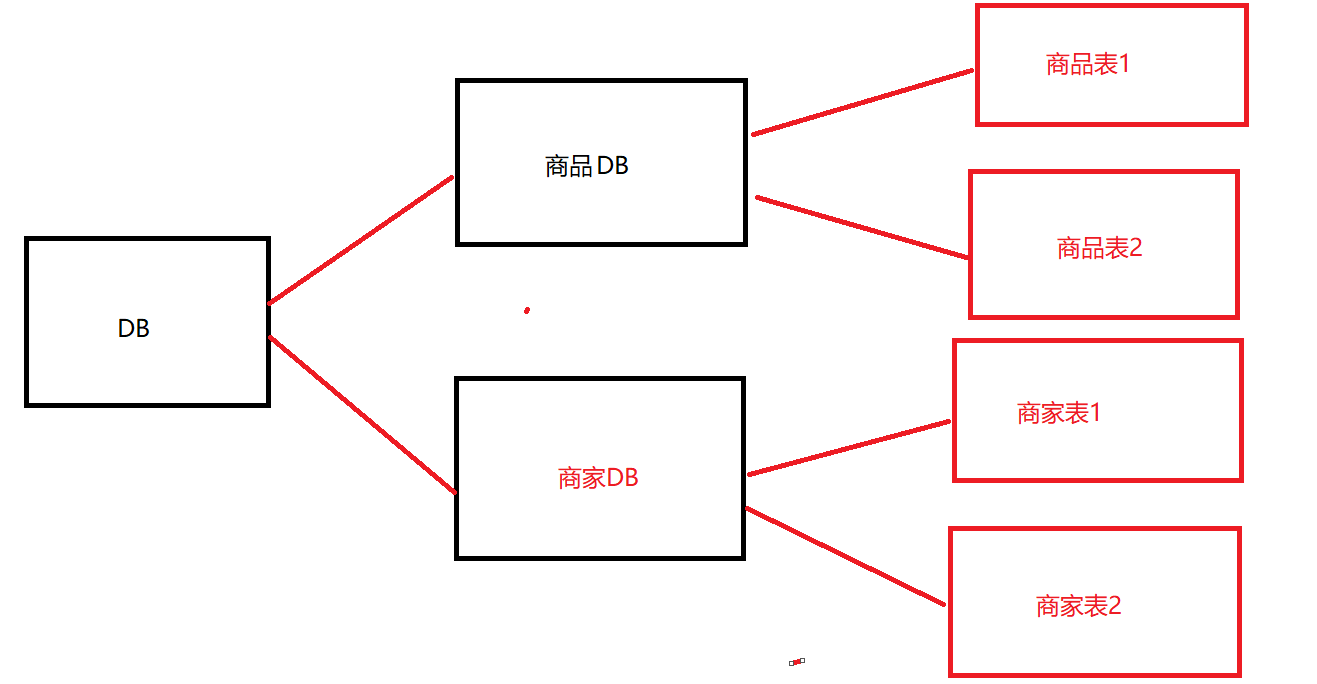
垂直分库
把单一数据库按照业务进行划分,专库专表。
水平切分
水平分表
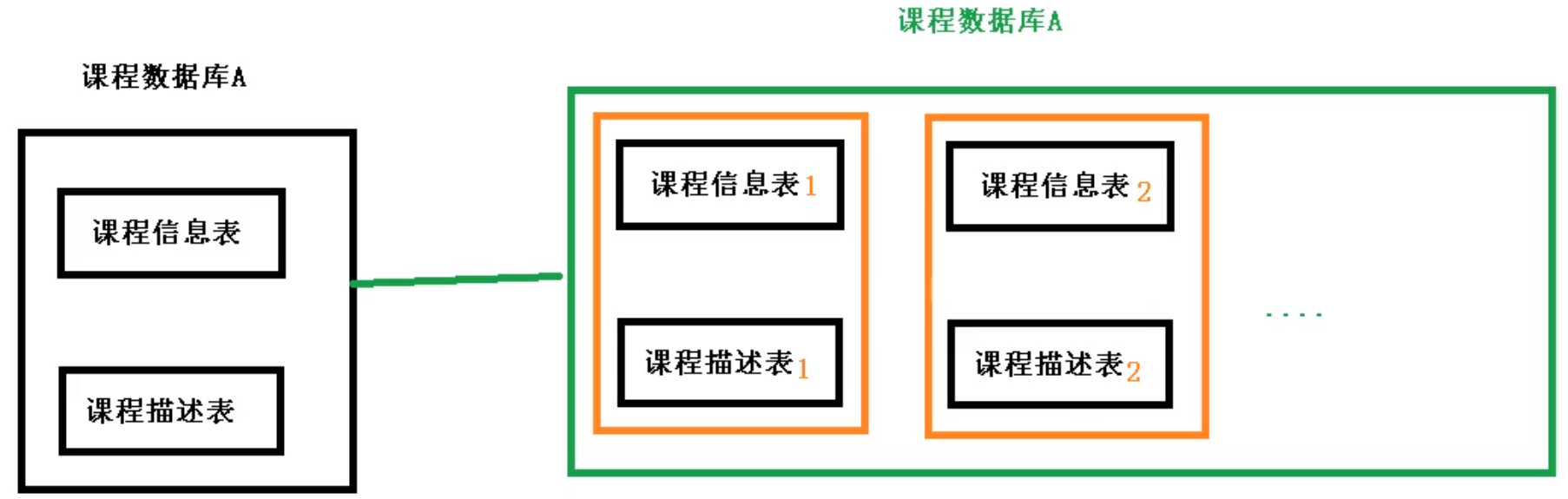
水平分库
这种方式带来了一些问题,如何将数据插入这两个库?可以采用根据id取余的方式来插入数据库,比如,这里有两个库,用
id%数据库个数,如果余数为0,就在A库,余数为1,就在B库
分库分表的应用和问题
应用
- 在数据库设计时候考虑垂直分库和垂直分表
- 随着数据库数据量增加,不要马上考虑做水平拆分,首先考虑缓存处理、读写分离,使用索引等方式,如果这些方式都不能根本解决问题了,再考虑做水平拆分
分库分表带来的问题
- 跨节点连接查询问题(分页、排序)
- 多数据源管理问题
Sharding-JDBC
简介
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库,目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。
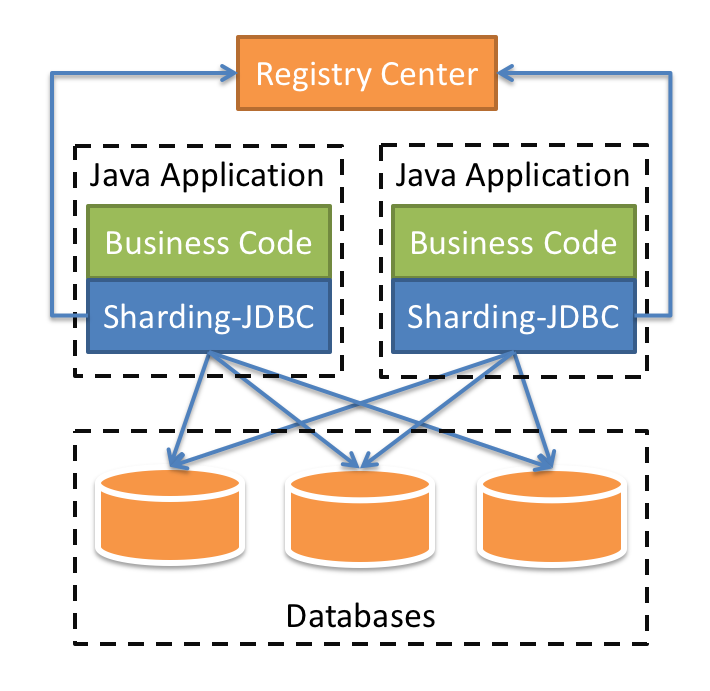
Sharding-JDBC实现水平分表
搭建环境
-
创建shardingjdbcdemo项目(SpringBoot2.2.1)
-
引入依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.20</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.0.0-RC1</version> </dependency> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.0.5</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </dependency> </dependencies> -
创建数据库
按照水平分表的放肆,创建数据库和数据库表。
-
创建数据库course_db
-
在数据库中创建两张表course_1和course_2
-
约定规则,课程id是偶数把数据添加到course_1,奇数添加到course_2
CREATE TABLE course_1( cid BIGINT(20) PRIMARY KEY, cname VARCHAR(50) NOT NULL, user_id BIGINT(20) NOT NULL, cstatus VARCHAR(10) NOT NULL ) CREATE TABLE course_2( cid BIGINT(20) PRIMARY KEY, cname VARCHAR(50) NOT NULL, user_id BIGINT(20) NOT NULL, cstatus VARCHAR(10) NOT NULL )
-
-
编写代码
-
实体类
@Data @AllArgsConstructor @NoArgsConstructor public class Course { private Long cid; private String cname; private Long userId; private String cstatus; } -
Mapper
@Mapper public interface CourseMapper extends BaseMapper<Course> { } -
启动类
@SpringBootApplication @MapperScan("om.atguigu.shardingjdbcdemo.mapper") public class ShardingjdbcdemoApplication { public static void main(String[] args) { SpringApplication.run(ShardingjdbcdemoApplication.class, args); } }
-
-
配置Sharding-JDBC分片策略
- 在
application.yml配置文件中进行配置
注: course是表名前缀
# 配置分片策略 spring: shardingsphere: datasource: #配置数据源名字 names: ds1 # 配置数据源具体内容 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.128:3306/course_db username: root password: 123456 # 指定course表分布情况,配置表在哪个数据库里面,表名称都是什么 sharding: tables: course: actual-data-nodes: ds1.course_$->{1..2} #指定course表里面主键生成策略 key-generator: column: cid # SNOWFLAKE 雪花算法生成的id type: SNOWFLAKE # 指定分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中 table-strategy: #inline 的方式不支持范围查询 inline: sharding-column: cid algorithm-expression: course_$->{cid % 2 + 1} # 打开SQL输出日志 props: sql: show: true - 在
-
测试
@RunWith(SpringRunner.class) @SpringBootTest class ShardingjdbcdemoApplicationTests { @Autowired private CourseMapper courseMapper; @Test void addCourse() { Course course = new Course(); course.setCname("Java"); course.setUserID(100L); course.setCstatus("NOrmal"); int insert = courseMapper.insert(course); } } 会出现如下错误:

这个错误是由于我们有两张表,只有一个实体类,虽然字段一样,但是不能映射,只要添加上面的配置红框的配置即可。
spring: main: allow-bean-definition-overriding: true再次测试:
2021-03-16 16:57:48.550 INFO 17616 --- [ main] ShardingSphere-SQL : Actual SQL: ds1 ::: INSERT INTO course_2 (cname, user_id, cstatus, cid) VALUES (?, ?, ?, ?) ::: [Java, 100, NOrmal, 578627173078794241]可以看到cid为奇数,在course_2表
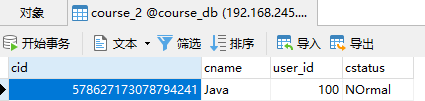
成功插入到2号表
Sharding-JDBC实现水平分库
需求分析
创建两个数据库
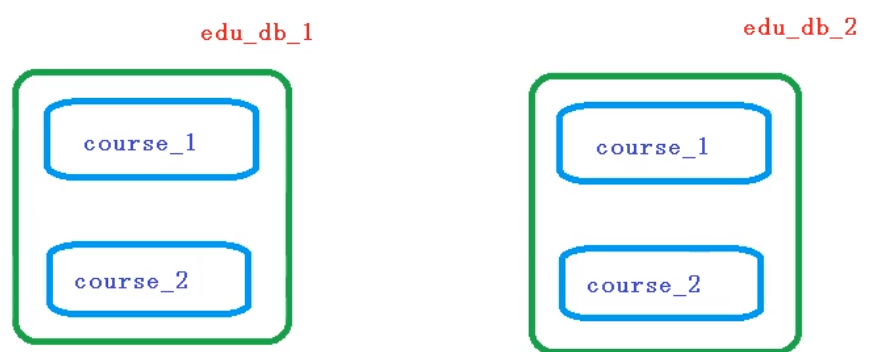
约定分片规则:
数据库规则:
- userid为偶数的数据添加到edu_db_1数据库中
- 奇数数据添加到edu_db_2数据库中
表规则:
- cid为偶数数据添加到course_1表
- 奇数数据添加到course_2表中
创建数据库

// 建表SQL
CREATE TABLE course_1(
cid BIGINT(20) PRIMARY KEY,
cname VARCHAR(50) NOT NULL,
user_id BIGINT(20) NOT NUll,
cstatus VARCHAR(10) NOT NULL
)
配置数据库分片规则
# 配置分片策略
spring:
shardingsphere:
datasource:
#配置数据源名字
names: ds1,ds2
# 配置数据源具体内容
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.245.130:3306/edu_db_1
username: root
password: 123456
# 第二个数据源
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.245.130:3306/edu_db_2
username: root
password: 123456
# 指定数据库分布情况,配置表在哪个数据库里面,表名称都是什么
# m1 m2 course_1 course_2
sharding:
tables:
course:
actual-data-nodes: ds$->{1..2}.course_$->{1..2}
#指定course表里面主键生成策略
key-generator:
column: cid
# SNOWFLAKE 雪花算法生成的id
type: SNOWFLAKE
# 指定表分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中
table-strategy:
inline:
sharding-column: cid
algorithm-expression: course_$->{cid % 2 + 1}
#指定库分片策略
# 1. userid为偶数的数据添加到edu_db_1数据库中
# 2. 奇数数据添加到edu_db_2数据库中
database-strategy:
standard:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2 + 1}
#指定库分片策略
# 1. userid为偶数的数据添加到edu_db_1数据库中
# 2. 奇数数据添加到edu_db_2数据库中
# default-database-strategy:
# inline:
# sharding-column: user_id
# algorithm-expression: ds$->{user_id % 2 + 1}
# 打开SQL输出日志
props:
sql:
show: true
main:
allow-bean-definition-overriding: true
编写测试代码
@Test
void addCourseDb() {
Course course = new Course();
course.setCname("JavaDemo");
course.setUserId(100L);
course.setCstatus("Normal");
int insert = courseMapper.insert(course);
}
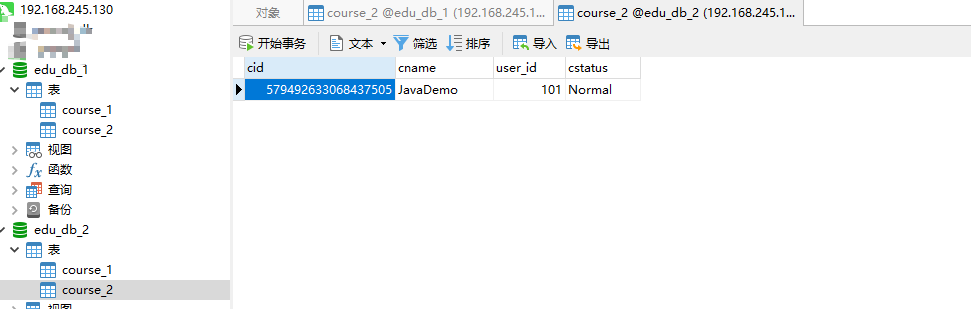
根据分片规则,user_id为偶数是在ds1(edu_db_1)库,cid偶数是在course_1表,我们来看看结果:

cid是奇数,插入了course_2表。user_id是偶数,插入了ds1库


@Test
public void findCourseDb() {
QueryWrapper<Course> wrapper = new QueryWrapper<>();
wrapper.eq("user_id", 100L);
wrapper.eq("cid",579491782740410369L);
Course course = courseMapper.selectOne(wrapper);
System.out.println("-------------------------->" + course);
}

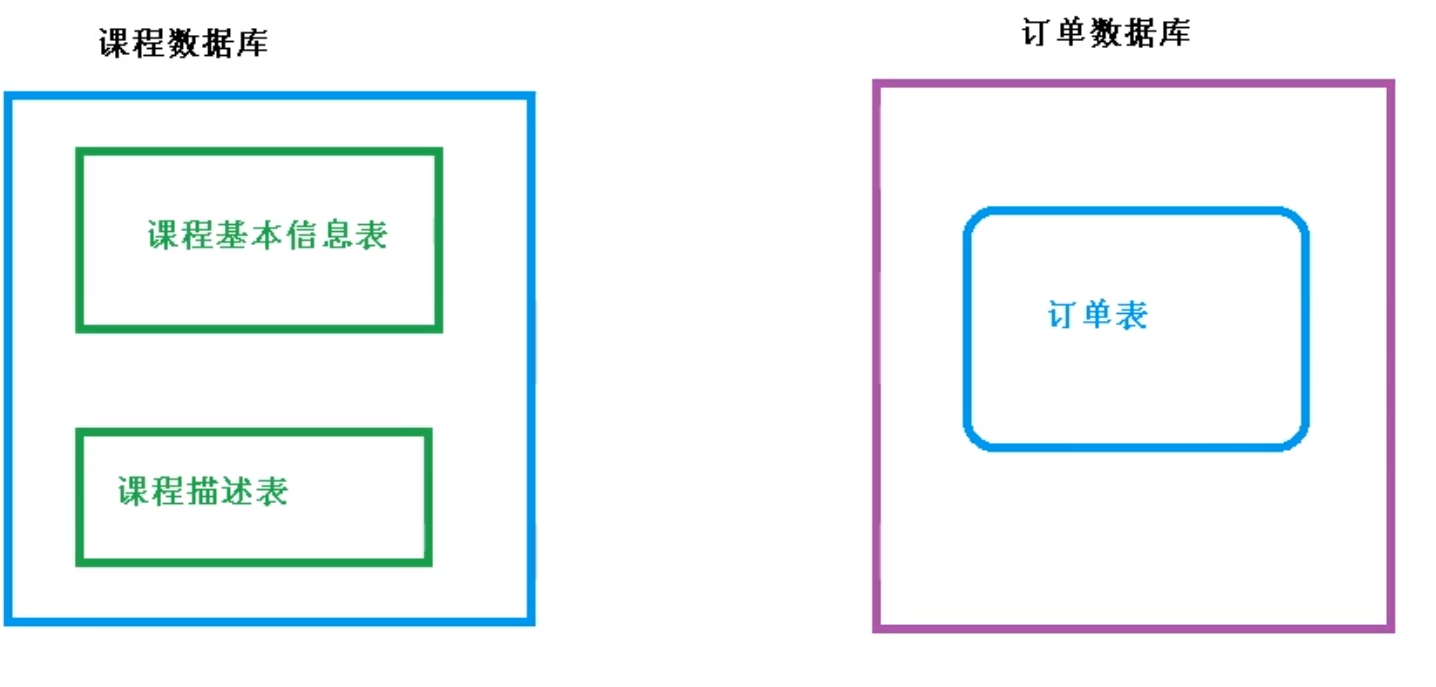
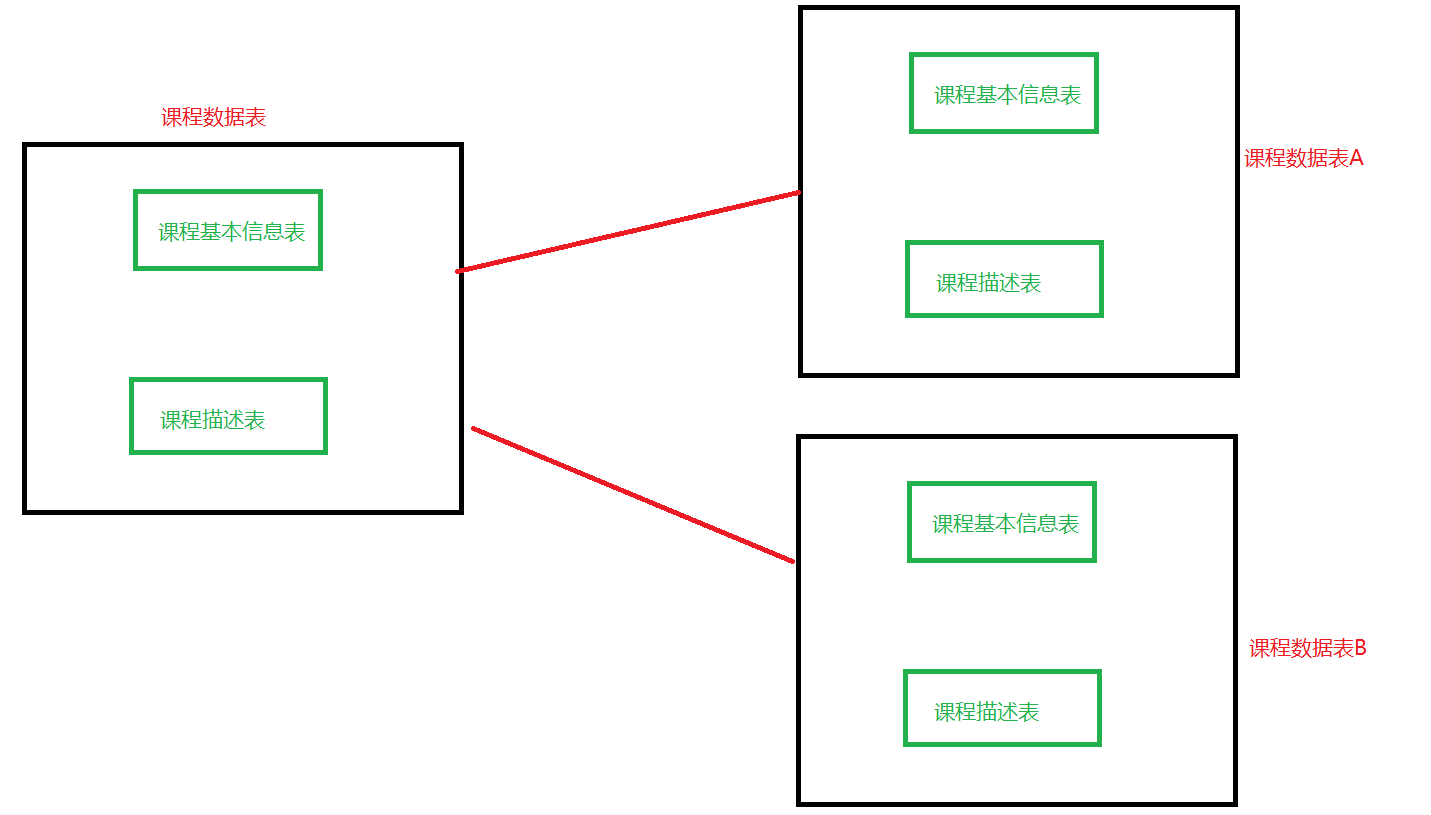
Sharding-JDBC实现垂直分库
需求分析
垂直分库就是专库专表,如下
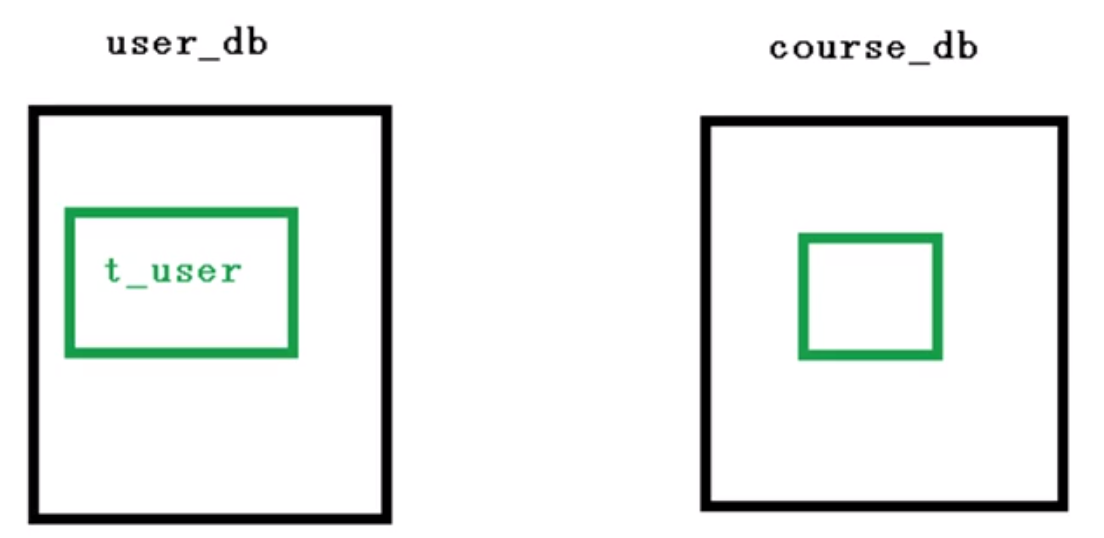
创建数据库和表
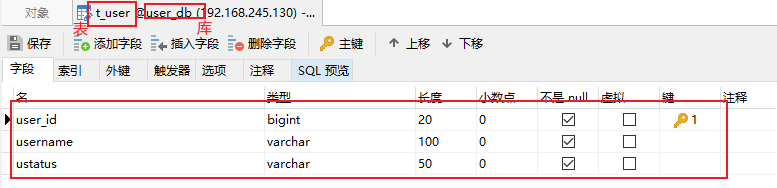
编写代码
-
创建user实体类和UserMapper
@Data public class User { private Long userId; private String username; private String ustatus; }@Mapper public interface UserMapper extends BaseMapper<User> { } -
配置垂直分库策略
# 配置分片策略 spring: shardingsphere: datasource: #配置数据源名字 names: ds1,ds2,ds3 # 配置数据源具体内容 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.130:3306/edu_db_1 username: root password: 123456 # 第二个数据源 ds2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.130:3306/edu_db_2 username: root password: 123456 # 第三个数据源 ds3: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.130:3306/user_db username: root password: 123456 # 指定数据库分布情况,配置表在哪个数据库里面,表名称都是什么 # m1 m2 course_1 course_2 sharding: tables: course: actual-data-nodes: ds$->{1..2}.course_$->{1..2} #指定course表里面主键生成策略 key-generator: column: cid # SNOWFLAKE 雪花算法生成的id type: SNOWFLAKE # 指定表分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中 table-strategy: inline: sharding-column: cid algorithm-expression: course_$->{cid % 2 + 1} #指定库分片策略 # 1. userid为偶数的数据添加到edu_db_1数据库中 # 2. 奇数数据添加到edu_db_2数据库中 database-strategy: inline: sharding-column: user_id algorithm-expression: ds$->{user_id % 2 + 1} # 配置user_db数据库里面t_user 专库专表 t_user: actual-data-nodes: ds$->{3}.t_user #指定course表里面主键生成策略 key-generator: column: user_id # SNOWFLAKE 雪花算法生成的id type: SNOWFLAKE # 指定表分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中 table-strategy: inline: sharding-column: user_id algorithm-expression: t_user #指定库分片策略 # 1. userid为偶数的数据添加到edu_db_1数据库中 # 2. 奇数数据添加到edu_db_2数据库中 # default-database-strategy: # inline: # sharding-column: user_id # algorithm-expression: ds$->{user_id % 2 + 1} # 打开SQL输出日志 props: sql: show: true main: allow-bean-definition-overriding: true -
编写测试代码
@Test public void addUserDb() { User user = new User(); user.setUsername("lin"); user.setUstatus("a"); userMapper.insert(user); } @Test public void findUserDb() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.eq("user_id", 580532807156105217L); User user = userMapper.selectOne(wrapper); System.out.println("-------------------------->" + user); }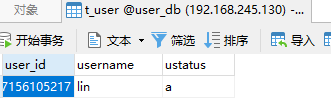
查询:

Sharding-JDBC操作公共表
什么是公共表?
- 存储固定数据的表,表数据很少发生变化,查询时经常要进行关联。
- 在每个数据库中都创建出相同结构公共表。
- 操作公共表时,同时操作添加了公共表的数据库中的公共表,添加记录时,同时添加,删除时,同时删除。
实现
-
在多个数据库中创建相同结构公共表。前面我们有三个库,现在我们在这三个库中创建表。
建表SQL
CREATE TABLE t_udict( dictid BIGINT(20) PRIMARY KEY, ustatus VARCHAR(100) NOT NULL, uvalue VARCHAR(100) NOT NULL ) -
在application.yml中配置
# 配置分片策略 spring: shardingsphere: sharding: broadcast-tables: t_udict tables: t_udict: key-generator: column: dictid type: SNOWFLAKE -
测试代码
-
创建实体类和mapper
@Data @TableName(value = "u_udict") public class Udict { private Long dictid; private String ustatus; private String uvalue; }@Mapper public interface UdictMapper extends BaseMapper<Udict> { } -
测试代码
@Test public void addUserDb() { User user = new User(); user.setUsername("lin"); user.setUstatus("a"); userMapper.insert(user); }
@Test void deleteDict() { QueryWrapper<Udict> wrapper = new QueryWrapper<>(); wrapper.eq("dictid", 580819000607375361L); udictMapper.delete(wrapper); }
-
Sharding-JDBC实现读写分离
什么是读写分离
为了确保数据库产品的稳定性,很多数据库拥有双击热备功能。也就是,第一台数据库服务器,是对外提供增删改业务的生产服务器;第二胎数据库服务器,主要进行读的操作。
原理:让主数据库(master)处理事务性增、改、删操作,而从数据库(slave)处理select查询操作
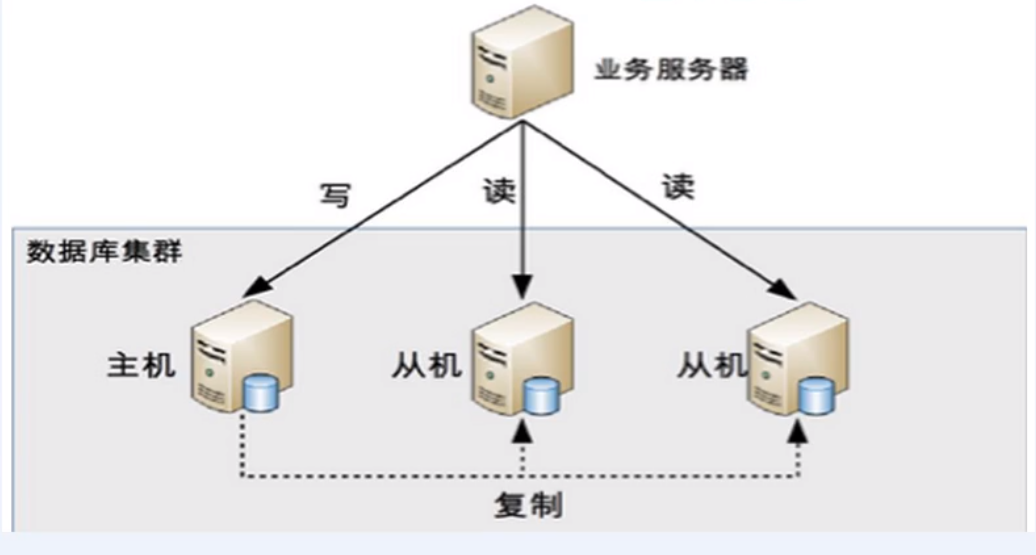
读写分离原理
主从复制:当主服务器有写入(insert/update/delete)语句时候,从服务器自动获取。
读写分离:insert/update/delete语句操作一台服务器,select操作另一个服务器
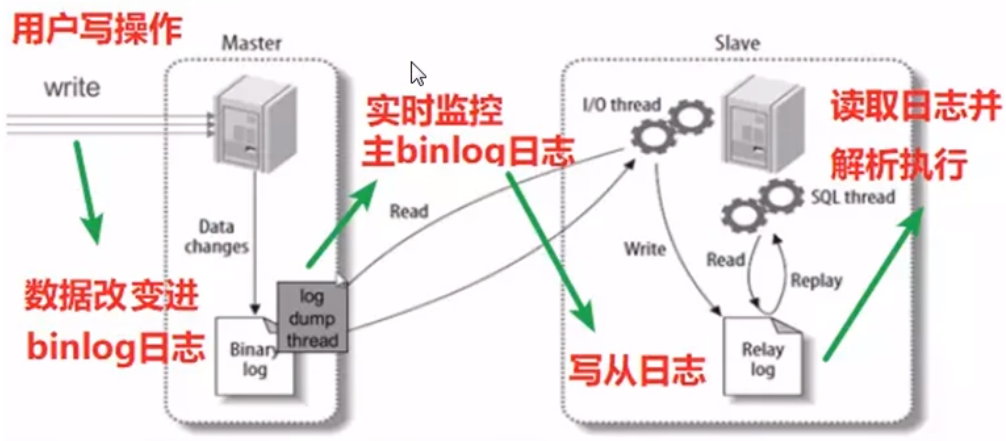
Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库,它提供透明化读写分离,让使用方法尽量像使用一个数据库一样使用主从数据库集群。
主从复制配置
Sharding-JDBC操作主从
-
在配置文件中配置主从分离
# 配置分片策略 spring: shardingsphere: datasource: #配置数据源名字 names: ds1,ds2,ds3,s0 # 配置数据源具体内容 ds1: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.131:3306/edu_db_1 username: root password: 123456 # 第二个数据源 ds2: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.131:3306/edu_db_2 username: root password: 123456 # 第三个数据源 ds3: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.131:3306/user_db username: root password: 123456 # 从服务器 s0: type: com.alibaba.druid.pool.DruidDataSource driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://192.168.245.131:3307/user_db username: root password: 123456 # 指定数据库分布情况,配置表在哪个数据库里面,表名称都是什么 # m1 m2 course_1 course_2 sharding: tables: course: actual-data-nodes: ds$->{1..2}.course_$->{1..2} #指定course表里面主键生成策略 key-generator: column: cid # SNOWFLAKE 雪花算法生成的id type: SNOWFLAKE # 指定表分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中 table-strategy: inline: sharding-column: cid algorithm-expression: course_$->{cid % 2 + 1} #指定库分片策略 # 1. userid为偶数的数据添加到edu_db_1数据库中 # 2. 奇数数据添加到edu_db_2数据库中 database-strategy: inline: sharding-column: user_id algorithm-expression: ds$->{user_id % 2 + 1} # 配置user_db数据库里面t_user 专库专表 t_user: #actual-data-nodes: ds$->{3}.t_user actual-data-nodes: ds0.t_user #指定course表里面主键生成策略 key-generator: column: user_id # SNOWFLAKE 雪花算法生成的id type: SNOWFLAKE # 指定表分片策略, 约定cid值偶数添加到course_1表中,奇数添加到course_2表中 table-strategy: inline: sharding-column: user_id algorithm-expression: t_user t_udict: key-generator: column: dictid type: SNOWFLAKE #配置公共表 broadcast-tables: t_udict # 从服务器相关配置 master-slave-rules: ds3: master-data-source-name: ds3 slave-data-source-names: s0 #指定库分片策略 # 1. userid为偶数的数据添加到edu_db_1数据库中 # 2. 奇数数据添加到edu_db_2数据库中 # default-database-strategy: # inline: # sharding-column: user_id # algorithm-expression: ds$->{user_id % 2 + 1} # 打开SQL输出日志 props: sql: show: true main: allow-bean-definition-overriding: true -
编写测试代码
@Test public void addUserDb() { User user = new User(); user.setUsername("lucymary"); user.setUstatus("a"); userMapper.insert(user); }
@Test public void findUserDb() { QueryWrapper<User> wrapper = new QueryWrapper<>(); wrapper.eq("user_id", 465508031619137537L); User user = userMapper.selectOne(wrapper); System.out.println("-------------------------->" + user); }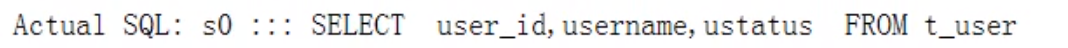
Sharding-JDBC实现范围查询
配置yaml
spring:
shardingsphere:
sharding:
tables:
course:
table-strategy:
standard:
sharding-column: cid
range-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.RangeTableShardingAlgorithm
precise-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.PreciseTableShardingAlgorithm
算法实现
public class PreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) {
String logicTableName = shardingValue.getLogicTableName();
String cid = shardingValue.getColumnName();
Long cidValue = shardingValue.getValue();
//实现ds$->{cid%2+1}
BigInteger bigIntegerB = BigInteger.valueOf(cidValue);
BigInteger resB = (bigIntegerB.mod(new BigInteger("2"))).add(new BigInteger("1"));
String key = "ds" + resB;
if (availableTargetNames.contains(key)) {
return key;
}
throw new UnsupportedOperationException("route" + key + " is not supported,please check your config");
}
}
public class RangeDSShardingAlgorithm implements RangeShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
//select * from course where cid between 200 and 300
//300
Long upperValue = rangeShardingValue.getValueRange().upperEndpoint();
//200
Long lowerValue = rangeShardingValue.getValueRange().lowerEndpoint();
String logicTableName = rangeShardingValue.getLogicTableName();
//ds$->{cid%2+1} ds1,ds2
return Arrays.asList("ds1", logicTableName + "ds2");
}
}
上面这种方式,只能实现in操作,不能实现between操作,因为上面只实现了分表的逻辑,没有实现分库的逻辑,分库还是使用的inline的方式,所以,我们要实现以下分库。
分库逻辑
-
yaml
spring: shardingsphere: sharding: tables: course: table-strategy: standard: sharding-column: cid range-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.RangeTableShardingAlgorithm precise-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.PreciseTableShardingAlgorithm database-strategy: standard: sharding-column: cid range-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.RangeDSShardingAlgorithm precise-algorithm-class-name: com.atguigu.shardingjdbcdemo.algorithm.PreciseDSShardingAlgorithm -
算法实现
public class PreciseDSShardingAlgorithm implements PreciseShardingAlgorithm<Long> { @Override public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Long> shardingValue) { String logicTableName = shardingValue.getLogicTableName(); String cid = shardingValue.getColumnName(); Long cidValue = shardingValue.getValue(); //实现ds$->{cid%2+1} BigInteger bigIntegerB = BigInteger.valueOf(cidValue); BigInteger resB = (bigIntegerB.mod(new BigInteger("2"))).add(new BigInteger("1")); String key = logicTableName + resB; if (availableTargetNames.contains(key)) { return key; } throw new UnsupportedOperationException("route" + key + " is not supported,please check your config"); } }public class RangeDSShardingAlgorithm implements RangeShardingAlgorithm<Long> { @Override public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) { //select * from course where cid between 200 and 300 //300 Long upperValue = rangeShardingValue.getValueRange().upperEndpoint(); //200 Long lowerValue = rangeShardingValue.getValueRange().lowerEndpoint(); String logicTableName = rangeShardingValue.getLogicTableName(); //ds$->{cid%2+1} ds1,ds2 return Arrays.asList("ds1", "ds2"); } }
Sharding-Proxy
简介
定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
- 适用于任何兼容MySQL/PostgreSQL协议的的客户端。
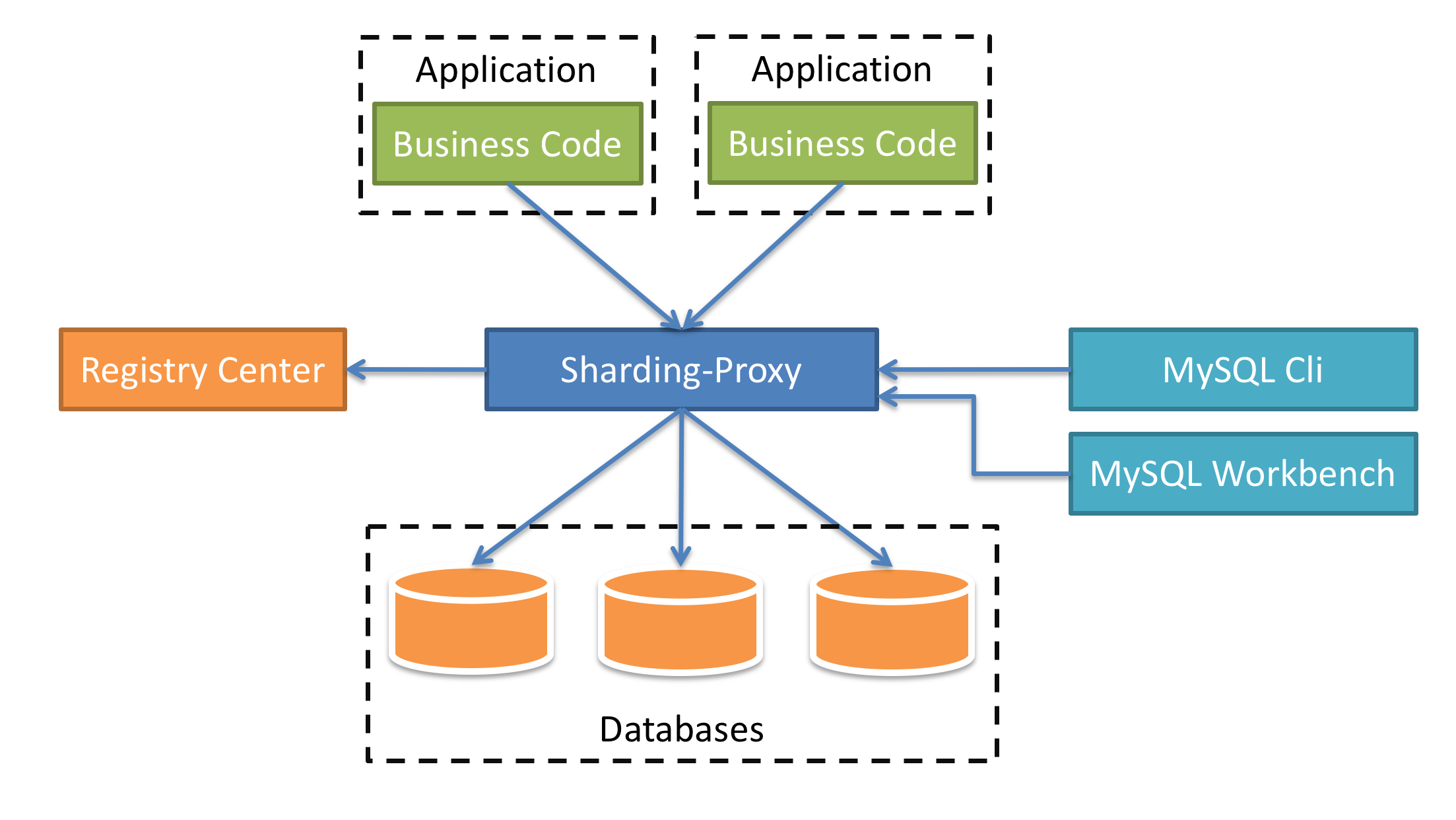
Sharding-Proxy是一个独立的应用,使用时需要安装服务,进行分库分表或者读写分离配置,然后启动就行。
安装下载
- 下载

点击binary后,会跳转到apache官网,然后点击下面的地址就可以下载了
-
安装
下载好之后,解压,到bin目录中启动
start.bat/start.sh文件即可

Sharding-Proxy分表
-
进入到conf文件夹中,修改
server.yaml文件# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ###################################################################################################### # # If you want to configure orchestration, authorization and proxy properties, please refer to this file. # ###################################################################################################### # #orchestration: # name: orchestration_ds # overwrite: true # registry: # type: zookeeper # serverLists: localhost:2181 # namespace: orchestration # authentication: users: # 账户 root: # 密码 password: 123456 sharding: password: sharding # 库名 authorizedSchemas: sharding_db props: max.connections.size.per.query: 1 acceptor.size: 16 # The default value is available processors count * 2. executor.size: 16 # Infinite by default. proxy.frontend.flush.threshold: 128 # The default value is 128. # LOCAL: Proxy will run with LOCAL transaction. # XA: Proxy will run with XA transaction. # BASE: Proxy will run with B.A.S.E transaction. proxy.transaction.type: LOCAL proxy.opentracing.enabled: false query.with.cipher.column: true sql.show: false -
修改config-sharding.yaml,这个文件主要是配置分库分表操作的。

如果要连接mysql,需要把驱动复制到lib文件夹中

配置分库分表规则:
schemaName: sharding_db dataSources: ds_0: url: jdbc:mysql://192.168.245.131:3306/edu_1?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 shardingRule: tables: t_order: actualDataNodes: ds_${0}.t_order_${0..1} tableStrategy: inline: shardingColumn: order_id algorithmExpression: t_order_${order_id % 2} keyGenerator: type: SNOWFLAKE column: order_id bindingTables: - t_order defaultDatabaseStrategy: inline: shardingColumn: user_id algorithmExpression: ds_${0} defaultTableStrategy: none: -
启动Sharding-Proxy服务
双击
start.bat启动,出现下面的字样表示成功启动
Sharding-Proxy默认端口号是3307,可以以命令行的方式启动:在cmd命令行窗口中输入start.bat 3308就可以以3308端口启动
-
通过Sharding-Proxy启动端口进行连接。
打开cmd窗口,连接Sharding-Proxy,连接方式和连接mysql一样
mysql -u root -p 123456 -h127.0.0.1 -P3307 # 这种方式连接的是Sharding-Proxy,不是连接的mysql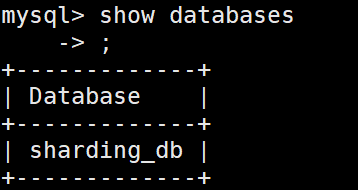
-
建表SQL
USE sharding_db; CREATE TABLE IF NOT EXISTS ds_0.t_order ( `order_id` BIGINT PRIMARY KEY, `user_id` INT NOT NULL, `status` VARCHAR ( 50 ) ); INSERT INTO t_order ( `order_id`, `user_id`, `status` ) VALUES ( 11, 1, 'jack' );
-
做完以上操作后,可以在edu_1中看到,有两个表

可以看到在t_order_1中有一下数据

再插入一条数据

在t_order_0中可以看到

-
这样我们的分表操作就配置完成了。
Sharding-Proxy分库
- 创建两个数据库
-
在配置文件中完成相应配置
schemaName: sharding_db dataSources: ds_0: url: jdbc:mysql://192.168.245.131:3306/edu_db_1?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 ds_1: url: jdbc:mysql://192.168.245.131:3306/edu_db_2?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 shardingRule: # 分表策略 tables: t_order: actualDataNodes: ds_${0..1}.t_order_${1..2} tableStrategy: inline: shardingColumn: order_id algorithmExpression: t_order_${order_id % 2 + 1} keyGenerator: type: SNOWFLAKE column: order_id bindingTables: - t_order # 分库策略 defaultDatabaseStrategy: inline: shardingColumn: user_id algorithmExpression: ds_${user_id % 2} defaultTableStrategy: none: -
启动Sharding-Proxy服务

-
创建表
create table if not exists ds_0.t_order(order_id bigint not null,user_id int not null,status varchar(50),primary key(order_id)); insert into t_order(order_id,user_id,status) values(1,1,"init");
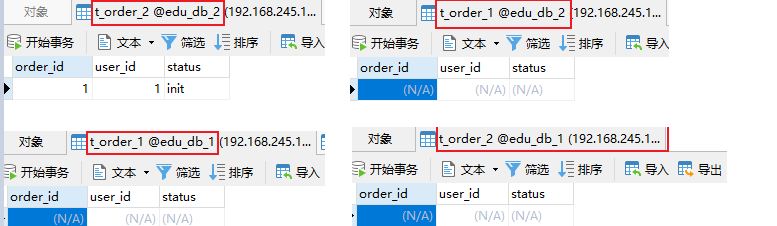
可以看到,在edu_db_2中的t_order_2中有数据
Sharding-Proxy读写分离
-
创建三个数据库

-
修改config-master_slave.yaml
schemaName: master_slave_db dataSources: master_ds: url: jdbc:mysql://192.168.245.131:3306/demo_ds_master?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 slave_ds_0: url: jdbc:mysql://192.168.245.131:3306/demo_ds_slave_0?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 slave_ds_1: url: jdbc:mysql://192.168.245.131:3306/demo_ds_slave_1?serverTimezone=UTC&useSSL=false username: root password: 123456 connectionTimeoutMilliseconds: 30000 idleTimeoutMilliseconds: 60000 maxLifetimeMilliseconds: 1800000 maxPoolSize: 50 masterSlaveRule: name: ms_ds masterDataSourceName: master_ds slaveDataSourceNames: - slave_ds_0 - slave_ds_1 -
启动sharding-Proxy服务
Sharding-JDBC原理
内核剖析
数据分片就是把一个逻辑SQL转成多个实际SQL去执行。
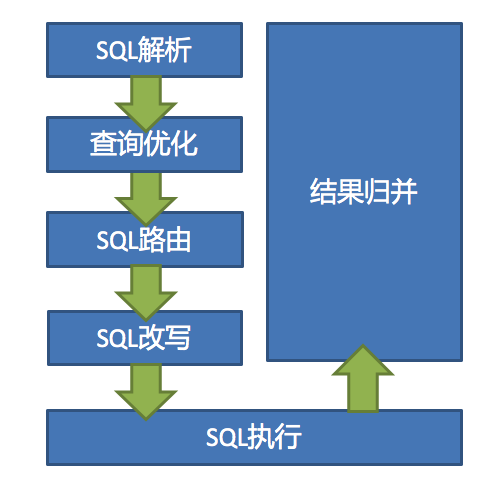
SQL 解析
分为词法解析和语法解析。 先通过词法解析器将 SQL 拆分为一个个不可再分的单词。再使用语法解析器对 SQL 进行理解,并最终提炼出解析上下文。 解析上下文包括表、选择项、排序项、分组项、聚合函数、分页信息、查询条件以及可能需要修改的占位符的标记。
执行器优化
合并和优化分片条件,如 OR 等。
SQL 路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL 改写
将 SQL 改写为在真实数据库中可以正确执行的语句。SQL 改写分为正确性改写和优化改写。
SQL 执行
通过多线程执行器异步执行。
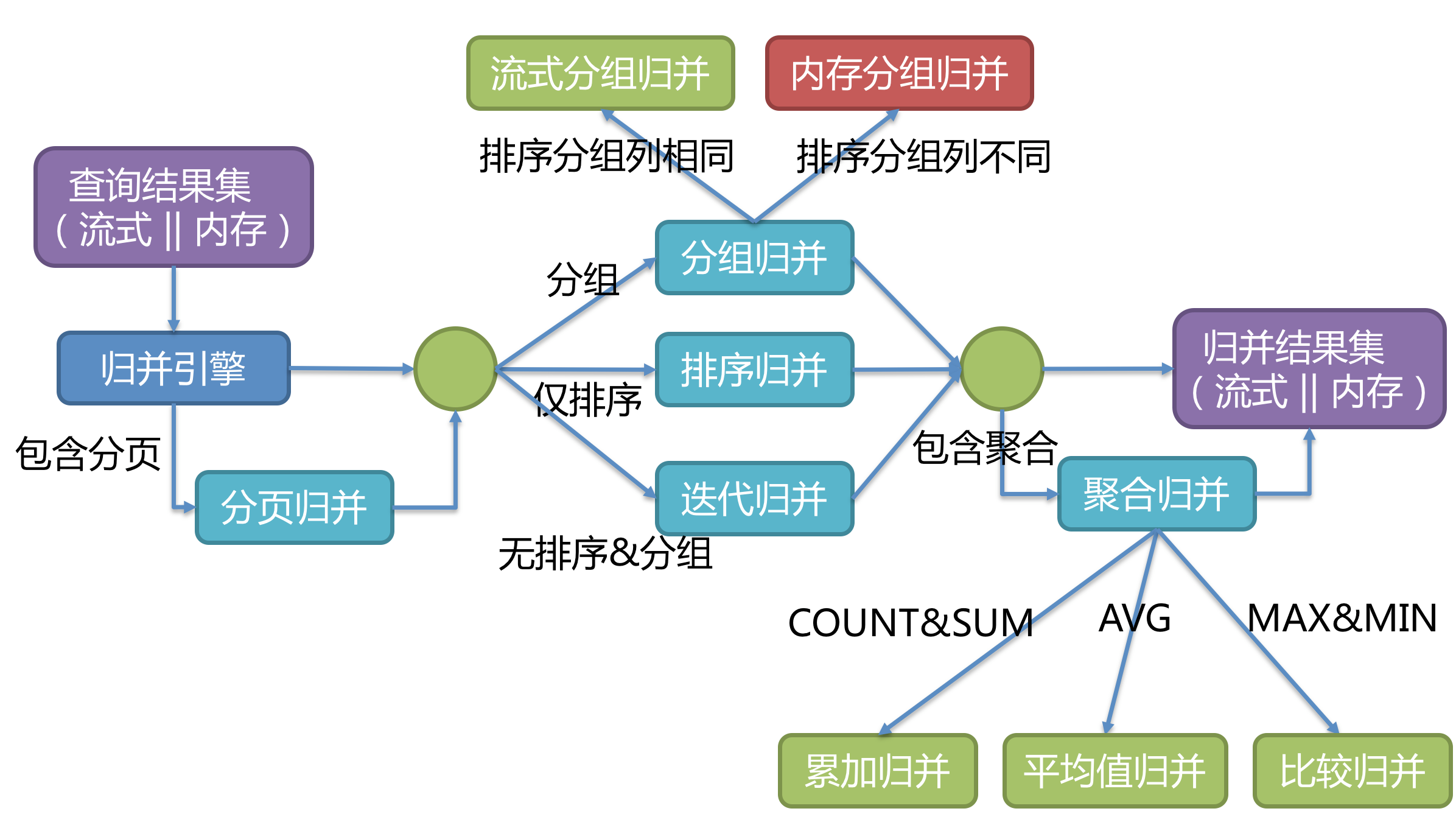
结果归并
将多个执行结果集归并以便于通过统一的 JDBC 接口输出。结果归并包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
解析引擎
解析过程分为词法解析和语法解析。词法解析用于将SQL拆解为不可再分的原子符号,称为Token。
并根据不同数据库方言锁提供的字典,将其归类为关键字、表达式、字面量和操作符。再使用语法
解析器将SQL转换为抽象语法树(简称AST,Abstract syntax Tree)。
例如对下面一条SQL语句:
select id,name from t_user where status='active' and age>18;
会被解析成下面这样一颗树:
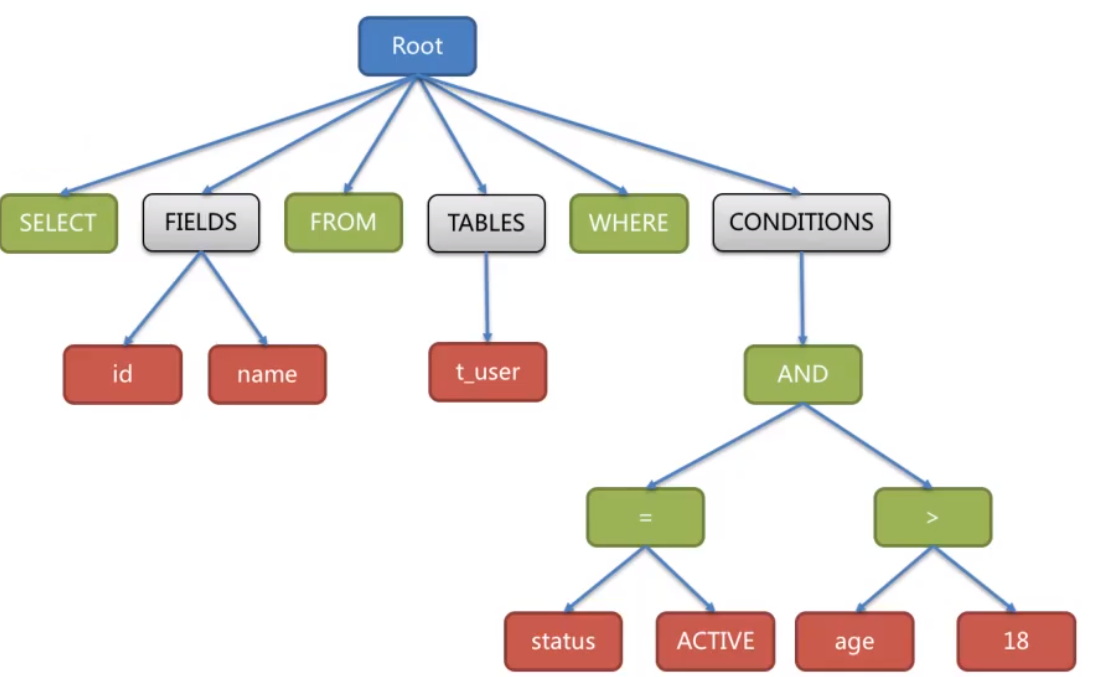
为了便于理解,抽闲语法树中的关键字的Token用绿色表示,变量的Token用红色表示,灰色表示需要进一步拆解。通过对抽象语法树的遍历,可以标记出所有可能需要改写的位置。SQL的一次解析过程是不可逆的,所有token按SQL原本的顺序依次进行解析,性能很高。并且在解析过程中,需要考虑各种数据库SQL方言的异同,提供不同的解析模板。
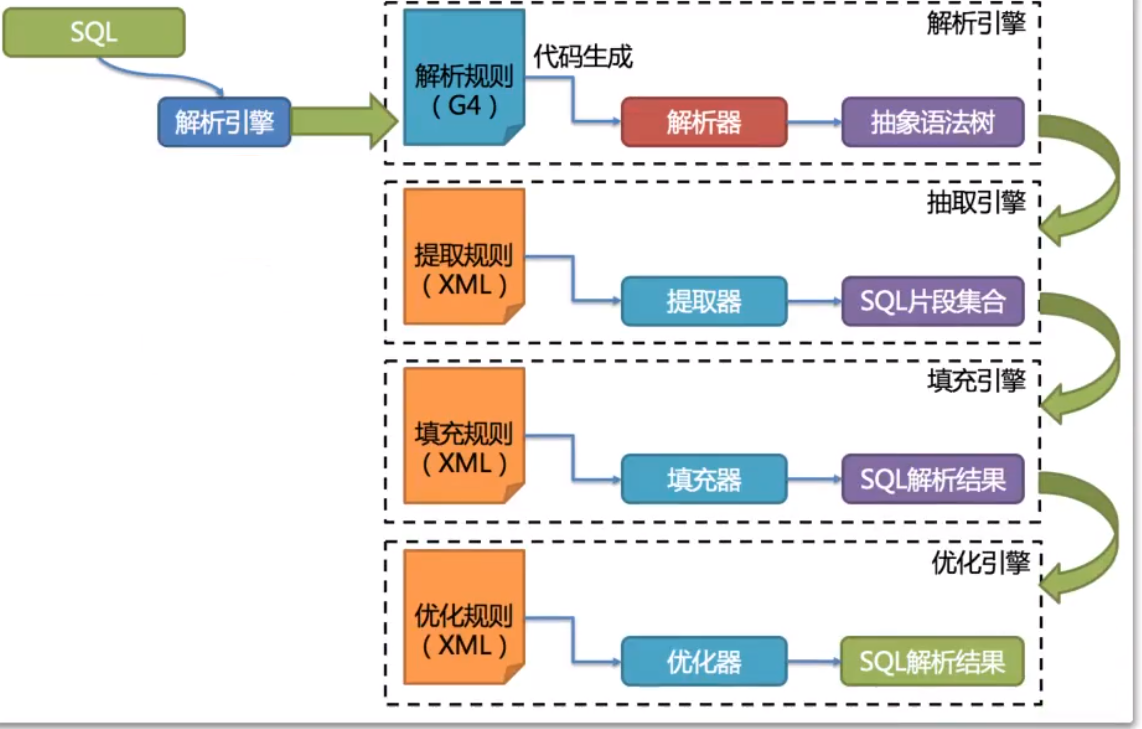
其中,SQL解析是整个分库分表产品的核心,其性能和兼容性是最重要的衡量指标、ShardingSphere在1.4.x之前采用的是性能较快的Druid作为SQL解析器。1.5.x版本后,采用自研的SQL解析器,针对分库分表场景,采取对SQL办理解的方式,提高SQL解析的性能和兼容性。然后从3.0.x版本后,开始使用ANTLR作为SQL解析引擎。这是个开源的SQL解析引擎,ShardingSphere在使用ANTLR时,还增加了一些AST的缓存功能。整堆ANLTR4的特性,官网建议尽量采用PreparedStatement的预编译方式来提高SQL执行的性能。
SQL解析整体结构:
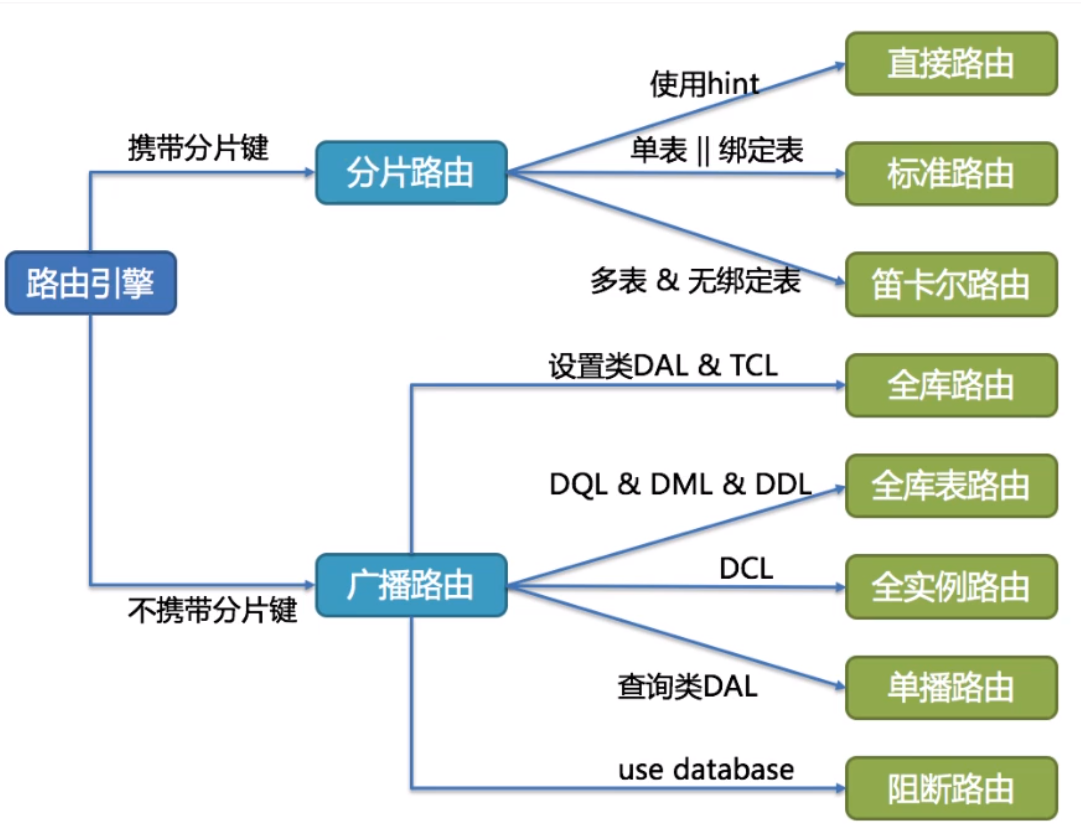
路由引擎
根据解析上下文匹配数据库和表分片策略,生成路由 路径。
ShardingSphere的分片策略主要分为单片路由(分片键的操作符是=)、多片路由(分片键的操作符是IN)和范围路由(分片键的操作符是Between)。不携带分片键的SQl则是广播路由。
分片策略通常可以由数据库内置也可有用户配置。内置的分片策略大致可以分为尾数取模、哈希、范围、标签、时间等。由用户配置的分片策略则更加灵活,可以根据使用需求定制分片策略。
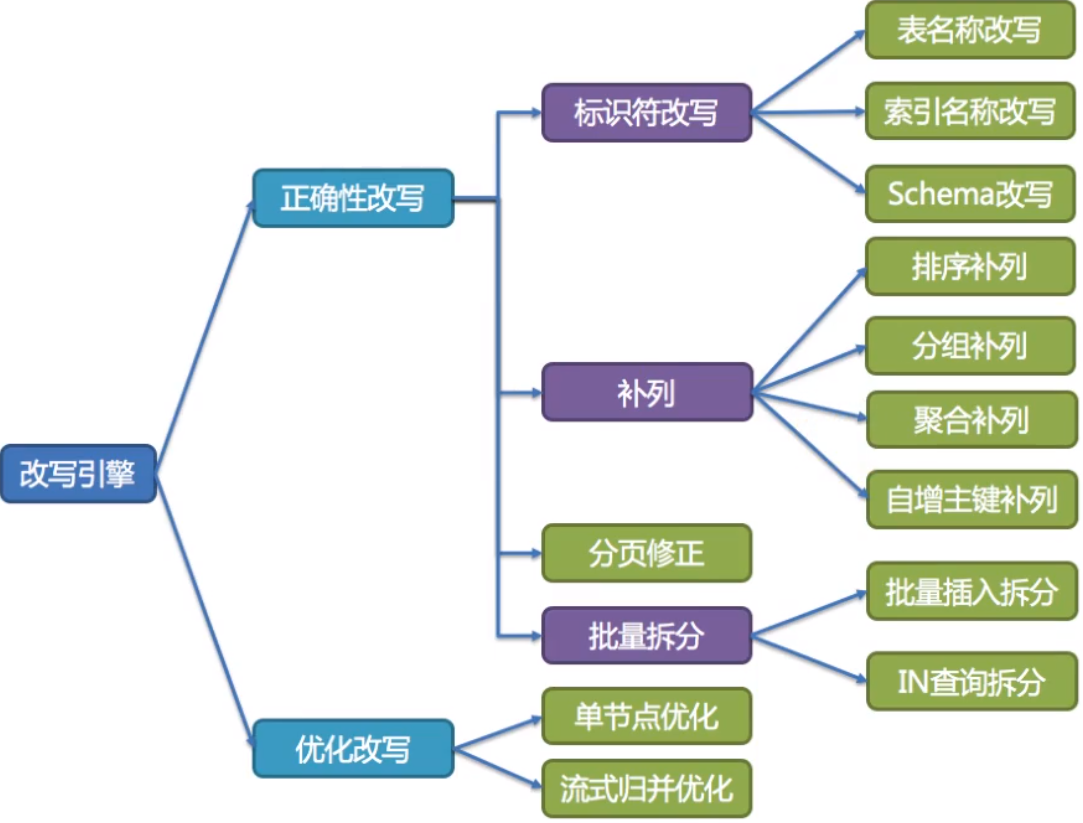
改写引擎
用户只需要面向逻辑库和逻辑表来写SQL,最终由ShardingSphere的改写引擎将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为正确性改写和优化改写。
执行引擎
ShardingSphere并不是简单的将改写完的SQl提交到数据库执行。执行引擎的目标是自动化的平衡资源控制和执行效率。
例如他的连接模式分为内存限制模式(MEMORY_STRICTLY)和连接限制模式(CONNECTION_STRICTLY)。内存限制模式只关注一个数据库连接的处理数量,通常一张真实表一个数据库连接。而连接限制模式则关注数据库连接的数量,较大的查询会进行串行操作。
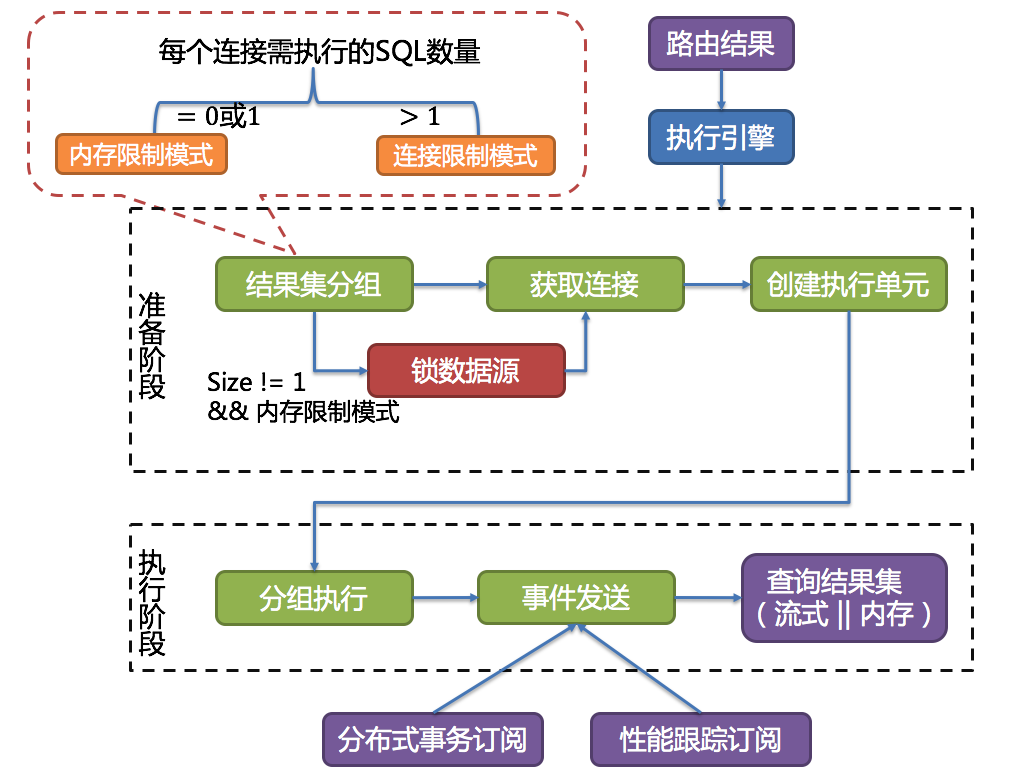
归并引擎
将从各个数据节点获取的多数据结果集,组合成为一个结果集并正确的返回至请求客户端,称为结果归并。
其中,流式归并是指一条一条数据的方式进行归并,而内存归并是将所有结果集都查询到内存中,进行统一归并。