9.1将Kafka 与其他数据源集成
对于第一个高级应用程序示例,假设你在金融服务公司工作。公司希望将其现有数据迁移到新技术实现的系统中,该计划包括使用 Kafka。数据迁移了一半,你被要求去更新公司的分析系统,其目的是实时显示最新的股票交易和与之关联的相关信息,对于这种应用场景 Kafka Streams非常适合。
公司专注于提供金融市场不同领域的基金,该公司将基金交易实时记录在关系型数据库中,同时他们计划最终将交易直接写入Kafka,但是在短期内,数据库依然是记录系统。
假设传入的数据被插入关系型数据库中,那么如何缩小数据库与新兴的
Kafka Streams应用程序之间的差距呢?答案是使用 Kafka Connect,它是 Apache Kafka的一部分,是将
Kafka与其他系统集成的框架。一旦 Kafka有数据,你将不再关心源数据的位置,而只需将 Kafka
Streams应用程序指向源主题,就像其他 Kafka Streams应用程序一样处理。
注意当使用 Kafka Connect从其他源获取数据时,集成点就是 Kafka的主题。这意味着任何使用Kafka Consumer的应用程序都可以使用导入的数据。
下图展示了数据库与 Kafka之间的集成是如何实现的。在本例中,将使用Kafka Connect来监控数据库表和流更新,并将它们写入 Kafka主题,该主题是金融分析应用程序的源。
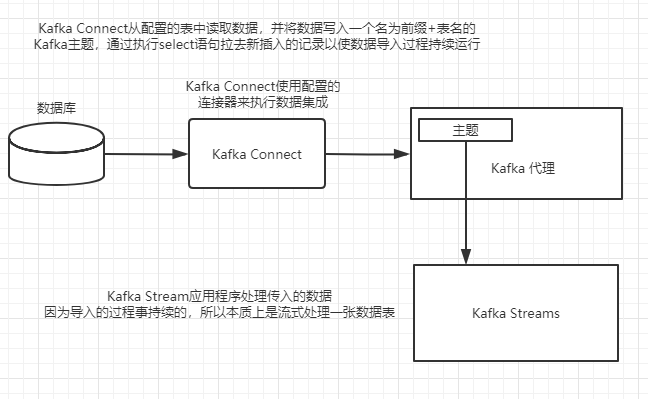
9.1.1使用Kafka Connect集成数据
Kafka Connect设计的目的是将数据从其他系统流入 Kafka,以及将数据从 Kafka流入另一个数据存储应用程序,例如 MongoDB或 Elasticsearch。使用 Kafka Connect可以将整个数据库导 Kafka,或者其他数据,如性能指标。
Kafka Connect使用特定的连接器与外部数据源交互,几种可用的连接器参考 Confluent官网。很多连接器都是由连接器社区开发的,使得 Kafka几乎可以与其他任何存储系统进行集成。如果没有你想要的连接器,那么你可以自己实现一个。

9.1.2配置 Connect
Kafka Connect有两种运行模式,即分布式模式和独立模式。对于大多数生产环境,以分布式模式运行是有意义的,因为当运行多个连接器实例时可以利用其并行性和容错性。这里,我们假设你在本机运行示例,因此所有的配置都是基于独立模式的。
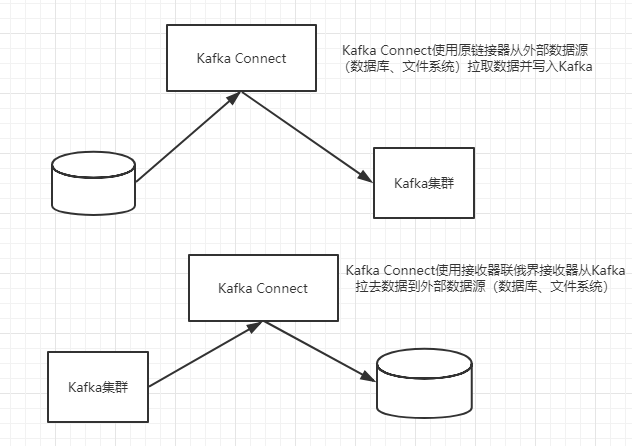
Kafka Connect用来与外部数据源交互的连接器有两种类型,即源连接器( source connector)和接收器连接器( sink connector)下图演示了 Kafka Connect如何使用这两种类型的连接器,正如所看到的,源连接器将数据写入 Kafka,而接收器连接器从 Kafka接收数据供其他系统使用。
对于本例,将使用 Kafka JDBC连接器。该连接器可以在 GitHub官网上找到,为了方便我将该连接器打包在源代码中。
使用Kafka Conecet时,你需要对Kafka Connect自身以及用于导入或导出数据的单个连接器做少量配置。首先,让我们来看一下要用到的 Kafka Connect的配置参数。
■bootstrap.servers——Kafka Connect使用的 Kafka代理列表,多个代理之间以逗号隔开。
■key.converter——类转换器,该转换器控制消息的键从 Kafka Connect格式到写人Kafka的格式的序列化。
■value.converter——类转换器,该转换器控制消息的值由 Kafka Connect格式到写Kafka的格式的序列化。例如,可以使用内置的org. apache. kafka. connect.json. JsonConverter。
■value.converter. schemas. enable——true或者 false,指定 Kafka Connect是否包含值的模式。对于本例,将其值设置为fase,在下一节再解释这样设置的原因。
■plugin.path——告诉Kafka Connect所使用的连接器及其依赖项的位置。此位置可以是单个、包含一个JAR文件或多个JAR文件的顶级目录。也可以提供多条路径,这些路径由逗号分隔的位置列表表示。
■offset. storage.file. filename——包含Kafka包含 Connect的消费者存储的偏移量的文件。还需要为JDBC连接器提供一些配置,这些配置参数说明如下。
■name——连接器的名称。
■connector. class——连接器的类。
■tasks.max——连接器使用的最大任务数。
■connection.url——用于连接数据库的URL
■mode——JDBC源连接器用于检测变化的方法。
■incrementing.column.name——被跟踪的用于检测变化的列名。
■topic.prefix——Kafka Connect将每张表的数据写入名为“topic. prefix+表名的主题。
这些配置中的大多数都很简单,但我们仍需要对这些配置中的mode和incrementing. column.name两个配置进行详细讨论,因为它们在连接器的运行中起着积极作用。JDBC源连接器使用mode配置项来检测需要加载哪些行。本示例中该配置项被设置为incrementing,它依赖于一个自增列,每次插入一条记录时该列的值加1。通过跟踪递增列,只拉取新插入的记录,更新操作将被忽略。你的 Kafka Streams应用程序只拉取最新的股票购买,因此这种设置是很理想的。配置项 incrementing. column.name是指包含自增值的列名。
提示本书的源代码包含 Kafka Connect和JDBC连接器的近乎完整的配置,配置文件位于本书源代码的src/main/resources目录下。你需要提供一些关于提取源代码资源库路径的信息,仔细阅读 README.md(点击进行下载)文件中的详细说明。
9.1.3转换数据
在获得这个任务之前,你已经使用类似的数据开发了一个 Kafka Streams应用程序,因此已经有了现成的模型和 Serde对象(底层使用Gson进行JSON的序列化与反序列化)。为了保持较快的开发速度,你不希望编写任何新的代码来支持使用 Kafka Connect。正如从下一节所看到的,你将能够从 Kafka Connect中无缝导入数据。
【提示:Gson是一个由谷歌 Apache公司开发的权库,用于将Java对象序列化为json以及将json反序列化为Java对象。你可以从用户指南中了解更多。】
为了实现这种无缝集成,需要对JDBC连接器的属性做一些较小的额外配置变更。在修改之前,让我们回顾一下9.1.2节介绍的配置项。具体来讲,在前面我说过使用org. apache.kafka.connect.kafka.connect.json.JsonConverter,并将模式禁用,值就会被转换为简单的JSON格式。
尽管JSON是你想在 Kafka Streams应用程序中使用的,但存在以下两个问题。
第一,当将数据转换为JSON格式时,列名将是转换后的JSON字符串字段的名称,这些名称都是BSE内部缩写的格式,在公司外部没有任何意义。因此当 Gson serde从JSON转换到期望的模型对象时,该对象的所有字段均为空,因为JSON字符串中的字段名与该对象的字段名不匹配。
第二,和预期一样,存储在数据库中的日期和时间是时间戳类型的,但是所提供的 Gson serde并没有为Date类型定义一个自定义的 TypeAdapte,因此所有日期都需要转换为格式类似 yyyy-dd'T':mm:ss.SS-0400的字符串。幸运的是, Kafka Connect提供了一种机制,能够很轻松地解决这两个问题。
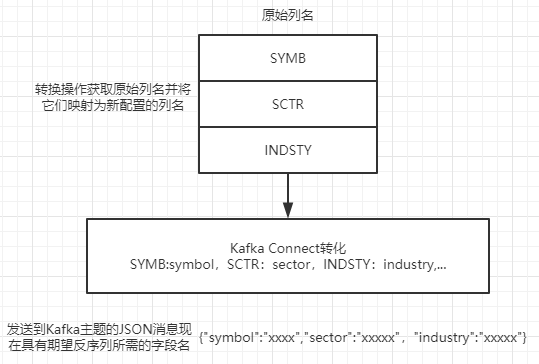
Kafka Connect有转换的设计思想,允许在 Kafka Connect将数据写入 Kafka之前对数据做一些轻量的转换。图9-3展示了这个转换过程发生的地方。
本示例中,将使用两个内置的转换操作类,即 TimestampConvert和 ReplaceField。如前所述,要使用这些转换类,需要在 connector-jdbc- properties配置文件中添加代码清单所示的几行配置
name=stock-transaction-connector
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:h2:tcp://localhost:9989/~/findata
mode=incrementing
incrementing.column.name=TXN_ID
topic.prefix=dbTxn
#类名转化器
transforms=ConvertDate,Rename
#日期转换器ConvertDate的别名类型
transforms.ConvertDate.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
#待转换日期字段
transforms.ConvertDate.field=TXNTS
#日期转换后输出的类型
transforms.ConvertDate.target.type=string
#日期的格式
transforms.ConvertDate.format=yyyy-MM-dd'T'HH:mm:ss.SSS-0400
#重命名转换器Rename的别名类型
transforms.Rename.type=org.apache.kafka.connect.transforms.ReplaceField$Value
#需要替换的列表名
transforms.Rename.renames=SMBL:symbol, SCTR:sector, INDSTY:industry, SHRS:shares, SHRPRC:sharePrice, CSTMRID:customerId, TXNTS:transactionTimestamp
这些属性是相对自描述性的,因此我们不必在它们上面花太多时间。如你所见,它们恰好提供了你需要 Kafka Streams应用程序提供的对于由 Kafka Connect和JDBC连接器导入 Kafka的消息成功进行反序列化。当所有 Kafka Connect组件就绪之后,要完成数据库表与 Kafka Streams应用程序的集成,只需使用具有 connector-c-jdbc.properties文件中指定的前缀的主题。
//StockTransaction对象的序列化和反序列化器 Serde<StockTransaction> stockTransactionSerde = StreamsSerdes.StockTransactionSerde(); //使用Kafka Connect写入记录的主题作为流的源 builder.stream("dbTxnTRANSACTIONS", Consumed.with(stringSerde, stockTransactionSerde)) //KStream<K,V> peek(ForeachAction<? super K,? super V> action)对KStream的每个记录执行一个操作。这是无状态逐记录操作 //此处将消息打印到控制台 .peek((k, v)-> LOG.info("transactions from database key {} value {}",k, v))
此时,你正在使用 Kafka Streams处理来自数据库表中的记录,但是还有更多的事情要做。你正在通过流式处理采集股票交易数据,为了分析这些交易数据,你需要按股票代码将交易数据进行分组。
我们已经知道了如何选择键并对记录重新分区,但如果记录在写入 Kafka时带有键则效率更高,因为Kafka Streams应用程序可以跳过重新分区的步骤,这就节省了处理时间和磁盘空间。让我们再回顾一下 Kafka Connect的配置。
首先,你可以添加一个 ValueToKey转换器,该转换器根据所指定的字段名列表从记录的值中提取相应字段,以用于键。更新 connector--dbc. properties文件内容如代码清单:
#增加ExtractKey转换器
transforms=ConvertDate,Rename,ExtractKey
transforms.ConvertDate.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.ConvertDate.field=TXNTS
transforms.ConvertDate.target.type=string
transforms.ConvertDate.format=yyyy-MM-dd'T'HH:mm:ss.SSS-0400
transforms.Rename.type=org.apache.kafka.connect.transforms.ReplaceField$Value
transforms.Rename.renames=SMBL:symbol, SCTR:sector, INDSTY:industry, SHRS:shares, SHRPRC:sharePrice, CSTMRID:customerId, TXNTS:transactionTimestamp
#指定ExtractKey转化器的类型
transforms.ExtractKey.type=org.apache.kafka.connect.transforms.ValueToKey
#流出需要抽取的字段别名以用作键的字段名
transforms.ExtractKey.fields=symbol
添加了一个别名为 ExtractKey的转换器并通知 Kafka Connect转换器对应的类名为ValueTokey.同时提供用于键的字段名为 symbol,它可以由多个以逗号分隔的值组成,但本例只需要提供一个值。注意,这里的字段名是原字段重命名之后的版本,因为这个转换器是在重命名转换器转换之后才执行的。
ExtractKey提取的字段结果是一个包含一个值的结构,但是你只想键对应的值即股票代码包括在结构中,为此可以添加一个FlattenStruct转换器将股票代码提取出来。
#增加最后一个转换器
transforms=ConvertDate,Rename,ExtractKey,FlattenStruct
transforms.ConvertDate.type=org.apache.kafka.connect.transforms.TimestampConverter$Value
transforms.ConvertDate.field=TXNTS
transforms.ConvertDate.target.type=string
transforms.ConvertDate.format=yyyy-MM-dd'T'HH:mm:ss.SSS-0400
transforms.Rename.type=org.apache.kafka.connect.transforms.ReplaceField$Value
transforms.Rename.renames=SMBL:symbol, SCTR:sector, INDSTY:industry, SHRS:shares, SHRPRC:sharePrice, CSTMRID:customerId, TXNTS:transactionTimestamp
transforms.ExtractKey.type=org.apache.kafka.connect.transforms.ValueToKey
transforms.ExtractKey.fields=symbol
#指定转换器对应的类
transforms.FlattenStruct.type=org.apache.kafka.connect.transforms.ExtractField$Key
#带抽取的字段名称
transforms.FlattenStruct.field=symbol
以上代码清单中添加了最后一个别名为FlattenStruct的转换器,并指定该转换器对应的类型为 ExtractFieldKey类,Kafka Connect使用该类来提取指定的字段,并且在结果中只包括该字段(在本例,该字段为键)。最后提供了字段名称,本例指定该名称为 symbol,和前一个转换器指定的字段一样,这样做是有意义的,因为这是用来创建键结构的字段。
只需要增加几行配置,就可以扩展之前的 Kafka Streams应用程序以执行更高级的操作,而无须选择键并执行重新分区的步骤,如代码:
//StockTransaction对象的序列化和反序列化器 Serde<StockTransaction> stockTransactionSerde = StreamsSerdes.StockTransactionSerde(); StreamsBuilder builder = new StreamsBuilder(); //使用Kafka Connect写入记录的主题作为流的源 builder.stream("dbTxnTRANSACTIONS",Consumed.with(stringSerde, stockTransactionSerde)) //KStream<K,V> peek(ForeachAction<? super K,? super V> action)对KStream的每个记录执行一个操作。这是无状态逐记录操作 //此处将消息打印到控制台 .peek((k, v)-> LOG.info("transactions from database key {} value {}",k, v)) //按键进行分组 .groupByKey(Serialized.with(stringSerde, stockTransactionSerde)) /* * KTable<K,VR> aggregate(Initializer<VR> initializer, Aggregator<? super K,? super V,VR> aggregator,Materialized<K,VR,KeyValueStore<org.apache.kafka.common.utils.Bytes,byte[]>> materialized)) * 通过分组键聚合此流中的记录值。具有空键或值的记录将被忽略。 * initializer-用于计算初始中间聚合结果的Initializer * aggregator-一个计算新聚合结果的聚合器,可用于实现诸如计数之类的聚合功能。 * Materialized-实例化的实例化,用于实例化状态存储。不能为null.with():使用提供的键和值Serdes实例化StateStore。 * * 在处理第一个输入记录之前,立即一次应用指定的Initializer,以提供用于处理第一个记录的初始中间聚合结果。指定的Aggregator将应用于每个输入记录,并使用当前聚合(或使用通过Initializer提供的中间聚合结果用于第一条记录)来计算新的聚合和记录的值。 * 因此,aggregate(Initializer,Aggregator,Materialized)可用于计算诸如count(c.f. count())之类的聚合函数。 */ .aggregate(()-> 0L,(symb, stockTxn, numShares) -> numShares + stockTxn.getShares(), Materialized.with(stringSerde, longSerde)).toStream() .peek((k,v) -> LOG.info("Aggregated stock sales for {} {}",k, v)) .to( "stock-counts", Produced.with(stringSerde, longSerde));
因为数据传入时就带有键,所以可以适用groupByKey,它不会设置自动重新分区的标志位。通过分组操作,可以直接进行一个聚合操作而无须重新分区。
9.2替代数据库
在第4章中,我们学习了如何向 Kafka Streams应用程序添加本地状态。流式应用程序需要使用状态来执行类似聚合、归约和连接的操作除非流式应用程序只处理单条记录,否则就需要本地状态。
根据第四章的需求的需求,我们已经开发了一个 Kafka Streams应用程序,它获取股票交易的3类信息:
■市场交易总额;
■客户每次购买股票的数量;
■在窗口大小为10秒的翻转窗口中,每支股票的总成交量。
到目前为止,在所有的示例中查看程序运行结果的方式有两种,一是通过控制台查看,二是从接收器主题中读取结果。在控制台查看数据适合开发环境,但控制台并不是展示结果的最佳方式。如果要做任何分析工作或者快速理解发生了什么,仪表板应用程序是最好的展现方式。
本节将会介绍如何在 Kafka Streams中使用交互式查询来开发一个用于查看分析结果的仪表板应用程序,而不需要关系型数据库来保存状态。直接将Kafka Streams作为数据流提供给仪表板应用程序。因此,仪表板应用程序中的数据自然会不断更新。
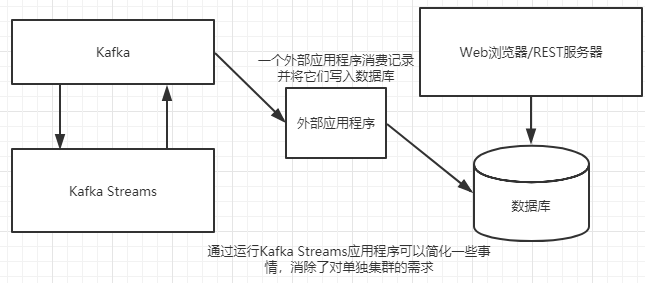
在一个典型的架构中,捕获和操作的数据会被推送到关系型数据库中以用于查看图9-4展示了这种架构:在使用 Kafka Streams之前,通过 Kafka摄取数据,并发送给一个分析引擎,然后分析引擎将处理结果写入数据库,以提供给仪表板应用程序使用。
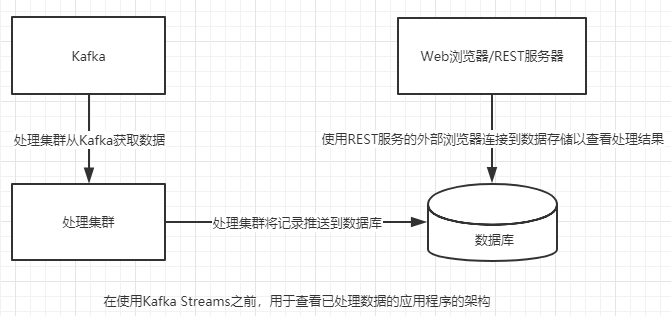
如果增加Kafka Streams使用本地状态,那么就要对上图架构进行修改,如下图所示删掉整个集群,可以显著简化架构。Kafka Streams依然将数据写回Kafka,并且数据库仍然是已转换数据的主要使用者
交互式查询可以让你直接查看状态存储中的数据,而不必先从Kafka中消费这些数据,换句话说流也成为数据,于是就有了以下调整。
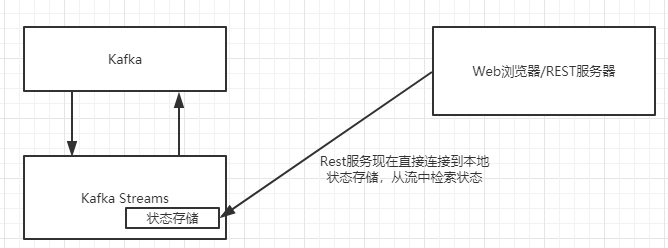
Kafka Streams通过REST风格接口从流式应用程序外部提供只读访问。值得重申的是这个构想是这么强大:你可以查看流的运行状态而不需要一个外部数据库。
9.2.1交互式查询工作原理
要使交互式查询生效,Kafka Streams需要在只读包装器中公开状态存储。重点是要理解:虽然 Kafka Streams让状态存储可以被查询,但并没有提供任何方式来更新和修改状态存储。 Kafka Streams通过Kafkastreams.store方法公开状态存储。
下面的代码片段是 store方法的使用示例:
ReadonlyWindowstore readonlystore = kafkastreams.store(storeName, Queryables.windowStore());
该示例检索一个 WindowStore, QueryablestoreTypes还提供另外两种类型的方法:
■QueryableStoreTypes.sessionStore();
■QueryableStoreTypes.keyValueStore();
一旦有了对只读状态存储的引用,只需要将该状态存储公开给一个提供给用户查询流数据状态的服务即可(例如一个REST风格的服务)但是检索状态存储只是整个构想的一部分,这里提取的状态存储将只包含本地存储中包含的键。
注意:请记住, Kafka Streams为每个任务分配一个状态存储,只要使用同一个应用程序ID, Kafka Streams应用程序就可以由多个实例组成。此外这些实例并不需要都位于同一台主机上。因此,有可能你查询到的状态存储仅包含所有键的一个子集,其他状态存储(具有相同名称,但位于其他机器上)可能包含键的另一个子集。
让我们使用前面列出的分析来明确这个构想。
9.2.2分配状态存储
先看看第一个分析,按市场板块聚合股票交易因为要进行聚合,所以状态存储将发挥作用。你希望公开状态存储,以提供每个市场板块成交量的实时视图,以深入了解目前市场哪个板块最活跃。股票市场活动产生大量的数据,但我们只讨论使用两个分区来保持示例的详细信息。另外,假设你在位于同一个数据中心的两台独立的机器上运行两个单线程实例,由于 Kafka Streams的自动负载均衡功能,每个应用程序将有一个任务来处理来自输入主题的每个分区的数据。
下图展示了任务与状态存储的分配情况。正如你所看到的,实例A处理分区0上的所有记录,而实例B处理分区1上的所有记录。
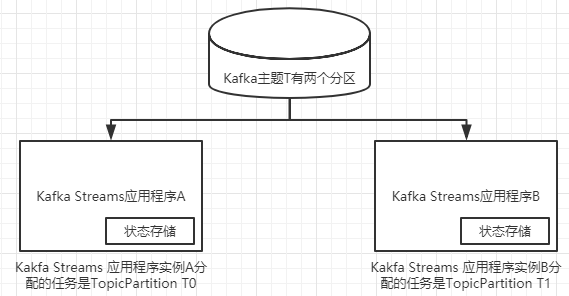
"Energy":100000"分配到实例A的状态存储中,"Finance":110000分配到实例B的状态存储中。回到为了查询而公开状态存储的示例,可以清楚地看到,如果将实例A上的状态存储公开给Web服务或任何外部查询,则只能检索到"Energy"键对应的值。
如何解决这个问题呢?你肯定不想建立一个单独的Web服务来查询每个实例—这种方式扩展性差。幸运的是你不必这样做, Kafka Streams提供了一种就像设置配置一样简单的解决方案。
9.2.3创建和查找分布式状态存储
若要启用交互式查询,需要设置 StreamsConfig. APPLICATION_SERVER_CONFIG参数,它包括 Kafka Streams应用程序的主机名及查询服务将要监听的端口,格式为 hostname:port。
当一个 Kafka Streams实例接收到给定键的查询时,需要找出该键是否被包含在本地状态存储中。更重要的是,如果在本地没找到,那么你希望找到哪个实例包含该键并查询该实例的状态存储。
KafkaStreams对象的几个方法允许检索由 APPLICATION_ SERVER_CONFIG定义的、具有相同应用程序ID所有运行实例的信息。表9-1列出了这些方法名及其描述。表9-1检索存储元数据的方法
|
方法名 |
参数 |
用途 |
|
allMetadata |
无参数 |
检索所有实例,有些可能是远程实例 |
|
allMetadataForstore |
存储的名称 |
检索包含指定存储的所有实例(有些是远程实例) |
|
allMetadataForKey |
键,Serializer |
检索包含有键存储的所有实例(有些是远程实例) |
|
allMetadataForKey |
键,StreamPartitioner |
检索包含有键存储的所有实例(有些是远程实例) |
可以使用 KafkaStreams.allMetadata方法获取有资格进行交互式查询的所有实例的信息。KafkaStreams.allMetadataForKey方法是我在写交互式查询时最常用的方法。
接下来,让我们再看一下键/值在 Kafka Streams实例中的分布,增加了检查键"Finance"过程的顺序,该键从另一个实例找到并返回。每一个Kafka Streams实例都内置一个轻量的服务器,监听 APPLICATION_ SERVERCONFIG中指定的端口。
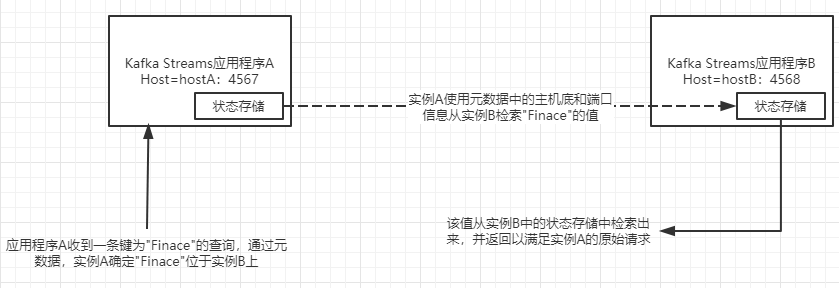
需要重点指出的是:你只需要查询 Kafka Streams某一个实例,至于查询哪一个实例并不重要(前提是你已经正确配置了应用程序)通过使用RPC机制和元数据检索方法,如果查询的实例不包含待查询的数据,则该实例会找到数据所在的位置,并提取结果,然后将结果返回给原始查询
通过跟踪上图中的调用流,你可以在实际操作中看到这一点。实例A并不包含键“Finance”,但发现实例B包含该键,因此,实例A向实例B内置的服务器发起一次方法调用,该方法检素数据并将结果返回给原始的查询。
9.2.4编写交互式查询
public static void main(String[] args) { if(args.length < 2){ LOG.error("Need to specify host, port"); System.exit(1); } String host = args[0]; int port = Integer.parseInt(args[1]); final HostInfo hostInfo = new HostInfo(host, port); Properties properties = getProperties(); properties.put(StreamsConfig.APPLICATION_SERVER_CONFIG, host+":"+port);
现在需要提供两个参数(主机名和端口),但这种更改影响微乎其微。你还可以嵌入本地服务器执行查询:对于这个实现,我选择Spark Web服务器。当然,如果你不喜欢Spark Web服务器,请随意替换为另一个Web服务器
现在,让我们看一下嵌入Spark服务器的代码:
KafkaStreams kafkaStreams = new KafkaStreams(builder.build(), streamsConfig); InteractiveQueryServer queryServer = new InteractiveQueryServer(kafkaStreams, hostInfo); StateRestoreHttpReporter restoreReporter = new StateRestoreHttpReporter(queryServer); queryServer.init(); kafkaStreams.setGlobalStateRestoreListener(restoreReporter); kafkaStreams.setStateListener(((newState, oldState) -> { if (newState == KafkaStreams.State.RUNNING && oldState == KafkaStreams.State.REBALANCING) { LOG.info("Setting the query server to ready"); queryServer.setReady(true); } else if (newState != KafkaStreams.State.RUNNING) { LOG.info("State not RUNNING, disabling the query server"); queryServer.setReady(false); } })); kafkaStreams.setUncaughtExceptionHandler((t, e) -> { LOG.error("Thread {} had a fatal error {}", t, e, e); shutdown(kafkaStreams, queryServer); }); Runtime.getRuntime().addShutdownHook(new Thread(() -> { shutdown(kafkaStreams, queryServer); })); LOG.info("Stock Analysis KStream Interactive Query App Started"); kafkaStreams.cleanUp(); kafkaStreams.start(); }
在这段代码中,创建了一个InteractiveQueryServer实例,它是一个包装类,包含Spark Web服务器和管理Web服务调用以及启动和停止Web服务器的代码。
第7章讨论过使用状态监听器来通知一个 Kafka Streams应用程序的各种状态,在这里可以看到这个监听器的有效使用。回想一下,当在运行交互式查询时,需要使用 Streams Metadata实例来确定给定键的数据是否是正在处理查询的实例的本地数据。将查询服务器的状态设置为true,仅当在应用程序处于运行状态时才允许访问所需要的元数据。
要记住的一个关键点是返回的元数据是由 Kafka Streams应用程序组成的快照。在任何时候,你都可以伸缩应用程序。当这种情况发生时(或者,在其他任何合格事件发生时,如通过正则表达式来添加源节点的主题), Kafka Streams应用程序经历再平衡阶段,可能会更改分区的分配。在本示例中,只有处于运行状态时才允许查询,但可以随意使用任何你认为合适的策略。
接下来是第7章中涉及的另一个例子:设置一个未捕获的异常处理器。在本示例中,将记录错误并关闭应用程序和查询服务器。因为这个应用程序无限期地运行,所以添加一个关闭钩子用来当停止示例时关闭所有程序。