6.1章节内容
了解如何使用处理器API对以下场景进行处理
①以有规律的间隔定期执行
②将控制记录如何向下游发送
③将记录转发给特定的子节点
④创建Kafka Streams API中不存在的功能
6.2使用源处理器和接收器创建一个拓扑
场景:假如你是啤酒厂的老板,最近要拓展业务,接受经销商的在线订单,分别是国内销售业务和国外销售业务。你想根据订单是国内还是国际分配订单,把所有的销售额从英镑、美元转化成人名币。

6.2.1添加一个源节点
String purchaseProcessor = "purchase-processor";
/* * Topology是ProcessorTopology的逻辑表示。拓扑是源,处理器和接收器的非循环图。 * 源是图中的一个节点,它使用一个或多个Kafka主题并将其转发到其后继节点. * 处理器是图形中的一个节点,它从上游节点接收输入记录,处理这些记录,并有选择地将新记录转发到其一个或所有下游节点. * 最后,接收器是图形中的一个节点,用于接收来自上游节点的记录并将其写入Kafka主题。 * 拓扑允许您构造这些节点的非循环图,然后传递到新的KafkaStreams实例中,然后开始使用,处理和生成记录 */ Topology toplogy = new Topology();
//指purchassSourceNodeName为此源节点名称 toplogy.addSource(LATEST, purchaseSourceNodeName,
//指定源使用的时间戳提取器 new UsePreviousTimeOnInvalidTimestamp(),
//指定序列化器 stringDeserializer,
//指定反序列化器 beerPurchaseDeserializer,
//指定源节点数据来源的主题名称 Topics.POPS_HOPS_PURCHASES.topicName());
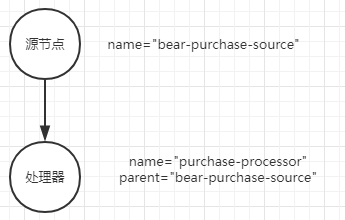
在 topology. addsource()方法中有几个参数在DSL中不会用到。首先是源节点名称,在使用 Kafka Streams DSL时不需要传递名称,因为 KStream实例会为节点生成一个名称。但是当你使用处理器API时,你需要提供节点在拓扑中的名称,节点名称用于将子节点连接到父节点。
然后,指定源使用的时间戳提取器。在4.5.1节,我们介绍了每个流的源可以使用的时间戳提取器。本例使用的是 UserPreviousTimeOnInvalidTimesta类,该应用程序所有其他的源将使用默认的 FailOnInvalidTimestamp类。
接着,提供了键和值的反序列化器,这是与 Kafka Streams DSL另一个不同的地方。在DSL中,当创建源节点或接收器节点时提供 Serde实例, Serde本身包括了序列化器与反序列化器,Kafka Streams DSL会适当选取其中之一,这取决于是从对象到字节数组,还是从字节数组到对象。因为处理器API是低阶的抽象,所以在创建源节点时直接提供反序列化器,在创建接收器节点时直接提供序列化器。最后,提供了源主题的名称。接下来,让我们看看如何处理传入应用程序的购买记录。
6.2.2添加一个处理器
这段代码使用连贯接口模式来构建拓扑,与 Kafka Streams API的不同之处在于返回类型。对于 Kafka Streams API而言,对 KStream运算符的每一次调用都返回一个新的 KStream或 KTable实例。在处理器API中,每次调用 Topology都返回同一个实例。
topology. addProcessor方法的第二个参数接受一个 ProcessorSupplier接口的实例,但是由于ProcessorSupplier是一个单方法接口因此可以使用 lambda表达式替换它。
本节的关键点是 addProcessor()方法的第三个参数 purchaseSourceNodeName,该参数与 addSource()方法的第二个参数是同一个对象,这就建立了节点间的父子关系,如上图相应地父子关系又决定了在一个 Kafka Streams应用程序中记录如何从一个处理器移动所示到下一个处理器。
BeerPurchaseProcessor beerProcessor = new BeerPurchaseProcessor(domesticSalesSink, internationalSalesSink);
String purchaseSourceNodeName = "beer-purchase-source";
toplogy.addSource(LATEST, purchaseSourceNodeName, new UsePreviousTimeOnInvalidTimestamp(), stringDeserializer, beerPurchaseDeserializer, Topics.POPS_HOPS_PURCHASES.topicName()) /** * Topology addProcessor(String name,ProcessorSupplier supplier,String parentNames) * name-处理器节点的唯一名称 * supplier-用于获取此节点的处理器实例的提供者 * parentNames-该处理器应接收并处理其输出记录的一个或多个源节点或处理器节点的名称 */ .addProcessor(purchaseProcessor, () -> beerProcessor, purchaseSourceNodeName);
现在让我们开始讨论代码代码与6.2.2同块代码中的BeerPurchaseProcessor处理器,该处理器有两个职责:
▶将国际销售额换算成人民币
▶根据销售的来源(国内或国外),将记录路由到相应的接收器节点
此代码逻辑如下:检查货币类型如发现不是则换算成人名币;如不是国内销售则更新记录转发到“insternational-sales”主题中;否则直接将记录转发到“domestic-sales”主题中
public class BeerPurchaseProcessor extends AbstractProcessor<String, BeerPurchase> { private String domesticSalesNode; private String internationalSalesNode; //为记录要转发到不同节点设置名称 public BeerPurchaseProcessor(String domesticSalesNode, String internationalSalesNode) { this.domesticSalesNode = domesticSalesNode; this.internationalSalesNode = internationalSalesNode; } //process()方法实现的地方 @Override public void process(String key, BeerPurchase beerPurchase) { Currency transactionCurrency = beerPurchase.getCurrency(); if (transactionCurrency != DOLLARS) { BeerPurchase dollarBeerPurchase; BeerPurchase.Builder builder = BeerPurchase.newBuilder(beerPurchase); double internationalSaleAmount = beerPurchase.getTotalSale(); String pattern = "###.##"; DecimalFormat decimalFormat = new DecimalFormat(pattern); builder.currency(DOLLARS); builder.totalSale(Double.parseDouble(decimalFormat.format(transactionCurrency.convertToDollars(internationalSaleAmount))));//货币换算 dollarBeerPurchase = builder.build();
//使用ProcessorContext(由context()方法返回的对象),并将记录转发到国际销售的子节点 context().forward(key, dollarBeerPurchase, internationalSalesNode); } else {
//使用ProcessorContext(由context()方法返回的对象),并将记录转发到国内销售的子节点 context().forward(key, beerPurchase, domesticSalesNode); } } }
本示例扩展了 Abstract Processor类,该类覆盖了 Processor接口方法中除 process()方法之外的其他方法。 Processor. process()方法就是当记录流经拓扑时执行操作的地方。
注意 Processor接口提供了init()、 process()、 punctuate()和 close()方法,Processor是流式应用程序中对记录进行任何逻辑处理的主要驱动。在示例中,大多会使用AbstractProcessor类,因此只需要覆盖该类中你所需要的方法。 AbstractProcessor类实例化了 ProcessorContext,因此如果你不需要在类中做其他设置的话,那么就不必重写init()方法。
代码中最后几行代码展示了本示例的要点—将记录转发到特定子节点的能力。代码中的 context()方法为本处理器检索 ProcessorContext对象的一个引用。一个拓扑中的所有处理器都通过init()方法接收 ProcessorContext的一个引用,当实例化拓扑时StreamTask会执行此方法。
6.2.3增加一个接收器节点
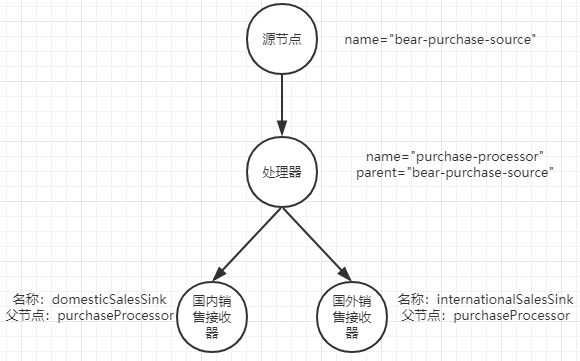
在代码以下代码中增加了两个接收器节点,一个用于人名币,另一个用于美元。根据交易的货币类型,将记录写入相应的主题中。在增加两个接收器节点时需要重点注意的是两者具有相同的父节点名称。通过向两个接收器节点提供相同的父节点名称,就可以将它们连接到处理器(如上图所示)。
在第一个示例中,已经看到了如何将拓扑连接在一起,并将记录发送到特定的子节点。尽管处理器API比 Kafka Streams API要稍微复杂一点,但是依然很容易构建拓扑。下一个示例将探索处理器API提供的更多灵活性操作。
toplogy.addSource(LATEST, purchaseSourceNodeName, new UsePreviousTimeOnInvalidTimestamp(), stringDeserializer, beerPurchaseDeserializer, Topics.POPS_HOPS_PURCHASES.topicName()) .addProcessor(purchaseProcessor, () -> beerProcessor, purchaseSourceNodeName); toplogy.addProcessor(domesticSalesSink, new KStreamPrinter("domestic-sales"), purchaseProcessor ); toplogy.addProcessor(internationalSalesSink, new KStreamPrinter("international-sales"), purchaseProcessor );
6.3通过股票分析处理器深入研究处理API
在下面时需求列表:
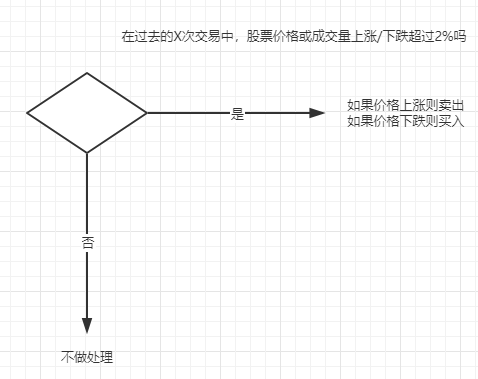
▶显示股票当前价值
▶指出每股价格的趋势是上涨还是下跌
▶目前位置股票总量以及其趋势是上升还是下降
▶只向下游发送股票价格趋势显示为2%的记录
▶在执行任何计算之前,收集给定股票的至少20个样本
6.3.1股票表现处理器应用程序
Topology topology = new Topology(); String stocksStateStore = "stock-performance-store"; double differentialThreshold = 0.02; //创建一个基于内存的键/值状态存储 KeyValueBytesStoreSupplier storeSupplier = Stores.inMemoryKeyValueStore(stocksStateStore); /** * KeyValueStore:一个支持放置/获取/删除和范围查询的键值存储。其继承于StateStore:用于管理由流处理器维护的状态的存储引擎。 * StoreBuilder<T extends StateStore>:构建一个包含可选的缓存和日志记录的StateStore。 */ StoreBuilder<KeyValueStore<String, StockPerformance>> storeBuilder = Stores.keyValueStoreBuilder(storeSupplier, Serdes.String(), stockPerformanceSerde); topology.addSource("stocks-source", stringDeserializer, stockTransactionDeserializer,"stock-transactions") /** * Topology addProcessor(String name,ProcessorSupplier supplier,String parentNames) * name-处理器节点的唯一名称 * supplier-用于获取此节点的处理器实例的提供者 * parentNames-该处理器应接收并处理其输出记录的一个或多个源节点或处理器节点的名称 */ .addProcessor("stocks-processor", () -> new StockPerformanceProcessor(stocksStateStore, differentialThreshold), "stocks-source") /** * Topology addStateStore(StoreBuilder storeBuilder,processorNames): * storeBuilder-用于获取此状态存储StateState实例的storeBuilder * processorNames-应该能够访问提供的存储的处理器的名称 */ .addStateStore(storeBuilder,"stocks-processor")
/** * public Topology addSink(String name,String topic,StreamPartitioner partitioner,String parentNames) * name-接收器的唯一名称 * topic-此接收器应向其写入记录的Kafka主题的名称 * partitioner-用于确定接收器处理的每个记录的分区的函数 * parentNames—一个或多个源节点或处理器节点的名称,此接收器应使用这些节点并将其输出记录写入其主题 */
.addSink("stocks-sink", "stock-performance", stringSerializer, stockPerformanceSerializer, "stocks-processor");
此拓扑与前面示例具有相同的流程,因此我们仅关注处理器中的新特性。在前面的示例中,不需要做任何设置操作,而是依赖 AbstractProcessor.init方法来初始化 ProcessorContext对象。然而,在本示例中,需要使用状态存储,而且也想定时发送记录,而不是在每次接收到消息时就进行转发。
public class StockPerformanceProcessor extends AbstractProcessor<String, StockTransaction> { private KeyValueStore<String, StockPerformance> keyValueStore; private String stateStoreName; private double differentialThreshold; public StockPerformanceProcessor(String stateStoreName, double differentialThreshold) { this.stateStoreName = stateStoreName; this.differentialThreshold = differentialThreshold; } @SuppressWarnings("unchecked") @Override public void init(ProcessorContext processorContext) { super.init(processorContext); keyValueStore = (KeyValueStore) context().getStateStore(stateStoreName); StockPerformanceP63unctuator punctuator = new StockPerformancePunctuator(differentialThreshold, context(), keyValueStore); /** * ProcessorContext context()在初始化期间获取处理器的上下文集。 * context的方法Cancellable schedule(long interval,PunctuationType type,Punctuator callback) * schedule作用:安排处理器的定期操作。 * interval:时间间隔 * PunctuationType.WALL_CLOCK_TIME-使用系统时间(挂钟时间),该时间以轮询间隔为前提,与是否收到新消息无关。注意:这是尽力而为的,因为它的粒度受处理循环的迭代完成需要多长时间限制 * Punctuator callback-一种使用时间戳的函数,表示当前流或系统时间 * contextcontext().schedule(10000, PunctuationType.WALL_CLOCK_TIME, punctuator)在这里是每10秒执行一次punctuator方法 */ context().schedule(10000, PunctuationType.WALL_CLOCK_TIME, punctuator); } @Override public void process(String symbol, StockTransaction transaction) { if (symbol != null) { StockPerformance stockPerformance = keyValueStore.get(symbol); if (stockPerformance == null) { stockPerformance = new StockPerformance(); } stockPerformance.updatePriceStats(transaction.getSharePrice()); stockPerformance.updateVolumeStats(transaction.getShares()); stockPerformance.setLastUpdateSent(Instant.now()); keyValueStore.put(symbol, stockPerformance); } } }
6.3.2process()方法
process()使用给定的键和值处理记录。在6.3.1中代码里的 process()方法是执行所有计算用来评估股票表现的地方。当收到一条记录时,需要执行以下步骤。
(1)检查状态存储,查看是否有与记录中的股票代码对应的 StockPerformance对象。
(2)如果状态存储中不存在对应的StockPerforr对象,则创建一个新对象。然后该对象的实例加入当前股票价格和股票成交量,并更新相应的计算。
在代码6.2.1处理器实例中,一旦使用了process()方法,就会将记录转发给下游,而在6.3.1中会将最终结果存储在状态存储中,并将记录转发留给Punctuator.punctuate方法处理。
6.4组合处理器
现在,假设你想做一个类似的分析,但不是按键使用一对一连接,而是使用由共同键关联的两个数据集合,即一个数据组合。假设你是一个很受欢迎的日间在线交易应用程序的经理,日间交易员一天要使用该应用程序好几个小时,有时整个交易市场开放时间都在使用。应用程序跟踪的指标之一是事件的意图。你已将事件定义为用户点击股票代码以阅读更多关于公司及其财务前景的信息。你想对应用程序中这些用户点击信息及用户购买股票之间的关系进行更深入的分析。你想得到一些粗粒度的结果,通过比较多次点击与购买以确定一些总体模式。你所需要的是一个元组,该元组包括按公司交易代码划分的每个事件类型的两个集合,如下所示。
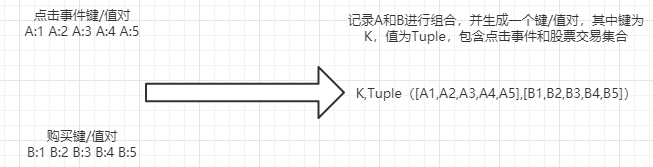
你的目标是将给定公司的点击事件的快照和股票交易的快照结合在一起,每N秒执行一次,但无须等待来自任何一条流的记录到达。当达到指定时间时,你需要按公司股票代码对点击事件和股票交易进行组合。如果其中一个类型的事件不存在,那么元组中与之对应的集合为空。
6.4.1构建组合处理器
要创建组合处理器,你需要将一些片段连接在一起。
(1)定义两个主题(stock-transactions和 events)
(2)增加两个从第1步定义的两个主题消费数据的处理器。
(3)增加第3个处理器用于对先前两个处理器进行聚合或组合操作。
(4)为第3步添加的聚合处理器增加一个状态存储,用于追踪两个事件的状态。
(5)增加一个接收器节点用于将结果输出(也可以增加一个打印处理器将结果打印到控制台)
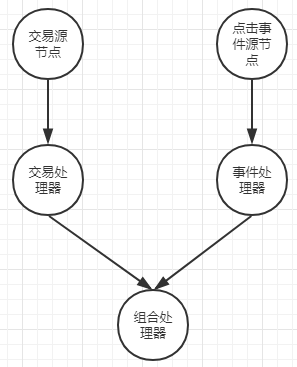
构建源节点:
topology.addSource("Txn-Source", stringDeserializer, stockTransactionDeserializer, "stock-transactions")
.addSource("Events-Source", stringDeserializer, clickEventDeserializer, "events");
增加处理器:
topology.addSource("Txn-Source", stringDeserializer, stockTransactionDeserializer, "stock-transactions")
.addSource("Events-Source", stringDeserializer, clickEventDeserializer, "events")
.addProcessor("Txn-Processor", StockTransactionProcessor::new, "Txn-Source")
.addProcessor("Events-Processor", ClickEventProcessor::new, "Events-Source")
.addProcessor("CoGrouping-Processor", CogroupingProcessor::new, "Txn-Processor", "Events-Processor");
在以上代码中,第三个处理器同时存在拥有作为父节点的两个处理器的名称,这意味着两个处理器将为聚合处理器提供消息。
股票交易处理器:
public class StockTransactionProcessor extends AbstractProcessor<String, StockTransaction> { @Override @SuppressWarnings("unchecked") public void init(ProcessorContext context) { super.init(context); } @Override public void process(String key, StockTransaction value) { if (key != null) { Tuple<ClickEvent,StockTransaction> tuple = Tuple.of(null, value); context().forward(key, tuple);//将元组交给组合处理器 } } }
正如你所看到的,股票交易处理器将StockTransaction对象添加到聚合器中,并转发记录。
点击事件处理器:
public class ClickEventProcessor extends AbstractProcessor<String, ClickEvent> { @Override @SuppressWarnings("unchecked") public void init(ProcessorContext context) { super.init(context); } @Override public void process(String key, ClickEvent clickEvent) { if (key != null) { Tuple<ClickEvent, StockTransaction> tuple = Tuple.of(clickEvent, null); context().forward(key, tuple);//将元组交给组合处理器 } } }
为了聚合操作拓扑图的完整性,我们需要看下组合处理器的代码。
public class CogroupingProcessor extends AbstractProcessor<String, Tuple<ClickEvent,StockTransaction>> { private KeyValueStore<String, Tuple<List<ClickEvent>,List<StockTransaction>>> tupleStore; public static final String TUPLE_STORE_NAME = "tupleCoGroupStore"; @Override @SuppressWarnings("unchecked") public void init(ProcessorContext context) { super.init(context); /** * context().getStateStore(TUPLE_STORE_NAME):根据名称获取提供者状态。 */ tupleStore = (KeyValueStore) context().getStateStore(TUPLE_STORE_NAME); CogroupingPunctuator punctuator = new CogroupingPunctuator(tupleStore, context());//创建一个Punctuator实例,他负责处理所有的定时调度 context().schedule(15000L, STREAM_TIME, punctuator); } //使用给定的键和值处理记录 @Override public void process(String key, Tuple<ClickEvent, StockTransaction> value) { Tuple<List<ClickEvent>, List<StockTransaction>> cogroupedTuple = tupleStore.get(key); if (cogroupedTuple == null) { cogroupedTuple = Tuple.of(new ArrayList<>(), new ArrayList<>()); } if(value._1 != null) { cogroupedTuple._1.add(value._1); } if(value._2 != null) { cogroupedTuple._2.add(value._2); } tupleStore.put(key, cogroupedTuple); } }
正如你所看到的那样,init()方法处理类初始化设置细节,获取在著应用程序中的配置状态储存,并将其保存在一个变量中以便稍后使用,以及创建CogroupingPunctuator用来处理预定punctuator调用。
提示:有两种时间类型选择,即PunctuateType. STREAM TIME和 Punctuation.WALL_CLOCK_TIME。
STREAM_TIME -使用“流时间”,它是根据使用中的TimestampExtractor提取的时间戳通过消息处理来提前的。注意:只有消息到达时才进行高级处理 。
WALL_CLOCK_TIME-使用系统时间(挂钟时间),该时间按轮询间隔提前(StreamsConfig.POLL_MS_配置)独立于是否有新消息到达。注意:这只是因为它的粒度受到处理循环的迭代完成所需时间的限制。
6.4.2添加状态存储节点
//相关日志主题配置,指定保存时长并使用压缩和删除的策略机制 Map<String, String> changeLogConfigs = new HashMap<>(); changeLogConfigs.put("retention.ms", "120000"); changeLogConfigs.put("cleanup.policy", "compact,delete"); /** * KeyValueBytesStoreSupplier:一种存储提供者,可用于创建一个或多个类型为<Byte,byte []>的KeyValueStore实例。 * Stores.persistentKeyValueStore:创建一个持久性KeyValueBytesStoreSupplier的实例,该实例可用于构建内存中的存储。 */ KeyValueBytesStoreSupplier storeSupplier = Stores.persistentKeyValueStore(TUPLE_STORE_NAME); //创建存储构建器 StoreBuilder<KeyValueStore<String, Tuple<List<ClickEvent>, List<StockTransaction>>>> storeBuilder = /** * Stores.keyValueStoreBuilder(KeyValueBytesStoreSupplier supplier,Serde<K> keySerde,Serde<V> valueSerde): * keyValueStoreBuilder用于创建一个StoreBuilder,然后将其用于构建KeyValueStore【一个支持放置/获取/删除和范围查询的键值存储】 * StoreBuilder:构建一个包含可选缓存和日志记录的StateStore【用于管理由流处理器维护的状态的存储引擎】 * StoreBuilder<T> withLoggingEnabled(Map<String,String>config):维护对存储所做的任何更改的更改日志。使用提供的配置来设置更改日志主题的配置。 */ Stores.keyValueStoreBuilder(storeSupplier, Serdes.String(), eventPerformanceTuple).withLoggingEnabled(changeLogConfigs); //将存储添加到拓扑中,并指定将要访问该存储的处理器名称 topology.addStateStore(storeBuilder, "CoGrouping-Processor")
这段代码很简单,但需要注意一点:组合处理器被指定为唯一可以访问这个状态的存储的处理器。而持久的状态存储之所以具备持久性是因为你可能对一些键进行更新,对于基于内存和最近最少使用算法的存储,不常用的键和值可能最终被删除。
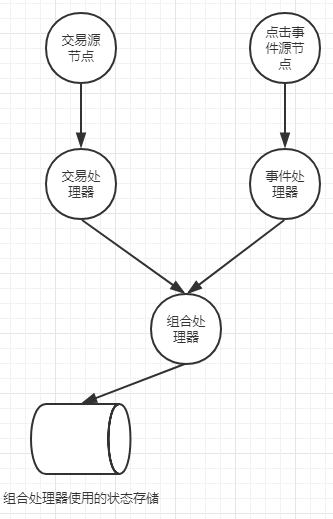
6.4.3添加接收器节点
若使用组合拓扑,则需要将数据写入主题(或者是控制台),现在让我们更新新拓扑:
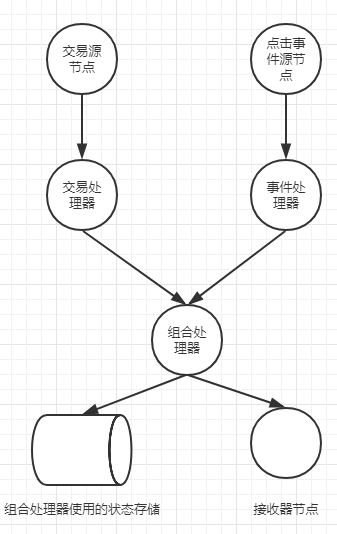
接收器节点和打印处理器:
//接收器节点将组合处理器的元组写入一个主题中
topology.addSink("Tuple-Sink", "cogrouped-results", stringSerializer, tupleSerializer, "CoGrouping-Processor");
//该处理器在开发期间将结果打印到标准输出
topology.addProcessor("Print", new KStreamPrinter("Co-Grouping"), "CoGrouping-Processor")
最后一个步骤是在该拓扑中添加一个接收器节点,该节点作为组合处理器的子节点,将组合处理器处理结果写入一个主题当中。以上同时增加了一个用于在开发期间将结果打印到控制台的处理器,它也是组合处理器的子节点。记住,在使用处理器API时,定义节点的顺序不会建立一个父子关系,父子关系是通过提供先前定义的处理器的名称来确定的。
【注意】本内容选自《Kafka Stream实战》,本人仅对其中未讲解清楚的代码进行解读注释工作,不可私自转载!