1、高并发缓存失效问题:
缓存穿透:
指查询一个一定不存在的数据,由于缓存不命中导致去查询数据库,但数据库也无此记录,我们没有将此次查询的null写入缓存,导致这个不存在的数据每次请求都要到存储层进行查询,失去了缓存的意义;
风险:利用不存在的数据进行攻击让数据库压力增大最终崩溃;
解决:对不存在的数据进行缓存并加入短暂的过期时间;
缓存雪崩:
缓存雪崩是指我们在设置缓存时key采用相同的过期时间,导致缓存在某一个时刻同时失效,请求全部转发到DB,DB瞬间压力过重雪崩;
解决:原有的失效时间基础上增加一个随机值;
缓存击穿:
对于一些设置过期时间的key,如果这些key会在某个时间被高并发地访问,是一种非常“热点”的数据;如果这个key在大量请求同时进来前正好失效,那么所有对这个key的数据查询都落在db,我们称之为缓存击穿
解决:加锁。大量并发情况下只让一个人去查,其他人等到,查到数据后释放锁,其他人获取到锁后先查缓存,这样就不会出现大量访问DB的情况。
2、加锁解决击穿问题
2.1、加本地锁
“确认缓存”与“查询数据库”完成后才释放锁,图示:
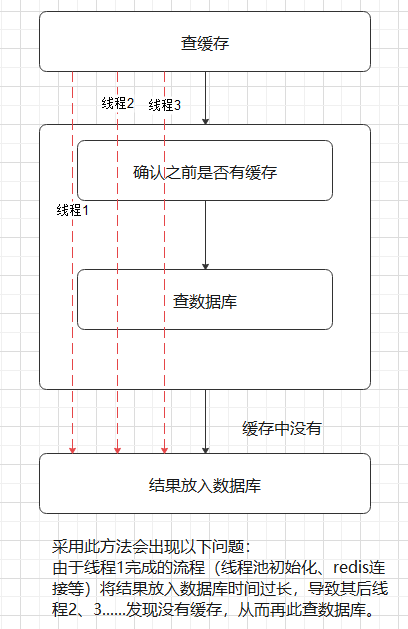
改进后(将“确认缓存”、“查数据库”、“结果放入数据库“都放入锁中):
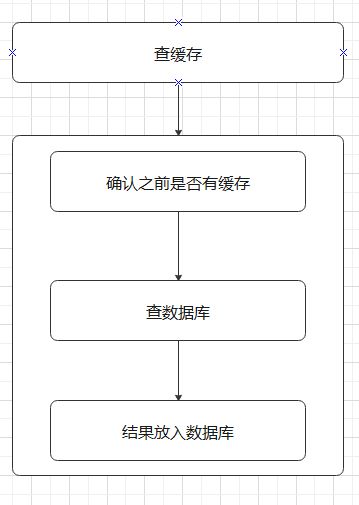
代码部分:
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithLocalLock() { //加锁,只要是同一把锁就锁柱所有线程,例如:100w个请求用同意一把锁 synchronized (this) { //得到锁后再去缓冲中查看,如果缓存没有再去查看,有则直接取缓存。但是使用“this”只能锁住本地服务,所以要使用分布式锁 return getDataFromDb(); } }
private Map<String, List<Catalog2Vo>> getDataFromDb() { //得到锁后再去缓冲中查看,如果缓存没有再去查看,有则直接取缓存。但是使用“this”只能锁住本地服务,所以要使用分布式锁 String catalogJSON = redisTemplate.opsForValue().get("catalogJSON"); if (!StringUtils.isEmpty(catalogJSON)) { //如果缓存不为空直接返回 Map<String, List<Catalog2Vo>> result = JSON.parseObject(catalogJSON, new TypeReference<Map<String, List<Catalog2Vo>>>() { }); return result; } System.out.println("查了数据库"); /* Map<String, List<Catalog2Vo>> catelogJson = (Map<String, List<Catalog2Vo>>) cache.get("catelogJson"); if (cache.get("catelogJson") == null){ }*/ List<CategoryEntity> selectList = baseMapper.selectList(null); //1、先查出所有分类 /** * 一级结构: * id:[ * {二级内容} * {二级内容} * ] */ //List<CategoryEntity> level1Categorys = getLevel1Categorys(); List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L); //2、封装数据,二级结构 /** * "catalog1Id": * "catalog3List":[三级内容] * "id": "",(二级id) * "name": ""(二级名字) * @return */ Map<String, List<Catalog2Vo>> parent_cid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> { //1、查到2级分类 //List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", v.getCatId())); List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId()); List<Catalog2Vo> catalog2Vos = null; if (categoryEntities != null) { catalog2Vos = categoryEntities.stream().map(l2 -> { Catalog2Vo catalog2Vo = new Catalog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName()); /** * 三级内容: * { * "catalog2Id": "",(二级id) * "id": "",(三级id) * "name": "商务休闲鞋"(三级名字) * }, */ //List<CategoryEntity> level3Catalog = getParent_cid(l2); List<CategoryEntity> level3Catalog = getParent_cid(selectList, l2.getCatId()); if (level3Catalog != null) { List<Catalog2Vo.Catalog3Vo> collect = level3Catalog.stream().map(l3 -> { Catalog2Vo.Catalog3Vo catalog3Vo = new Catalog2Vo.Catalog3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName()); return catalog3Vo; }).collect(Collectors.toList()); catalog2Vo.setCatalog3List(collect); } return catalog2Vo; }).collect(Collectors.toList()); } return catalog2Vos; })); //3、放入缓存中 String s = JSON.toJSONString(parent_cid); //1, TimeUnit.DAYS 空结果缓存:解决缓存穿透;设计过期时间:解决雪崩 redisTemplate.opsForValue().set("catalogJSON", s, 1, TimeUnit.DAYS); return parent_cid; }
3、分布式锁原理与使用
由于本地锁只能管理本地服务的事务,所以在分布式微服务中引进了分布式锁
1、分布式锁演进:
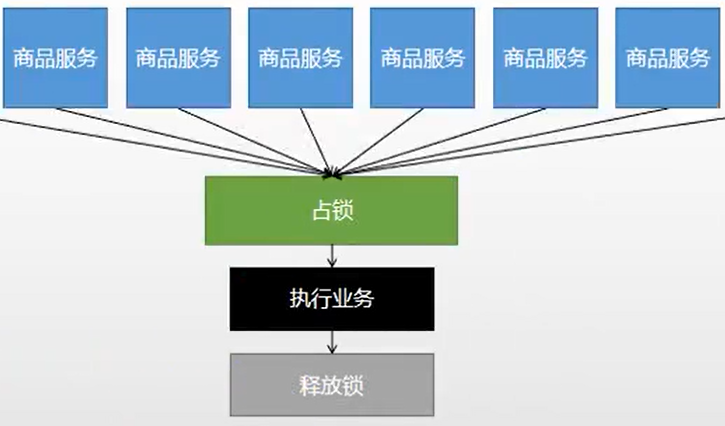
1.1、分布式锁阶段一:
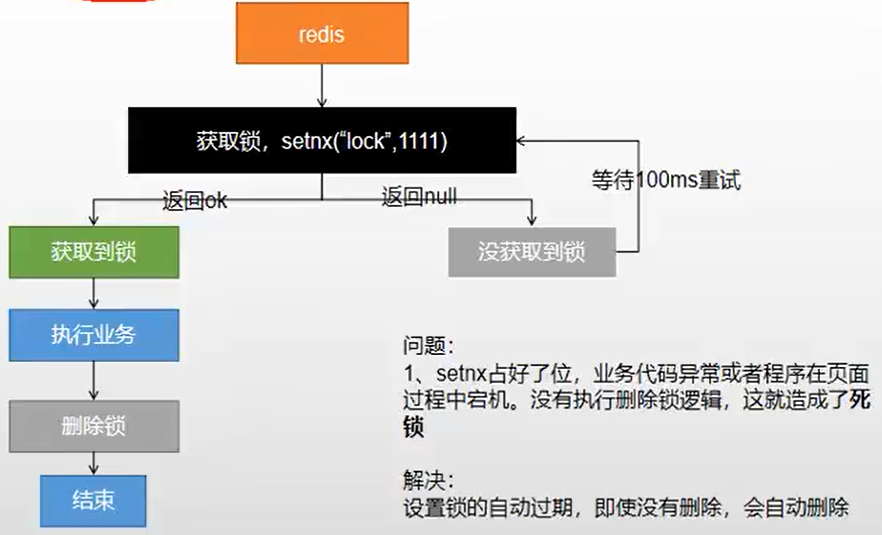
1.2、分布式锁阶段二:
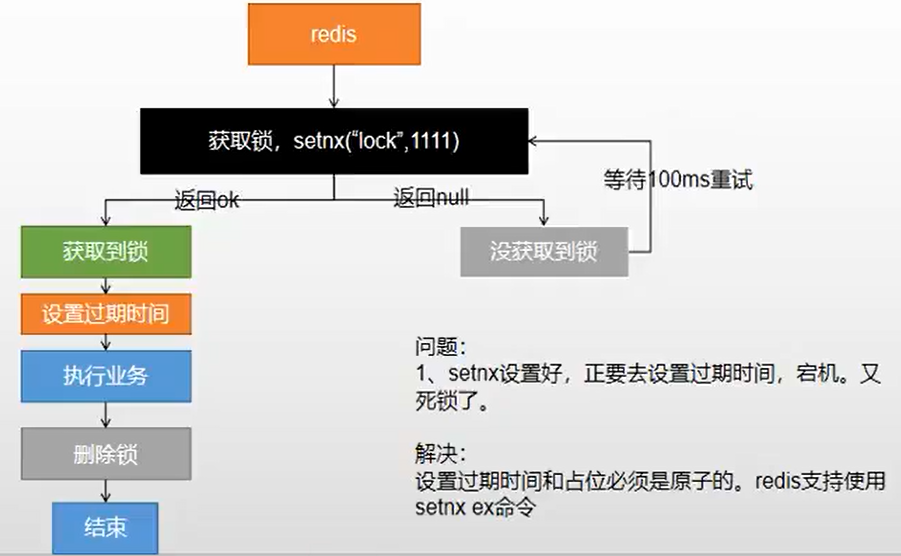
1.3、 分布式锁阶段三:

1.4、分布式锁阶段四:
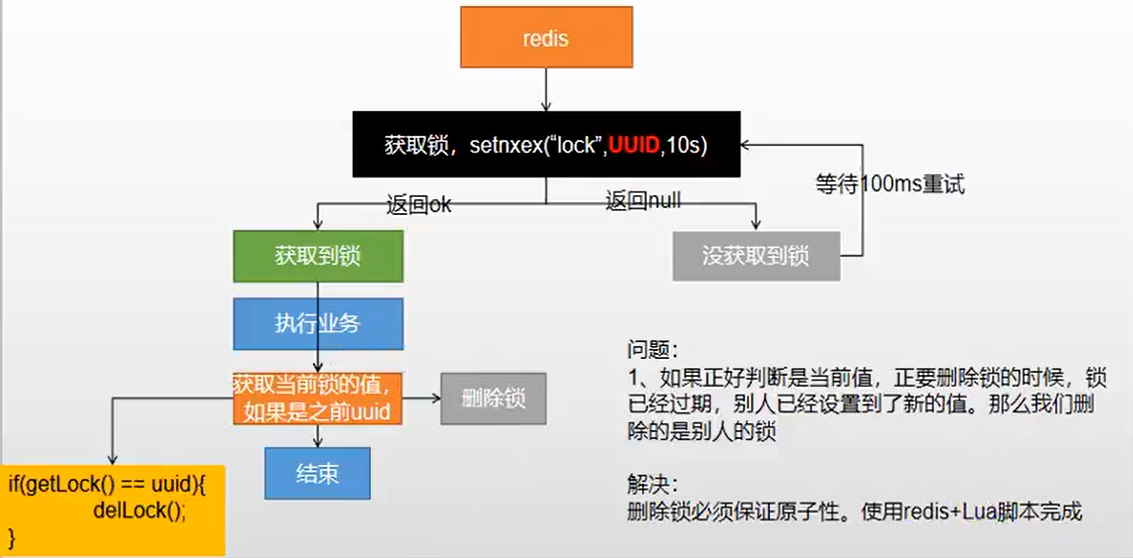
1.5、演进代码:
public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithRedisLock() { //1、占分布式锁,去redis占坑同时加锁成功(原子性),设置过期时间(30秒)。假设过程出问题直接过期不会发生死锁,改进第阶段1和阶段2,使用setIfAbsent原子命令将获取锁和过期时间同时设置 String uuid = UUID.randomUUID().toString(); Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, 300, TimeUnit.SECONDS); if (lock) { System.out.println("获取分布式锁成功"); Map<String, List<Catalog2Vo>> dataFromDb; try { //执行业务 dataFromDb = getDataFromDb(); } finally { //删除锁.redisTemplate.opsForValue().get("lock")获取需要时间释放锁,存在“不可重复读”,所以获取后删除过程也要要求原子性; /* String lockValue = redisTemplate.opsForValue().get("lock"); if (uuid.equals(lockValue)){ redisTemplate.delete("lock"); }*/ //使用脚本,改进阶段4 String script = "if redis.call('get',KEYS[1]) == ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end"; // public <T> T execute(RedisScript<T> script, List<K> keys, Object... args)
// 采用随机的uuid值,改进阶段3 Long lock1 = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class), Arrays.asList("lock"), uuid); } return getDataFromDb(); } else { System.out.println("获取分布式锁失败"); try { Thread.sleep(200); } catch (Exception e) { } //加锁失败,设定时间进行重试 return getCatalogJsonFromDbWithRedisLock();//自旋方式 } }
4、Redisson实践:
1、Redisson官方文档:
https://github.com/redisson/redisson/wiki/Table-of-Content
2、Redisson可重用锁:
@ResponseBody @GetMapping("/hello") public String hello(){ RLock lock= redisson.getLock("my-lock"); lock.lock(10, TimeUnit.SECONDS);//这种方法不会自动续期
//Redisson功能: //1、可以锁的自动续期,如果业务超长,因此不用担心业务时间过长自动删锁 //2、枷锁业务只要运行完成,就不会给当业务续期。默认是30s后自动删锁 try{ //模拟业务超长执行 System.out.println("加锁成功"+Thread.currentThread().getId()); Thread.sleep(30000); } catch (InterruptedException e) { e.printStackTrace(); } finally { lock.unlock(); } return "hello"; }
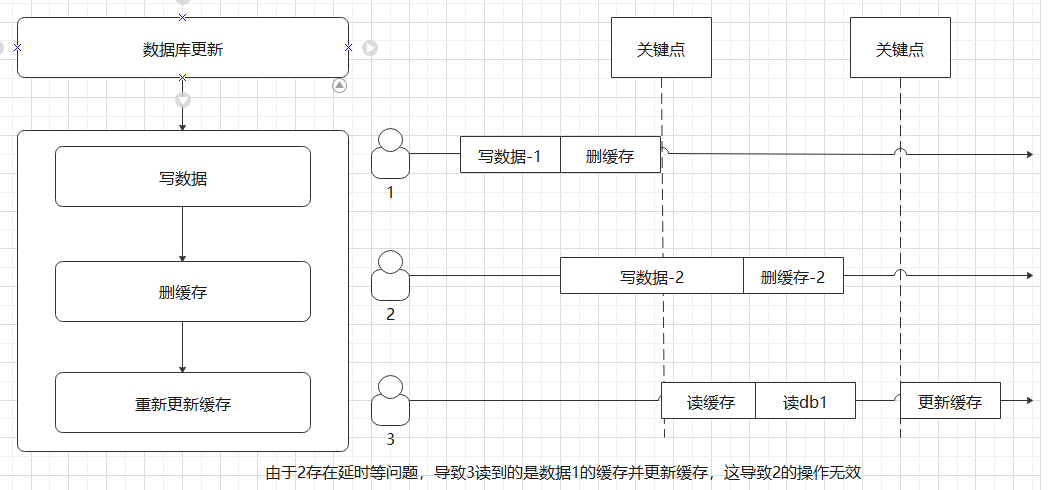
3、缓存数据与数据库保持一致性:
/** * @return 缓存一致性 * 1、双写模式:数据库修改时修改缓存数据,高并发情况下对数据库进行修改容易出现脏数据 * 2、失效模式:数据库更新时删除缓存数据,等待下次查询进行更新缓存 */ public Map<String, List<Catalog2Vo>> getCatalogJsonFromDbWithRedissonLock() { //1、占分布式锁,去redis占坑,锁的粒度越大,越细越快,锁的名字一样 RLock lock = redisson.getLock("CatalogJson-lock"); lock.lock(); Map<String, List<Catalog2Vo>> dataFromDb; try { //运行代码 dataFromDb = getDataFromDb(); } finally { lock.unlock(); } return getDataFromDb(); }
3.1、双写模式:

3.2、失效模式(采用):
5、SpringCache的使用
1、主启动类以及基本注解详解:
/** * * @Cacheable:触发保存缓存。 * @CacheEvict:触发删除缓存。 * @CachePut:更新缓存,而不会干扰方法的执行。 * @Caching:重新组合多个缓存操作。 * @CacheConfig:在类级别共享一些与缓存相关的常见设置。 * * 开启缓存@EnableCaching * * 原理:CacheAutoConfiguration->RedisCacheConfiguration->自动配置了RedisCacheManager->初始化所有缓存->每个缓存决定用什么配置 * ->进行判断,如果有自定义配置则按自定义配置,如果没有则按默认->想改缓存配置,只需要给容器中放一个RedisCacheCpnfiguration */ @EnableRedisHttpSession @EnableCaching @EnableFeignClients(basePackages = "com.atguigu.gulimall.product.feign") @EnableDiscoveryClient @MapperScan(basePackages = "com.atguigu.gulimall.product.dao") @SpringBootApplication public class GulimallProductApplication { public static void main(String[] args) { SpringApplication.run(GulimallProductApplication.class, args); } }
2、注解应用:
/** * 级联更新所有关联的数据 * @CacheEvict:失效模式 * 1、同时进行多种缓存操作 * 2、指定删除某个分区下所有数据:@CacheEvict(value = "category", allEntries = true) * 3、存储同一类型数据、都可以指定同一个分区 * */ /*方法一:@Caching(evict = { @CacheEvict(value = "category", key = "'level1Categorys'"), @CacheEvict(value = "category", key = "'getCatalogJson'") })*/ //@CacheEvict一旦更改数据就清除缓存 @CacheEvict(value = "category", allEntries = true)//方法二 @Transactional @Override public void updateCascade(CategoryEntity category) { this.updateById(category); categoryBrandRelationService.updateCategory(category.getCatId(), category.getName()); } /** * (1指定生成的缓存使用的key:key属性指定 * (2指定缓存的数据存活时间: * (3将数据保存为json */ //每一个缓存的数据都要制定要放到那个名字的缓存【缓存分区】 //缓存过期之后,如果多个线程同时请求对某个数据的访问,会同时去到数据库,导致数据库瞬间负荷增高。 //属性 sync 可以指示底层将缓存锁住,使只有一个线程可以进入计算,而其他线程堵塞,直到返回结果更新到缓存中。 @Cacheable(cacheNames = "category", key = "'level1Categorys'", sync = true) //代表当前方法结果需要缓存,如果缓存中结果,有方法就不调用,如果没有则调用方法并返回缓存结果 @Override public List<CategoryEntity> getLevel1Categorys() { System.out.println("----getLevel1Categorys----"); List<CategoryEntity> categoryEntities = baseMapper.selectList(new QueryWrapper<CategoryEntity>().eq("parent_cid", 0)); return categoryEntities; }
3、将redis缓存数据数据保存为json格式
//可以读取Properties文件 @EnableConfigurationProperties(CacheProperties.class) @EnableCaching @Configuration public class MyCacheConfig { @Bean RedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties) { RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig(); //Key和Value JSON序列化方式 config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())); config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericFastJsonRedisSerializer())); //使用默认才会读出properties文件中的配置,自定义时roperties文件中的配置不生效 CacheProperties.Redis redisProperties = cacheProperties.getRedis(); if (redisProperties.getTimeToLive() != null) { config = config.entryTtl(redisProperties.getTimeToLive()); } if (redisProperties.getKeyPrefix() != null) { config = config.prefixCacheNameWith(redisProperties.getKeyPrefix()); } if (!redisProperties.isCacheNullValues()) { config = config.disableCachingNullValues(); } if (!redisProperties.isUseKeyPrefix()) { config = config.disableKeyPrefix(); } return config; } }
4、SpringCache能解决的事以及不足:
(1)读模式
缓存击穿:查询一个不存在的数据。解决:缓存空数据( ache-null-values=true)
缓存雪崩:大量key刚好过期。解决:加随机时间和过期时间(spring.cache.redis.time-to-live=3600000)
缓存击穿:大量并发同时查询一个正好过期的数据。解决:加锁(@Cacheable(cacheNames = "category", key = "'level1Categorys'", sync = true))
(2)写模式
SpringCache并未做太多处理
总结:读多写少,即时性、、一致性要求不搞的数据使用SpringCache