1、函数
1.1、集合
主要作用:
去重
关系测试, 交集\差集\并集\反向(对称)差集
a = {1,2,3,4}
b ={3,4,5,6}
a
{1, 2, 3, 4}
type(a)
<class 'set'>
a.symmetric_difference(b)
{1, 2, 5, 6}
b.symmetric_difference(a)
{1, 2, 5, 6}
a.difference(b)
{1, 2}
a.union(b)
{1, 2, 3, 4, 5, 6}
a.issu
a.issubset( a.issuperset(
a.issubset(b)
False2. 元组
只读列表,只有count, index 2 个方法
作用:如果一些数据不想被人修改, 可以存成元组,比如身份证列表
3. 字典
key-value对
特性:
无顺序
去重
查询速度快,比列表快多了
比list占用内存多为什么会查询速度会快呢?因为他是hash类型的,那什么是hash呢?
哈希算法将任意长度的二进制值映射为较短的固定长度的二进制值,这个小的二进制值称为哈希值。哈希值是一段数据唯一且极其紧凑的数值表示形式。如果散列一段明文而且哪怕只更改该段落的一个字母,随后的哈希都将产生不同的值。要找到散列为同一个值的两个不同的输入,在计算上是不可能的,所以数据的哈希值可以检验数据的完整性。一般用于快速查找和加密算法
dict会把所有的key变成hash 表,然后将这个表进行排序,这样,你通过data[key]去查data字典中一个key的时候,python会先把这个key hash成一个数字,然后拿这个数字到hash表中看没有这个数字, 如果有,拿到这个key在hash表中的索引,拿到这个索引去与此key对应的value的内存地址那取值就可以了。
上面依然没回答这样做查找一个数据为什么会比列表快,对不对? 呵呵,等我课上揭晓。
4. 字符编码
先说python2
py2里默认编码是ascii
文件开头那个编码声明是告诉解释这个代码的程序 以什么编码格式 把这段代码读入到内存,因为到了内存里,这段代码其实是以bytes二进制格式存的,不过即使是2进制流,也可以按不同的编码格式转成2进制流,你懂么?
如果在文件头声明了#_*_coding:utf-8*_,就可以写中文了, 不声明的话,python在处理这段代码时按ascii,显然会出错, 加了这个声明后,里面的代码就全是utf-8格式了
在有#_*_coding:utf-8*_的情况下,你在声明变量如果写成name=u"大保健",那这个字符就是unicode格式,不加这个u,那你声明的字符串就是utf-8格式
utf-8 to gbk怎么转,utf8先decode成unicode,再encode成gbk再说python3
py3里默认文件编码就是utf-8,所以可以直接写中文,也不需要文件头声明编码了,干的漂亮
你声明的变量默认是unicode编码,不是utf-8, 因为默认即是unicode了(不像在py2里,你想直接声明成unicode还得在变量前加个u), 此时你想转成gbk的话,直接your_str.encode("gbk")即可以
但py3里,你在your_str.encode("gbk")时,感觉好像还加了一个动作,就是就是encode的数据变成了bytes里,我操,这是怎么个情况,因为在py3里,str and bytes做了明确的区分,你可以理解为bytes就是2进制流,你会说,我看到的不是010101这样的2进制呀, 那是因为python为了让你能对数据进行操作而在内存级别又帮你做了一层封装,否则让你直接看到一堆2进制,你能看出哪个字符对应哪段2进制么?什么?自己换算,得了吧,你连超过2位数的数字加减运算都费劲,还还是省省心吧。
那你说,在py2里好像也有bytes呀,是的,不过py2里的bytes只是对str做了个别名,没有像py3一样给你显示的多出来一层封装,但其实其内部还是封装了的。 这么讲吧, 无论是2还是三, 从硬盘到内存,数据格式都是 010101二进制到-->b'xe4xbdxa0xe5xa5xbd' bytes类型-->按照指定编码转成你能看懂的文字编码应用比较多的场景应该是爬虫了,互联网上很多网站用的编码格式很杂,虽然整体趋向都变成utf-8,但现在还是很杂,所以爬网页时就需要你进行各种编码的转换,不过生活正在变美好,期待一个不需要转码的世界。
最后,编码is a piece of fucking shit, noboby likes it.
字符串转换成Unicode 直接在字符串前加u 例子msg = u'你好'
在python3中
变量默认 是Unicode编码格式
只有unicode有encode方法2、函数
在BASIC中叫做subroutine(子过程或子程序),在Pascal中叫做procedure(过程)和function,在C中只有function,在Java里面叫做method。
2.1、###函数定义
定义: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
2.2、函数特性:
减少重复代码
使程序变的可扩展
使程序变得易维护语法定义
def sayhi():#函数名
print("Hello, I'm nobody!")
sayhi() #调用函数
2.3、函数参数与局部变量
2.3.1、形参
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2.3.2、实参
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值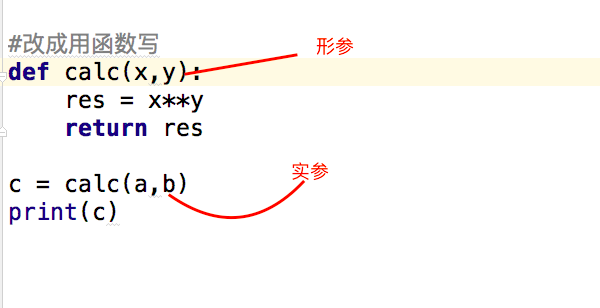
传参 默认的形参赋予变量后 默认就是定义后的变量
2.4、返回值:
- 一旦你的函数经过调用并开始执行,那你的函数外部的程序,就灭有办法在控制函数的执行过程了,此时外部程序只能安静的等待函数的执行结果,为啥等待函数结果,以为外部的程序要根据函数的执行结果来决定下一步怎么走,这个执行结果就是以return的形式返回给外部程序
- return 代表着一个函数的结束
- return可以返回任意数据类型
- 对于用户角度,函数可以返回任意数量的值,但是对于py本身来讲,函数只能返回一个值
2.5、关键参数
正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。
1
stu_register(age=22,name='alex',course="python",)
2.6、非固定参数
2.6.1、*args
若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数
def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式
print(name,age,args)
stu_register("stone",22)
#输出
#Alex 22 () #后面这个()就是args,只是因为没传值,所以为空
stu_register("Jack",32,"CN","Python")
#输出
# Jack 32 ('CN', 'Python')2.6.2、还可以有一个**kwargs
def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式
print(name,age,args,kwargs)
stu_register("stone",22)
#输出
#stone 22 () {}#后面这个{}就是kwargs,只是因为没传值,所以为空
stu_register("liang",23,"CN","Python",sex="male",province="hebei")
#输出
# liang 23 ('CN', 'Python') {'province': 'hebei', 'sex': 'male'}2.7、局部变量和全局变量
局部变量:只在当前的函数内有效
全局变量:整个程序都能用的变量,一般放在文件的开头
局部改全局变量:在局部里需要声明global login_status 然后在改
2.7.1、局部变量
name = "stone"
def change_name(name):
print("before change:",name)
name = "hello"
print("after change", name)
change_name(name)
print("在外面看看name改了么?",name)
输出
before change: stone
after change: hello
在外面看看name改了么? stone2.7.2、全局与局部变量小结:
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。
3、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
def calc(n):
print(n)
if int(n/2) ==0:
return n
return calc(int(n/2))
calc(10)输出:
10
5
2
1
3.1、递归特性:
-
必须有一个明确的结束条件
-
每次进入更深一层递归时,问题规模相比上次递归都应有所减少
-
递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
3.2、匿名函数:
匿名函数就是不需要显式的指定函数
#这段代码
def calc(n):
return n**n
print(calc(10))
#换成匿名函数
calc = lambda n:n**n
print(calc(10))匿名函数主要是和其它函数搭配使用的呢,如下
res = map(lambda x:x**2,[1,5,7,4,8])
for i in res:
print(i)
输出
1
25
49
16
64
map()
把后面的值给前面的函数 处理 结果输出
lambda3.3、高阶函数:
将函数当做参数传给另外一个函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f):
return f(x) + f(y)
res = add(3,-6,abs)
print(res)3.4、函数式编程介绍
编程范式 面向过程 用于 解决问题,用函数比较多
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell, 好了,我只会这么多了。。。
4、内置函数 方法

#compile
# f = open("函数递归.py")
# data =compile(f.read(),'','exec')
# exec(data)
#print
msg = "又回到最初的起点"
f = open("tofile","w")
print(msg,"记忆中你青涩的脸",sep="|",end="",file=f)
#slice
a = range(20)
pattern = slice(3,8,2)
for i in a[pattern]: #等于a[3:8:2]
print(i)
几个内置方法用法提醒4.1 all() 列表的内容都为真则为真,只有0是False
all()
>>> a = [1,2,3]
>>> all(a)
True
>>> a = [0,2,3]
>>> all(a)
False
>>>4.2、判断列表里面的一个为真就为真
any()列表中有一个为真 就为真 列表为空 就为假4.3、print(ascii("地方"))以ascii码的形式显示出来
4.4、bin()将数字转换成二进制形式表示
4.5、bytes() b= b'abc'
4.6、callable() 判断函数是否可用
4.7、查看对应的字符对应的ascii的对应关系
print(chr(98))
print(old('b'))4.8、compile()
相当于import 来导入引用4.9、
eval() exec()
eval() 运算
4.10、complex()输入一个数值输出复数格式
4.11、dir():返回函数的方法
4.12、print(divmod(10,2)):返回的 商和余数
4.13、过滤:filter() = = map()
filter(lambda x:x>5,range(10)):
过滤4.14、frozenset({1,2,3,4,5,5}) 把一个集合变成只读的
4.15、print(globals()) 把 当前程序 内存中开辟的所有空间数据,都以字典的形式打印下来。
4.16、print(local()) local()只打印局部的
4.17、进制
print(hex(8))
0x8
0x代表的16进行4.18、max() 当前列表内的最大值
4.19、min() 当前列表的最小值
4.20、print(pow(4,9))
幂运算
4的9次方4.21、打印print()
msg = "又回到最初的起点"
f = open("tofile","w")
print(msg,"记忆中你青涩的脸",sep="|",end="",file=f)4.22、reversed() 列表:反转
更多的用于字符串的反转,字符串没有反转方法:
4.23、print(round(10.23,1)) 五舍六入
4.24、将列表转换成集合set()
data = [1,2,5,6,7,7]
set(data)4.25、排序sorted
4.26、求和sum() 列表的求和
4.27、vars() 打印当前程序的所有地址
4.28、zip() 拉链
a= [1,3,5,7]
b = [2,4,6,8]
for i in zip(a,b):
print(i)
拉链,
按照最小的来合并