在2017年8月14号的一天接到一个即看即买的项目,大致功能如下
1.现场走秀直播同步到H5页面
2.实时显示直播间人数
3.点赞并实时显示给用户
4.在某个时间点,可以全体推送一些消息给所有用户
5.推送的消息里面的商品可以点击购买,加入购物车。
6.实时聊天,获取用户真实的昵称,头像(基于微信授权)
7.保存聊天记录,用户在进来后显示最后十条聊天记录
约定29号上线,当时准备采取用workman+mysql的方式来处理这些功能,大约有12个工作日来开发,但是其中因为中间穿插了一个另外的项目花去了四天时间,然后客户临时要求加个RSVP的功能花去一天,最后只剩下了7个工作日来开发这个这个项目,包括前端和后端的整合。因为客户希望在直播的时候推出他们的产品,所以不希望直播全屏,那样会使用户看不到商品,前端解决这个问题加上做完这些页面,总共花了三天时间,我只剩了四天时间。因为时间很紧迫,没有考虑这些设计的合理性,包括上线的峰值和并发都没有进行估算,结果出现了大家预想中的事情,服务器宕机。
主要表现:
1.上线10分钟左右,因为直播还没有接入,很多用户在公屏发言,而当时用户的昵称、头像都是保存在数据库的,需要从数据库读取,并且聊天记录要写入数据库。大量的I/O操作,导致mysql内存耗尽,直接mysql gone away了。
2.在大约八点半左右的时候,一位明星的登场走秀,导致直播间人数暴增,在几分钟之内服务器就挂掉了,白屏了大约一分钟。
处理方案:
1.第一次数据库挂掉之后,及时的发现了原因,删除掉了聊天记录的写入之后重启了数据库
2.在apache挂掉之后,查看服务器发现cpu达到96%,内存耗尽所以挂掉,赶紧重启
在直播结束之后,我们向服务器公司要了一份当天直播时候的报告:


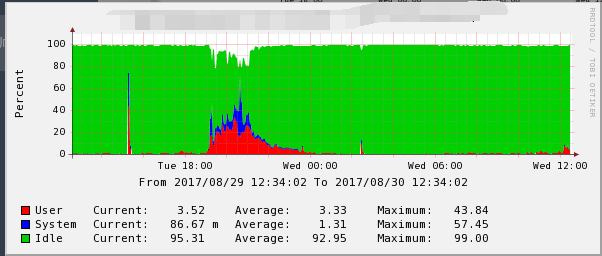
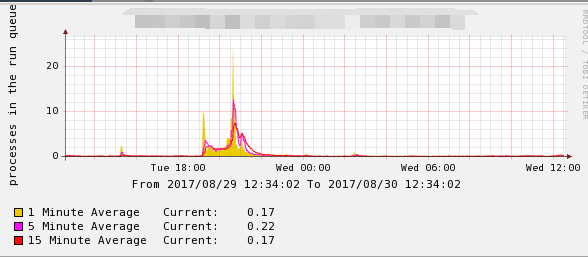
通过上面图标我们可以发现问题,就是服务器过载了,主要两个原因
1.实时聊天购物用的是workman,每进入一个人都会建立一个tcp连接,瞬间涌入的人太多导致连接池满载
2.峰值很高,系统已经发生任务拥塞,Apache和Mysql同时连接内存开销太大,服务器配置是4G内存,4CPU,进程太多不够使用然后消耗系统内存导致服务挂掉
当时服务器挂掉的原因固然是因为服务器配置不高的原因,但是工具选取不对也是很大的因素,后来想了解决方案:
1 .增加服务器的配置(内存和CPU),或者搭建一个简单的负载均衡系统避免一台机器宕机,整个服务停掉
2.瞬间涌入人太多的项目要在项目开始前估算峰值,选择服务器
3.临时修改Apache的最大连接数,满足项目的要求
4.数据存储改成两层数据存储,用nosql+mysql的方式,在半夜服务器活动少的时候同步数据
第二天的时候赶紧花了半天的时候,将所有的操作从操作数据库改成了操作redis,redis可以支撑7-10W的并发,比数据库的性能要好很多,将所有的数据存入redis中,在直播的时候直接操作redis。等到直播结束或者服务器闲置的时候,定时执行脚本将数据同步至mysql,查询的时候先查缓存再查数据库。这样可以很大的避免数据库挂掉,服务器崩溃的情况。
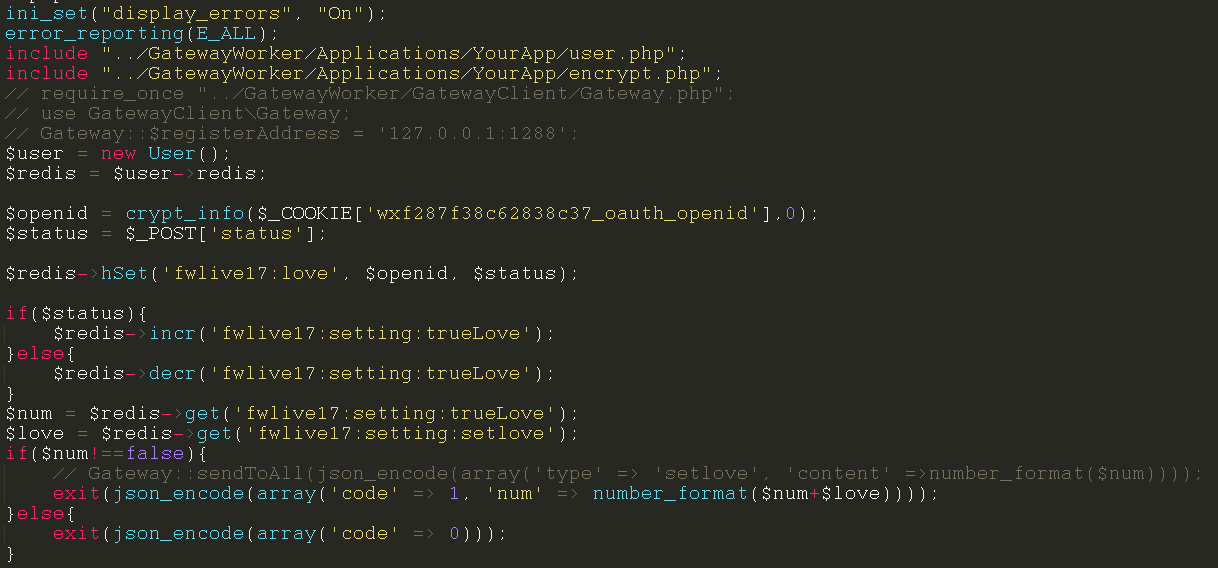
在改成redis存储之后,整个代码量减少了大约三分之二,并且redis的操作是原子性的,对于一些递增递减的操作支持很好,不像MYSQL一样,一旦递增递减update之后就会锁定表,阻塞后面的操作,导致mysql挂掉。