参考网址:
https://www.cnblogs.com/jhxxb/p/10562460.html
https://www.cnblogs.com/qingyunzong/p/8496127.html
一、搭建规划
使用4台CentOS-7进行集群搭建
|
主机名 |
IP地址 |
角色 |
|
master |
192.168.56.100 |
NameNode,ResourceManager |
|
slave1 |
192.168.56.101 |
DataNode,NodeManager,SecondaryNameNode |
|
slave2 |
192.168.56.102 |
DataNode,NodeManager |
|
slave3 |
192.168.56.103 |
DataNode,NodeManager,JobHistoryServer |
规划用户:root
规划安装目录:/opt/hadoop/apps
规划数据目录:/opt/hadoop/data
二.准备工作
1.设置hostname和hosts
1.1设置hostname
#在master,slave1,slave2,slave3上分别执行
#master
hostnamectl set-hostname master
#slave1
hostnamectl set-hostname slave1
#slave2
hostnamectl set-hostname slave2
#slave3
hostnamectl set-hostname slave3
1.2设置hosts
vim /etc/hosts
192.168.56.100 master
192.168.56.101 slave1
192.168.56.102 slave2
192.168.56.103 slave3
2.免密登录
2.1设置登录自己免秘钥
ssh localhost cd ~/.ssh ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
2.2设置master等slave1,slave2,slave3免秘钥
#在master上,将id_dsa_pub分别分发给slave1,slave2,slave3 cp id_dsa.pub master.pub scp -r ~/.ssh/master.pub slave1:~/.ssh/ scp -r ~/.ssh/master.pub slave2:~/.ssh/ scp -r ~/.ssh/master.pub slave3:~/.ssh/
#在slave1,slave2,slave3上分别将id_dsa_pub追加到authorized_keys上 cat ~/.ssh/master.pub >> ~/.ssh/authorized_keys
3.JDK
3.1下载,上传并解压包
#1.在master上,上传并解压包 tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/hadoop/apps #2.在master上,将包分发给slave1,slave2,slave3 scp -r /opt/hadoop/apps/jdk1.8.0_161 slave1:/opt/hadoop/apps scp -r /opt/hadoop/apps/jdk1.8.0_161 slave2:/opt/hadoop/apps scp -r /opt/hadoop/apps/jdk1.8.0_161 slave3:/opt/hadoop/apps
3.2配置环境变量
#1.解压包 tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/hadoop/apps #2.配置环境变量 vim ~/.bashrc export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 export PATH=$PATH:$JAVA_HOME/bin #3.使得环境变量生效 source ~/.bashrc #4.验证 java -version #如果显示为Linux自带OpenJdk(如下),需要先卸载 #[root@localhost apps]# java -version #openjdk version "1.8.0_242" #OpenJDK Runtime Environment (build 1.8.0_242-b08) #OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode) #参考网址:https://blog.csdn.net/qq_35535690/article/details/81976210 rpm -qa|grep java rpm -e --nodeps java-1.7.0-openjdk-1.7.0.251-2.6.21.1.el7.x86_64 rpm -e --nodeps java-1.7.0-openjdk-headless-1.7.0.251-2.6.21.1.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-1.8.0.242.b08-1.el7.x86_64 rpm -e --nodeps java-1.8.0-openjdk-headless-1.8.0.242.b08-1.el7.x86_64
4.关闭防火墙
#永久关闭防火墙
systemctl disable firewalld
#临时关闭防火墙
systemctl stop firewalld
#注意:如果系统报错java.io.IOException: Got error, status message , ack with firstBadLink as 192.168.56.102:50010
#可能是由于没有关闭防火墙导致的,第一条命令不会及时生效,所以还需要第二条命令
5.关闭安全机制
vim /etc/sysconfig/selinux
SELINUX=disable
6.同步时间
date -s 'yyyy-MM-dd hh:mm:ss'
date -s '2021-02-02 12:17:50'
三、搭建工作
0.解压及环境变量配置
#1.解压包 unzip hadoop-2.7.1.zip -d /opt/hadoop/apps #2.配置环境变量 vim ~/.bashrc export HADOOP_HOME=/opt/hadoop/apps/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin #3.使得环境变量生效 source ~/.bashrc
1.配置hdfs
#1.配置hdfs-env.sh export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 #2.配置core-site.xml <configuration> <property> <name>dfs.defaultDF</name> <value>hdfs://master:9000</value> <description>指定master</description> </property> <property> <name>dfs.tmp.data.dir</name> <value>/opt/hadoop/data/hadoopdata/tmp</value> <description>hadoop产生的数据</description> </property> </configuration> #3.配置hdfs-site.xml <configuration> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop/data/namenode</value> <description>为了保证元数据的安全一般配置多个不同目录</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop/data/datanode</value> <description>datanode 的数据存储目录</description> </property> <property> <name>dfs.replication</name> <value>3</value> <description>HDFS 的数据块的副本存储个数, 默认是3</description> </property> <property> <name>dfs.secondary.http.address</name> <value>slave1:50090</value> <description>secondarynamenode 运行节点的信息,和 namenode 不同节点</description> </property> </configuration> #4.配置slaves vim slaves slave1 slave2 slave3
2.配置yarn
#1.配置yarn-env.sh export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 #2.配置yarn-site.xml <configuration> <!-- Site specific YARN configuration properties --> <!-- Reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> </configuration>
3.配置mapreduce
#1.配置mapred-env.sh export JAVA_HOME=/opt/hadoop/apps/jdk1.8.0_161 #2.配置mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4.配置jobhistory,打开日志历史服务器
#mapred-site.xml #jobhistory用于查询每个job运行完以后的历史日志信息,是作为一台单独的服务器运行的。 #可以在namenode或者datanode上的任意一台启动即可。 <configuration> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>slave3:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>slave3:19888</value> </property> <property> <name>yarn.log.server.url</name> <value>http://slave3:19888/jobhistory/logs</value> </property> </configuration>
5.配置log-aggregation,打开日志聚集
#yarn-site.xml <configuration> <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志保留时间(7天) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
6.分发文件给slave1,slave2,slave3
#1.将配置好的hadoop包分发给slave1,slave2,slave3 scp -r /opt/hadoop/apps/hadoop-2.7.1 slave1:/opt/hadoop/apps/ scp -r /opt/hadoop/apps/hadoop-2.7.1 slave2:/opt/hadoop/apps/ scp -r /opt/hadoop/apps/hadoop-2.7.1 slave3:/opt/hadoop/apps/ #2.在slave1,slave2,slave3配置hadoop的环境变量 vim ~/.bashrc export HADOOP_HOME=/opt/hadoop/apps/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source ~/.bashrc
7.初始化,启动,验证
#如果命令没有执行权限,需要赋予执行的权限
chmod +x /opt/hadoop/apps/hadoop-2.7.1/bin/*
chmod +x /opt/hadoop/apps/hadoop-2.7.1/sbin/*
#1.在master上格式化namenode,只需要格式化一次,如果已经格式化,则再不需要
hdfs namenode -format
#2.在namenode节点启动服务;如果想在其他节点启动,可以配置免密登录,或者启动后输入密码
start-all.sh
#3.在slave3上启动日志服务器
mr-jobhistory-daemon.sh start historyserver
#master的进程 22820 Jps 20215 DataNode 20409 NodeManager 20154 NameNode 20349 ResourceManager #slave1的进程 4242 Jps 4108 DataNode 4175 SecondaryNameNode #slave2的进程 4026 Jps 3947 DataNode #slave3的进程 4097 Jps 3947 DataNode 4063 JobHistoryServer
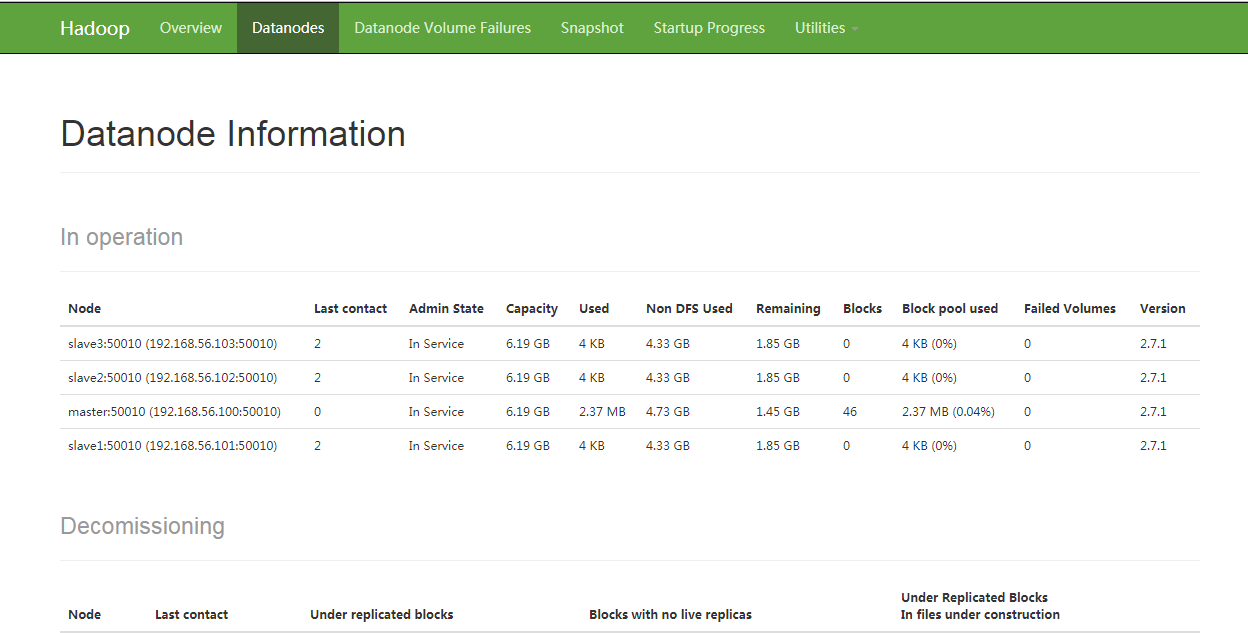
hdfs dfsadmin -report Configured Capacity: 26566721536 (24.74 GB) Present Capacity: 7530344448 (7.01 GB) DFS Remaining: 7527845888 (7.01 GB) DFS Used: 2498560 (2.38 MB) DFS Used%: 0.03% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 ------------------------------------------------- Live datanodes (4): Name: 192.168.56.100:50010 (master) Hostname: master Decommission Status : Normal Configured Capacity: 6641680384 (6.19 GB) DFS Used: 2486272 (2.37 MB) Non DFS Used: 5082165248 (4.73 GB) DFS Remaining: 1557028864 (1.45 GB) DFS Used%: 0.04% DFS Remaining%: 23.44% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 02 12:54:34 CST 2021 Name: 192.168.56.102:50010 (slave2) Hostname: slave2 Decommission Status : Normal Configured Capacity: 6641680384 (6.19 GB) DFS Used: 4096 (4 KB) Non DFS Used: 4651347968 (4.33 GB) DFS Remaining: 1990328320 (1.85 GB) DFS Used%: 0.00% DFS Remaining%: 29.97% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 02 12:54:32 CST 2021 Name: 192.168.56.103:50010 (slave3) Hostname: slave3 Decommission Status : Normal Configured Capacity: 6641680384 (6.19 GB) DFS Used: 4096 (4 KB) Non DFS Used: 4651360256 (4.33 GB) DFS Remaining: 1990316032 (1.85 GB) DFS Used%: 0.00% DFS Remaining%: 29.97% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 02 12:54:31 CST 2021 Name: 192.168.56.101:50010 (slave1) Hostname: slave1 Decommission Status : Normal Configured Capacity: 6641680384 (6.19 GB) DFS Used: 4096 (4 KB) Non DFS Used: 4651503616 (4.33 GB) DFS Remaining: 1990172672 (1.85 GB) DFS Used%: 0.00% DFS Remaining%: 29.96% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Tue Feb 02 12:54:31 CST 2021
hadoop jar /opt/hadoop/apps/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 2 10
[root@master hadoop]# hadoop jar /opt/hadoop/apps/hadoop-2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar pi 2 10
Number of Maps = 2
Samples per Map = 10
Wrote input for Map #0
Wrote input for Map #1
Starting Job
21/02/02 13:24:05 INFO client.RMProxy: Connecting to ResourceManager at master/192.168.56.100:8032
21/02/02 13:24:31 INFO input.FileInputFormat: Total input paths to process : 2
21/02/02 13:24:39 INFO mapreduce.JobSubmitter: number of splits:2
21/02/02 13:24:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1612235235513_0003
21/02/02 13:24:56 INFO impl.YarnClientImpl: Submitted application application_1612235235513_0003
21/02/02 13:24:58 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1612235235513_0003/
21/02/02 13:24:58 INFO mapreduce.Job: Running job: job_1612235235513_0003
21/02/02 13:25:45 INFO mapreduce.Job: Job job_1612235235513_0003 running in uber mode : false
21/02/02 13:25:45 INFO mapreduce.Job: map 0% reduce 0%
21/02/02 13:31:03 INFO mapreduce.Job: map 100% reduce 0%
21/02/02 13:32:08 INFO mapreduce.Job: map 100% reduce 100%
21/02/02 13:32:47 INFO mapreduce.Job: Job job_1612235235513_0003 completed successfully
21/02/02 13:33:02 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=50
FILE: Number of bytes written=347637
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=520
HDFS: Number of bytes written=215
HDFS: Number of read operations=11
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=612092
Total time spent by all reduces in occupied slots (ms)=63386
Total time spent by all map tasks (ms)=612092
Total time spent by all reduce tasks (ms)=63386
Total vcore-seconds taken by all map tasks=612092
Total vcore-seconds taken by all reduce tasks=63386
Total megabyte-seconds taken by all map tasks=626782208
Total megabyte-seconds taken by all reduce tasks=64907264
Map-Reduce Framework
Map input records=2
Map output records=4
Map output bytes=36
Map output materialized bytes=56
Input split bytes=284
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=56
Reduce input records=4
Reduce output records=0
Spilled Records=8
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=11536
CPU time spent (ms)=16840
Physical memory (bytes) snapshot=444182528
Virtual memory (bytes) snapshot=6228303872
Total committed heap usage (bytes)=261935104
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=236
File Output Format Counters
Bytes Written=97
21/02/02 13:33:04 INFO ipc.Client: Retrying connect to server: master/192.168.56.100:37042. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1000 MILLISECONDS)
21/02/02 13:33:05 INFO ipc.Client: Retrying connect to server: master/192.168.56.100:37042. Already tried 1 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1000 MILLISECONDS)
21/02/02 13:33:06 INFO ipc.Client: Retrying connect to server: master/192.168.56.100:37042. Already tried 2 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=3, sleepTime=1000 MILLISECONDS)
21/02/02 13:33:07 INFO mapred.ClientServiceDelegate: Application state is completed. FinalApplicationStatus=SUCCEEDED. Redirecting to job history server
Job Finished in 553.426 seconds
Estimated value of Pi is 3.80000000000000000000
#常见命令hdfs dfs -help #1.创建文件夹 hdfs dfs -mkdir -p /hadoop/data/ #2.从本地拷贝文件到hdfs hdfs dfs -copyFromLocal /opt/hadoop/data/data.txt /hadoop/data/person #3.复制 hdfs dfs -cp /hadoop/data/person /hadoop/data/student #4.查询文件和文件夹列表 hdfs dfs -ls /hadoop/data/ #5.显示文件内容 hdfs dfs -text /hadoop/data/student #6.删除文件 hdfs dfs -rm /hadoop/data/person #7.从hdfs拷贝到本地 hdfs dfs -copyToLocal /hadoop/data/student /opt/hadoop/data/data1 #8.从hdfs获取文件到服务器 hdfs dfs -get /hadoop/data/student #9.从服务器上传文件到hdfs hdfs dfs -put student /hadoop/data/student2 #10.追加文件内容 hdfs dfs -appendToFile student /hadoop/data/student #11.查看文件内容 hdfs dfs -cat /hadoop/data/student #12.删除整个文件夹 hdfs dfs -rm -r -f /hadoop/data/ #13.删除文件夹 hdfs dfs -rmdir -p /hadoop