我们在String中介绍过它有一个格式化的方法,在其它很多地方,也都能看到格式化的操作,那么这节我们就来认真了解一下Java中的格式化操作。
我们在操作中涉及到的格式化有字符串的格式化和一些其它数据类型的格式化输出等,实际上Java中的格式化操作都是由Java中的一个类java.util.Formatter来处理的。可以将Formatter看作一个翻译器,它将你的格式化字符串与数据翻译成你需要的样式。当你创建一个Formatter对象时,需要向其构造器传递一个些信息,告诉它最终的结果向哪里输出。下面我们就来认识一个格式化类Formatter。我们要注意Java中有两个Formatter类一个是util包中的,一个是util.logging包中的,我们导包时不要倒错了。
11.1 Formatter的概述
查看API对Formatter的解释“printf 风格的格式字符串的解释程序。此类提供了对布局对齐和排列的支持,以及对数值、字符串和日期/时间数据的常规格式和特定于语言环境的输出的支持。支持诸如 byte、BigDecimal 和 Calendar 等常见 Java 类型。任意用户类型的受限格式化定制都是通过 Formattable 接口提供的。 Formatter 对于多线程访问而言没必要是安全的。线程安全是可选的,它对此类中的方法用户负责。 Java 语言的格式化输出在很大程度上受到 C 语言 printf 的启发。虽然一些格式字符串与 C 类似,但已进行了某些定制,以适应 Java 语言,并且利用了其中一些特性。此外,Java 的格式比 C 的格式更严格;例如,如果转换与标志不兼容,则会抛出异常。在 C 中,不适用的标志会被忽略。这样,便于 C 程序员识别这些格式字符串,而又不必与 C 中的那些标志完全兼容。 ”
有了上面的一些了解,下面我们来详细认识一下Formatter,先从其格式转换和标志讲起,这是格式化的基本和必须;
11.2 Formatter的格式转换与标志
产生格式化输出的每个方法都需要格式字符串和参数列表。格式字符串是一个 String,它可以包含固定文本以及一个或多个嵌入的格式说明符。请考虑以下示例:
Calendar c = ...;
String s = String.format("Duke's Birthday: %1$tm %1$te,%1$tY", c);
此格式字符串是 format 方法的第一个参数。它包含三个格式说明符 "%1$tm"、"%1$te" 和 "%1$tY",它们指出应该如何处理参数以及在文本的什么地方插入它们。格式字符串的其余部分是包括 "Dukes Birthday: " 和其他任何空格或标点符号的固定文本。 参数列表由传递给位于格式字符串之后的方法的所有参数组成。在上述示例中,参数列表的大小为 1,由对象 Calendar c 组成。 这就是一个简单的字符串的格式化转换,而实际上转换是可以分为好多种的.
转换可分为以下几类:
- 常规 - 可应用于任何参数类型
- 字符 - 可应用于表示 Unicode 字符的基本类型:char、Character、byte、Byte、short 和 Short。当 Character.isValidCodePoint(int) 返回 true 时,可将此转换应用于 int 和 Integer 类型
- 数值
-
- 整数 - 可应用于 Java 的整数类型:byte、Byte、short、Short、int、Integer、long、Long 和 BigInteger
- 浮点 - 可用于 Java 的浮点类型:float、Float、double、Double 和 BigDecimal
- 日期/时间 - 可应用于 Java 的、能够对日期或时间进行编码的类型:long、Long、Calendar 和 Date。
- 百分比 - 产生字面值 '%' ('u0025')
- 行分隔符 - 产生特定于平台的行分隔符
下表总结了受支持的转换。由大写字符(如 'B'、'H'、'S'、'C'、'X'、'E'、'G'、'A' 和 'T')表示的转换与由相应的小写字符的转换等同,根据流行的 Locale 规则将结果转换为大写形式除外。后者等同于 String.toUpperCase() 的以下调用 out.toUpperCase()
|
转换 |
参数类别 |
说明 |
|
'b', 'B' |
常规 |
如果参数 arg 为 null,则结果为 "false"。如果 arg 是一个 boolean 值或 Boolean,则结果为 String.valueOf() 返回的字符串。否则结果为 "true"。 |
|
'h', 'H' |
常规 |
如果参数 arg 为 null,则结果为 "null"。否则,结果为调用 Integer.toHexString(arg.hashCode()) 得到的结果。 |
|
's', 'S' |
常规 |
如果参数 arg 为 null,则结果为 "null"。如果 arg 实现 Formattable,则调用 arg.formatTo。否则,结果为调用 arg.toString() 得到的结果。 |
|
'c', 'C' |
字符 |
结果是一个 Unicode 字符 |
|
'd' |
整数 |
结果被格式化为十进制整数 |
|
'o' |
整数 |
结果被格式化为八进制整数 |
|
'x', 'X' |
整数 |
结果被格式化为十六进制整数 |
|
'e', 'E' |
浮点 |
结果被格式化为用计算机科学记数法表示的十进制数 |
|
'f' |
浮点 |
结果被格式化为十进制数 |
|
'g', 'G' |
浮点 |
根据精度和舍入运算后的值,使用计算机科学记数形式或十进制格式对结果进行格式化。 |
|
'a', 'A' |
浮点 |
结果被格式化为带有效位数和指数的十六进制浮点数 |
|
't', 'T' |
日期/时间 |
日期和时间转换字符的前缀。请参阅日期/时间转换。 |
|
'%' |
百分比 |
结果为字面值 '%' ('u0025') |
|
'n' |
行分隔符 |
结果为特定于平台的行分隔符 |
任何未明确定义为转换的字符都是非法字符,并且都被保留,以供将来扩展使用。
下表总结了受支持的标志。y 表示该标志受指示参数类型支持。
|
标志 |
常规 |
字符 |
整数 |
浮点 |
日期/时间 |
说明 |
|
'-' |
y |
y |
y |
y |
y |
结果将是左对齐的。 |
|
'#' |
y1 |
- |
y3 |
y |
- |
结果应该使用依赖于转换类型的替换形式 |
|
'+' |
- |
- |
y4 |
y |
- |
结果总是包括一个符号 |
|
' ' |
- |
- |
y4 |
y |
- |
对于正值,结果中将包括一个前导空格 |
|
'0' |
- |
- |
y |
y |
- |
结果将用零来填充 |
|
',' |
- |
- |
y2 |
y5 |
- |
结果将包括特定于语言环境的组分隔符 |
|
'(' |
- |
- |
y4 |
y5 |
- |
结果将是用圆括号括起来的负数 |
1 取决于 Formattable 的定义。
2 只适用于 'd' 转换。
3 只适用于 'o'、'x' 和 'X' 转换。
4 对 BigInteger 应用 'd'、'o'、'x' 和 'X' 转换时,或者对 byte 及 Byte、short 及 Short、int 及 Integer、long 及 Long 分别应用 'd' 转换时适用。
5 只适用于 'e'、'E'、'f'、'g' 和 'G' 转换。
任何未显式定义为标志的字符都是非法字符,并且都被保留,以供扩展使用。
11.2.1 格式化的相关概念
我们在格式化中除了标志和符号外,还会接触一些其它概念,下面我们就来解读一下; 主要是宽带,精度和参数索引.
11.2.1.1 宽度
宽度是将向输出中写入的最少字符数。对于行分隔符转换,不适用宽度,如果提供宽度,则会抛出异常。
11.2.1.2 精度
对于常规参数类型,精度是将向输出中写入的最多字符数。
对于浮点转换 'e'、'E' 和 'f',精度是小数点分隔符后的位数。如果转换是 'g' 或 'G',那么精度是舍入计算后所得数值的所有位数。如果转换是 'a' 或 'A',则不必指定精度。 对于字符、整数和日期/时间参数类型转换,以及百分比和行分隔符转换,精度是不适用的;如果提供精度,则会抛出异常。
11.2.2 格式化规范的详细信息
这一部分将提供格式化行为规范方面的细节,其中包括条件和异常、受支持的数据类型、本地化以及标志、转换和数据类型之间的交互。
任何未明确定义为转换、日期/时间转换前缀或标志的字符都是非法字符,并且这些字符都被保留,以供未来扩展使用。在格式字符串中使用这样的字符会导致抛出 UnknownFormatConversionException 或 UnknownFormatFlagsException。
如果格式说明符包含带有无效值或不受支持的其他值的宽度或精度,则将分别抛出 IllegalFormatWidthException 或 IllegalFormatPrecisionException。
如果格式说明符包含不适用于对应参数的转换字符,则将抛出 IllegalFormatConversionException。
所有指定异常都可能被 Formatter 的任何 format 方法以及任何 format 的便捷方法抛出,比如
String#format(String,Object...)String.format java.io.PrintStream#printf(String,Object...)PrintStream.printf
由大写字符(如 'B'、'H'、'S'、'C'、'X'、'E'、'G'、'A' 和 'T')表示的转换与那些相应的小写字符表示的转换相同,根据流行的 Locale 规则将结果转换成大写形式除外。结果等同于 String.toUpperCase() 的以下调用 out.toUpperCase()
12.2.4.1 常规
以下常规转换可应用于任何参数类型:
|
'b' |
'u0062' |
将生成 "true" 或 "false",由 Boolean.toString(boolean) 返回。 如果参数为 null,则结果为 "false"。如果参数是一个 boolean 值或 Boolean,那么结果是由 String.valueOf() 返回的字符串。否则结果为 "true"。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'B' |
'u0042' |
'b' 的大写形式。 |
|
'h' |
'u0068' |
生成一个表示对象的哈希码值的字符串。 如果参数 arg 为 null,则结果为 "null"。否则,结果为调用 Integer.toHexString(arg.hashCode()) 得到的结果。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'H' |
'u0048' |
'h' 的大写形式。 |
|
's' |
'u0073' |
生成一个字符串。 如果参数为 null,则结果为 "null"。如果参数实现了 Formattable,则调用其 formatTo 方法。否则,结果为调用参数的 toString() 方法得到的结果。 如果给出 '#' 标志,且参数不是 Formattable,则将抛出 FormatFlagsConversionMismatchException。 |
|
'S' |
'u0053' |
's' 的大写形式。 |
以下 标志 应用于常规转换:
|
'-' |
'u002d' |
将输出左对齐。根据需要在转换值结尾处添加空格 ('u0020'),以满足字段的最小宽度要求。如果没有提供宽度,则将抛出 MissingFormatWidthException。如果没有给出此标志,则输出将是右对齐的。 |
|
'#' |
'u0023' |
要求输出使用替换形式。此形式的定义通过转换指定。 |
宽度 是将向输出中写入的最少字符数。如果转换值的长度小于宽度,则用 ' ' (u0020') 填充输出,直到字符总数等于宽度为止。默认情况下,是在左边进行填充。如果给出 '-' 标志,则在右边进行填充。如果没有指定宽度,则没有最小宽度。
精度是将向输出中写入的最多字符数。精度的应用要先于宽度,因此,即使宽度大于精度,输出也将被截取为 precision 字符。如果没有指定精度,则对字符数没有明确限制。
注意:测试使用得是JDK1.8版本
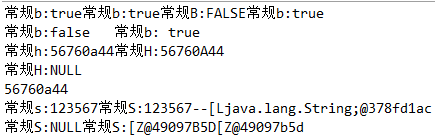
/** * 常规格式化练习 */ @Test public void test2(){ String str1 = "123567"; String str2 = "false"; String[] arr = {str1,str2}; boolean boo = true; boolean boo2 = false; boolean[] arrBoo = {boo,boo2}; System.out.printf("常规b:%b", arr); /** * 可变参数在这里只会将其作为数组处理,所以返回true */ System.out.printf("常规b:%b",arrBoo); System.out.printf("常规B:%B",null); System.out.printf("常规b:%-5b ", boo);//宽度是5,不够的话在右边填充 System.out.printf("常规b:%-8b", boo2);//宽度是8,不够的话在右边填充 System.out.printf("常规b:%5b ", boo);//宽度是5,不够的话在左边填充 System.out.printf("常规h:%h", str1); System.out.printf("常规H:%H ", arr); System.out.printf("常规H:%H ", null); System.out.println(Integer.toHexString(str1.hashCode())); // arr[0] = "abc"; System.out.printf("常规s:%s", str1); System.out.printf("常规S:%S",arr);//数组如果是字符串或字符数组,那么返回的是第一个元素的toString() System.out.println("--"+arr.toString()); System.out.printf("常规S:%S",null); System.out.printf("常规S:%S",arrBoo); System.out.println(arrBoo.toString()); }
12.2.4.2 字符
此转换可应用于 char 和 Character。它还可应用于类型 byte、Byte、short 和 Short、 int 和 Integer。当 Character.isValidCodePoint(int) 返回 true 时,此转换也可应用于 int 和 Integer。如果返回 false,则将抛出 IllegalFormatCodePointException。
|
'c' |
'u0063' |
将参数格式化为 Unicode Character Representation 中描述的 Unicode 字符。在该参数表示增补字符的情况下,它可能是多个 16 位 char。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'C' |
'u0043' |
'c' 的大写形式。 |
'-' 标志是为应用常规转换而定义的。如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。
宽度是为了实现常规转换而定义的。
精度不适用。如果指定精度,则将抛出 IllegalFormatPrecisionException。
/** * 字符格式化练习 */ @Test public void testChar(){ System.out.printf("字符格式化:%c", 'a'); // System.out.printf("字符格式化:%c", "abc");只能是Unicode表中的数字,所以这里字符串会爆出异常java.util.IllegalFormatConversionException: c != java.lang.String System.out.printf("字符格式化:%c", 24); System.out.printf("字符格式化:%-5c", 'a');//不能使用精度,可以使用宽度 }
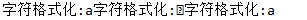
12.2.4.3 数值
数值转换分为以下几类:
Byte、Short、Integer 和 Long
BigInteger
Float 和 Double
BigDecimal
将根据以下算法对数值类型进行格式化:
12.2.4.3.1 数字本地化算法
在获得数字的整数部分、小数部分和指数(适用于数据类型)之后,将应用以下转换:
将字符串中的每个数字字符 d 都替换为特定于语言环境的数字,该数字是相对于当前语言环境的零数字 z 来计算的;即 d - '0' + z。 如果存在小数点分隔符,则用特定于语言环境的小数点分隔符替换。 如果给出 ',' ('u002c') flag 标志,则插入特定于语言环境的组分隔符,这是通过从最低位到最高位浏览字符串的整数部分并不时插入该语言环境组大小定义的分隔符来实现的。 如果给出 '0' 标志,则在符号字符(如果有的话)之后、第一个非零数字前插入特定于语言环境的零数字,直到字符串长度等于所要求的字段宽度。
如果该值为负,并且给出了 '(' 标志,那么预先考虑 '(' ('u0028'),并追加一个 ')' ('u0029')。
如果该值为负(或者为浮点负零),并且没有给出 '(' 标志,那么预先考虑 '-' ('u002d')。
如果给出 '+' 标志,并且该值为正或零(或者为浮点正零),那么将预先考虑 '+' ('u002b')。
如果该值为 NaN 或正无穷大,则分别输出文本字符串 "NaN" 或 "Infinity"。如果该值为负无穷大,那么输出将是 "(Infinity)";否则如果给出 '(' 标志,那么输出将是 "-Infinity"。这些值都没有被本地化。
12.2.4.3.2 Byte、Short、Integer 和 Long
以下转换可应用于 byte、Byte、short、Short、int、Integer、long 和 Long。
|
'd' |
'u0054' |
将参数格式化为十进制整数。应用本地化算法。 如果给出 '0' 标志,并且值为负,则在符号后填充零。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'o' |
'u006f' |
将参数格式化为以 8 为基数的整数。不应用本地化。 如果 x 为负,那么结果将是通过将 2n 添加到值中产生的一个无符号值,其中 n 是在适当时候由类 Byte、Short、Integer 或 Long 中的静态 SIZE 字段返回的类型中的位数。 如果给出 '#' 标志,则输出将始终以基数指示符 '0' 开始。 如果给出 '0' 标志,则使用前导零填充输出,这些零被填充到以下任意指示符号后面的字段宽度中。 如果给出 '('、'+'、' ' 或 '、' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'x' |
'u0078' |
将参数格式化为以 16 为基数的整数。不应用本地化。 如果 x 为负,那么结果将为把 2n 添加到值中产生的一个无符号值,其中 n 是在适当时候,由类 Byte、Short、Integer 或 Long 中的静态 SIZE 字段返回的类型中的位数。 如果给出 '#' 标志,则输出将始终以基数指示符 '0x' 开始。 如果给出 '0' 标志,则使用前导零填充输出,这些零被填充到基数指示符或符号(如果存在)后面的字段宽度中。 如果给出 '('、' '、'+' 或 '、' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'X' |
'u0058' |
'x' 的大写形式。将表示数字的整个字符串转换为大写,其中包括 'x' (如果有的话) 和所有十六进制数字 'a' - 'f' ('u0061' - 'u0066')。 |
如果该转换是 'o'、'x' 或 'X' 转换,并且给出了 '#' 和 '0' 标志,那么结果将包含基数指示符(对于八进制是 '0',对于十六进制是 '0' 或 "0x")、一定数量的零(基于宽度)和该值。
如果没有给出 '-' 标志,则在符号前填充空格。
以下 标志 应用于数值整数转换:
|
'+' |
'u002b' |
要求所有正数的输出都包含一个正号。如果没有给出此标志,则只有负值包含符号。 如果同时给出了 '+' 和 ' ' 标志,则将抛出 IllegalFormatFlagsException。 |
|
' ' |
'u0020' |
对于非负值的输出,要求包括单个额外空格 ('u0020')。 如果同时给出了 '+' 和 ' ' 标志,则将抛出 IllegalFormatFlagsException。 |
|
'0' |
'u0030' |
要求将前导零填充到输出中,这些零被填充到以下任意符号或基数指示符之后,以达到最小字段宽度,转换 NaN 或无穷大时除外。如果没有提供宽度,则将抛出 MissingFormatWidthException。 如果同时给出 '-' 和 '0' 标志,则将抛出 IllegalFormatFlagsException。 |
|
',' |
'u002c' |
要求输出包括在本地化算法的“群”一节中描述的特定于语言环境的组分隔符。 |
|
'(' |
'u0028' |
要求输出预先考虑 '(' ('u0028'),并将 ')' ('u0029') 追加到负值中。 |
如果没有给出 标志 ,则默认格式设置如下:
width 中的输出是右对齐的
负数以 '-' ('u002d') 开始
正数和零不包括符号或额外的前导空格
不包括组分隔符
The 宽度 是将向输出中写入的最少字符数。这包括所有符号、数字、组分隔符、基数指示符和圆括号。如果转换值的长度小于宽度,则用空格('u0020') 填充输出,直到字符总数等于宽度。默认情况下,在左边进行填补。如果给出 '-' 标志,则在右边进行填补。如果没有指定宽度,则没有最小宽度。
精度不适用。如果指定精度,则将抛出 IllegalFormatPrecisionException。
12.2.4.3.3 BigInteger
以下转换可应用于 BigInteger。
|
'd' |
'u0054' |
要求将输出格式化为十进制整数。应用本地化算法。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'o' |
'u006f' |
要求将输出格式化为以 8 为基数的整数。不应用本地化。 如果 x 为负,那么结果将是以 '-' ('u002d') 开始的有符号值。允许对这种类型使用有符号输出,因为它不同于基本类型,在没有假定显式数据类型大小的情况下,不可能创建无符号的等效值。 如果 x 为正数或零,且给出了 '+' 标志,那么结果是以 '+' ('u002b') 开始的。 如果给出 '#' 标志,那么输出将始终以 '0' 前缀开始。 如果给出 '0' 标志,那么将使用前导零填充输出,这些零被填充到指示符后的字段宽度中。 如果给出 ',' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'x' |
'u0078' |
要求将输出格式化为以 16 为基数的整数。不应用本地化。 如果 x 为负,那么结果是以 '-' ('_apos;) 开始的有符号值。此类型允许使用有符号输出,因为与基本类型不同,如果不假定明确的数据类型大小,则不可能创建无符号的等效数。 如果 x 为正数或零,且给出了 '+' 标志,那么结果以 '+' ('u002b') 开始。 如果给出 '#' 标志,那么输出将始终以基数指示符 '0x' 开始。 如果给出 '0' 标志,那么将使用前导零填充输出,这些零被填充到基数指示符或符号(如果存在)后面的字段宽度中。 如果给出 ',' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'X' |
'u0058' |
'x' 的大写形式。将表示数字的整个字符串转换为大写,其中包括 'x'(如果有的话)和所有十六进制数字 'a' - 'f' ('u0061' - 'u0066')。 |
如果该转换是 'o'、'x' 或 'X',并且给出了 '#' 和 '0' 标志,那么结果将包含基数指示符(对于八进制是 '0',对于十六进制是 '0' 或 "0x")、一定数量的零(基于宽度)和该值。
如果给出 '0' 标志,并且值为负,则在符号后填充零。
如果没有给出 '-' 标志,则在符号前填充空格。
应用为 Byte、Short、Integer 和 Long 定义的所有标志。没有给出标志时的默认行为与 Byte、Short、Integer 和 Long 的行为相同。
宽度的规范与为 Byte、Short、Integer 和 Long 定义的规范相同。
精度不适用。如果指定精度,则将抛出 IllegalFormatPrecisionException。
12.2.4.3.4 Float 和 Double
以下转换可应用于 float、Float、double 和 Double。
|
'e' |
'u0065' |
要求使用科学记数法来格式化输出。应用本地化算法。 数值 m 的格式取决它的值。 如果 m 是 NaN 或无穷大,则分别输出文本字符串 "NaN" 或 "Infinity"。这些值都没有被本地化。 如果 m 是正零或负零,则指数将是 "+00"。 否则,结果是表示变量的符号和大小(绝对值)的字符串。符号的格式在本地化算法中已经描述。数值 m 的格式取决它的值。 让 n 成为满足 10n <= m < 10n+1 的唯一整数;让 a 成为 m 和 10n 的精确算术商数值,且满足 1 <= a < 10。然后将该数值解释为 a 的整数部分,因为是一个小数位数,所以后面跟着小数点分隔符,再后面是表示 a 的小数部分的小数位数,后跟指数符号 'e' ('u0065'),这之后是指数符号,后跟十进制整数形式表示的 n,它由方法 Long.toString(long, int) 产生,并用零填充,使其至少包括两个位数。 在结果中,m 或 a 的小数部分的位数等于精度。如果没有指定精度,则默认值为 6。如果精度小于将出现在分别由 Float.toString(float) 或 Double.toString(double) 返回的字符串中的小数点之后的位数,则使用四舍五入算法对该值进行舍入运算。否则,可能通过追加零来达到所需精度。要获得该值的规范表示形式,请在适当时候使用 Float.toString(float) 或 Double.toString(double)。 如果给出 ',' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'E' |
'u0045' |
'e' 的大写形式。指数符号将是 'E' ('u0045')。 |
|
'g' |
'u0067' |
要求将输出格式化为下面描述的常规科学记数形式。应用本地化算法。 在对精度进行舍入运算后,所得数值 m 的格式取决于它的值。 如果 m 大于等于 10-4 但小于 10精度,则以十进制形式 表示它。 如果 m 小于 10-4 或者大于等于 10精度,则以计算机科学记数法 表示它。 m 中的总有效位数等于其精度。如果没有指定精度,则其默认值为 6。如果精度为 0,则该值将为 1。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'G' |
'u0047' |
'g' 的大写形式。 |
|
'f' |
'u0066' |
要求使用十进制形式来格式化输出。使用本地化算法。 结果是表示参数的符号和大小(绝对值)的字符串。符号的格式在本地化算法中已经描述。数值 m 的格式取决它的值。 如果 m 是 NaN 或无穷大,则将分别输出文本字符串 "NaN" 或 "Infinity"。这些值都没有被本地化。 将数值格式化为 m 的整数部分(不带前导零),后跟小数点分隔符,再后面是表示 m 的小数部分的一个或多个十进制数字。 在结果中,m 或 a 的小数部分的位数等于精度。如果没有指定精度,则默认值为 6。如果该精度小于将要出现在分别由 Float.toString(float) 或 Double.toString(double) 返回的字符串中的小数点之后的位数,则使用四舍五入算法对该值进行舍入运算。否则,可能通过追加零来达到所需精度。要获得该值的规范表示形式,请在适当时候使用 Float.toString(float) 或 Double.toString(double)。 |
|
'a' |
'u0061' |
要求将输出格式化为十六进制指数形式。不应用本地化。 结果是表示参数 x 的符号和大小(绝对值)的字符串。 如果 x 为负值或负零值,那么结果将以 '-' ('u002d') 开始。 如果 x 为正值或正零值,且给出了 '+' 标志,那么结果将以 '+' ('u002b') 开始。 数值 m 的格式取决它的值。 如果该值是 NaN 或无穷大,则将分别输出文本字符串 "NaN" 或 "Infinity"。 如果 m 等于零,则用字符串 "0x0.0p0" 表示它。 如果 m 是具有标准化表现形式的 double 值,则用子字符串来表示有效位数和指数字段。有效位数是用字符串 "0x1." 表示的,后跟该有效位数小数部分的十六进制表示形式。指数用 'p' ('u0070') 表示,后跟无偏指数的十进制字符串,该值是对指数值调用 Integer.toString 所产生的。 如果 m 是具有低正常表现形式的 double 值,则用字符 "0x0." 表示有效位数,后跟该有效位数小数部分的十六进制表示。用 'p-1022' 表示指数。注意,在低正常有效位数中,至少必须有一个非零数字。 如果给出 '(' 或 ',' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'A' |
'u0041' |
'a' 的大写形式。表示数字的整个字符串将被转换为大写形式,其中包括 'x' ('u0078') 和 'p' ('u0070' 以及所有的十六进制数字 'a' - 'f' ('u0061' - 'u0066')。 |
应用为 Byte、Short、Integer 和 Long 定义的所有标志。
如果给出 '#' 标志,则将始终存在小数点分隔符。
如果没有给出 标志 则默认格式设置如下:
width 中的输出是右对齐的。
负数以 '-' 开头
正数和正零不包括符号或额外的前导空格
不包括组分隔符
小数点分隔符只在后面有数字时才出现
The 宽度 是将向输出中写入的最少字符数。这包括可应用的所有符号、数字、组分隔符、小数点分隔符、指数符号、基数指示符、圆括号和表示无穷大和 NaN 的字符串。如果转换值的长度小于宽度,则用空格('u0020') 填充输出,直到字符总数等于宽度。默认情况下,在左边进行填充。如果给出 '-' 标志,则在右边进行填充。如果没有指定宽度,则没有最小宽度。
如果 转换 是 'e'、'E' 或 'f',则精度是小数点分隔符后的位数。如果没有指定精度,则假定精度为 6。
如果转换是 'g' 或 'G' 转换,那么精度就是舍入运算后所得数值的总有效位数。如果没有指定精度,则默认值为 6。如果精度为 0,则该值将为 1。
如果转换是 'a' 或 'A' 转换,则精度是小数点分隔符后十六进制数字的位数。如果没有提供精度,则将输出 Double.toHexString(double) 返回的所有数字。
12.2.4.3.5 BigDecimal
以下转换可应用于 BigDecimal。
|
'e' |
'u0065' |
要求使用计算机科学记数法对输出进行格式化。应用本地化算法。 数值 m 的格式取决于它的值。 如果 m 为正零或负零,则指数将为 "+00"。 否则,结果是表示参数的符号和大小(绝对值)的字符串。符号的格式在本地化算法中已经描述。数值 m 的格式取决于它的值。 让 n 成为满足 10n <= m < 10n+1 的唯一整数;让 a 成为 m 和 10n 的精确算术商数值,且满足 1 <= a < 10。然后将该数值解释为 a 的整数部分,因为是一个小数位数,所以后面跟着小数点分隔符,再后面是表示 a 的小数部分的小数位数,后跟指数符号 'e' ('u0065'),这之后是指数符号,后跟十进制整数形式表示的 n,它由方法 Long.toString(long, int) 产生,并用零填充,使其至少包括两个位数。 在结果中,m 或 a 的小数部分的位数等于精度。如果没有指定精度,则默认值为 6。如果精度小于将出现在分别由 Float.toString(float) 或 Double.toString(double) 返回的字符串中的小数点之后的位数,则使用四舍五入算法对该值进行舍入运算。否则,可能通过追加零来达到所需精度。要获得该值的规范表示形式,请使用 BigDecimal.toString()。 如果给出 ',' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'E' |
'u0045' |
'e' 的大写形式。指数符号将是 'E' ('u0045')。 |
|
'g' |
'u0067' |
要求将输出格式化为下面描述的常规科学记数形式。应用本地化算法。 在对精度进行舍入运算后,所得数值 m 的格式取决于它的值。 如果 m 大于等于 10-4 但小于 10精度,则以十进制形式 表示它。 如果 m 小于 10-4 或者大于等于 10精度,则以计算机科学记数法 表示它。 m 中的总的有效位数等于精度。如果没有指定精度,则默认值为 6。如果精度为 0,则该值将为 1。 如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。 |
|
'G' |
'u0047' |
'g' 的大写形式。 |
|
'f' |
'u0066' |
要求使用十进制形式来格式化输出。应用本地化算法。 结果是表示参数的符号和大小(绝对值)的字符串。符号的格式在本地化算法中已经描述。数值 m 的格式取决于它的值。 将该数值格式化为 m 的整数部分(不带前导零),后跟小数点分隔符,再后面是表示 m 的小数部分的一个或多个十进制数字。 在结果中,m 或 a 的小数部分的位数等于精度。如果没有指定精度,则默认值为 6。如果精度小于将出现在分别由 Float.toString(float) 或 Double.toString(double) 返回的字符串中的小数点之后的位数,则使用四舍五入算法对该值进行舍入运算。否则,可能通过追加零来达到所需精度。要获得该值的规范表示形式,请使用 BigDecimal.toString()。 |
应用为 Byte、Short、Integer 和 Long 定义的所有标志。
如果给出 '#' 标志,则将始终存在小数点分隔符。
没有给出标志时的默认行为与 Float 和 Double 的行为相同。
宽度和精度的规范与为 Float 和 Double 定义的规范相同。
12.2.4.4 日期/时间
此转换可应用于 long、Long、Calendar 和 Date。
|
't' |
'u0074' |
日期和时间转换字符的前缀。 |
|
'T' |
'u0054' |
't' 的大写形式。 |
以下日期和时间转换字符后缀是为 't' 和 'T' 转换定义的。这些类型类似于但不完全等同于 GNU date 和 POSIX strftime(3c) 定义的那些类型。提供其他转换类型是为了访问特定于 Java 的功能(例如,'L' 用于秒中的毫秒)。
以下转换字符用来格式化时间:
|
'H' |
'u0048' |
24 小时制的小时,被格式化为必要时带前导零的两位数,即 00 - 23。00 对应午夜。 |
|
'I' |
'u0049' |
12 小时制的小时,被格式化为必要时带前导零的两位数,即 01 - 12。01 对应于 1 点钟(上午或下午)。 |
|
'k' |
'u006b' |
24 小时制的小时,即 0 - 23。0 对应于午夜。 |
|
'l' |
'u006c' |
12 小时制的小时,即 1 - 12。1 对应于上午或下午的一点钟。 |
|
'M' |
'u004d' |
小时中的分钟,被格式化为必要时带前导零的两位数,即 00 - 59。 |
|
'S' |
'u0053' |
分钟中的秒,被格式化为必要时带前导零的两位数,即 00 - 60("60" 是支持闰秒所需的一个特殊值)。 |
|
'L' |
'u004c' |
秒中的毫秒,被格式化为必要时带前导零的三位数,即 000 - 999。 |
|
'N' |
'u004e' |
秒中的毫微秒,被格式化为必要时带前导零的九位数,即 000000000 - 999999999。此值的精度受底层操作系统或硬件解析的限制。 |
|
'p' |
'u0070' |
特定于语言环境的上午或下午标记以小写形式表示,例如 "am" 或 "pm"。使用转换前缀 'T' 可以强行将此输出转换为大写形式。(注意,'p' 产生的输出是小写的。而 GNU date 和 POSIX strftime(3c) 产生的输出是大写的。) |
|
'z' |
'u007a' |
相对于 GMT 的 RFC 822 格式的数字时区偏移量,例如 -0800。 |
|
'Z' |
'u005a' |
表示时区的缩写形式的字符串。 |
|
's' |
'u0073' |
自协调世界时 (UTC) 1970 年 1 月 1 日 00:00:00 至现在所经过的秒数,也就是 Long.MIN_VALUE/1000 与 Long.MAX_VALUE/1000 之间的差值。 |
|
'Q' |
'u004f' |
自协调世界时 (UTC) 1970 年 1 月 1 日 00:00:00 至现在所经过的毫秒数,即 Long.MIN_VALUE 与 Long.MAX_VALUE 之间的差值。此值的精度受底层操作系统或硬件解析的限制。 |
以下转换字符用来格式化日期:
|
'B' |
'u0042' |
特定于语言环境的完整月份名称,例如 "January" 和 "February"。 |
|
'b' |
'u0062' |
特定于语言环境的月份简称,例如 "Jan" 和 "Feb"。 |
|
'h' |
'u0068' |
与 'b' 相同。 |
|
'A' |
'u0041' |
特定于语言环境的星期几的全称,例如 "Sunday" 和 "Monday" |
|
'a' |
'u0061' |
特定于语言环境的星期几的简称,例如 "Sun" 和 "Mon" |
|
'C' |
'u0043' |
除以 100 的四位数表示的年份,被格式化为必要时带前导零的两位数,即 00 - 99 |
|
'Y' |
'u0059' |
年份,被格式化为必要时带前导零的四位数(至少),例如 0092 等于格里高利历的 92 CE。 |
|
'y' |
'u0079' |
年份的最后两位数,被格式化为必要时带前导零的两位数,即 00 - 99。 |
|
'j' |
'u006a' |
一年中的天数,被格式化为必要时带前导零的三位数,例如,对于格里高利历是 001 - 366。001 对应于一年中的第一天。 |
|
'm' |
'u006d' |
月份,被格式化为必要时带前导零的两位数,即 01 - 13,其中 "01" 是一年的第一个月,("13" 是支持阴历所需的一个特殊值)。 |
|
'd' |
'u0064' |
一个月中的天数,被格式化为必要时带前导零的两位数,即 01 - 31,其中 "01" 是一个月的第一天。 |
|
'e' |
'u0065' |
一个月中的天数,被格式化为两位数,即 1 - 31,其中 "1" 是一个月中的第一天。 |
以下转换字符用于格式化常见的日期/时间组合。
|
'R' |
'u0052' |
24 小时制的时间,被格式化为 "%tH:%tM" |
|
'T' |
'u0054' |
24 小时制的时间,被格式化为 "%tH:%tM:%tS"。 |
|
'r' |
'u0072' |
12 小时制的时间,被格式化为 "%tI:%tM:%tS %Tp"。上午或下午标记 ('%Tp') 的位置可能与地区有关。 |
|
'D' |
'u0044' |
日期,被格式化为 "%tm/%td/%ty"。 |
|
'F' |
'u0046' |
ISO 8601 格式的完整日期,被格式化为 "%tY-%tm-%td"。 |
|
'c' |
'u0063' |
日期和时间,被格式化为 "%ta %tb %td %tT %tZ %tY",例如 "Sun Jul 20 16:17:00 EDT 1969"。 |
应用为常规转换而定义的 '-' 标志。如果给出 '#' 标志,则将抛出 FormatFlagsConversionMismatchException。
宽度 是将向输出中写入的最少字符数。如果转换值的长度小于 width,则用空格('u0020') 来填充输出,直到总字符数等于宽度。默认情况下,在左边进行填充。如果给出 '-' 标志,则在右边进行填充。如果没有指定宽度,则没有最小宽度。
精度不适用。如果指定了精度,则将抛出 IllegalFormatPrecisionException。
/** * 格式化时间 */ @Test public void test1(){ //获取当前时间 Date date = new Date(); System.out.printf("%tR", date); System.out.printf("%tT",date); System.out.printf("%tF", date); }
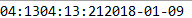
12.2.4.5 %和n
百分比 :该转换不对应于任何参数。
|
'%' |
结果是一个字面值 '%' ('u0025') 宽度 是将向输出中写入的最少字符数,包括 '%'。如果转换值的长度小于 width,则用空格 ('u0020') 来填充输出,直到总字符数等于宽度。在左边进行填充。如果没有指定宽度,则只输出 '%'。 应用为常规转换而定义的 '-' 标志。如果提供其他任何标志,则将抛出 FormatFlagsConversionMismatchException。 精度不适用。如果指定精度,则将抛出 IllegalFormatPrecisionException。 |
行分隔符
该转换不对应于任何参数。
|
'n' |
由 System.getProperty("line.separator") 返回的特定于平台的行分隔符。 |
标志、宽度和精度都不可用。如果提供这三者,则会分别抛出 IllegalFormatFlagsException、IllegalFormatWidthException 和 IllegalFormatPrecisionException。
System.out.printf("%n", "abc");
System.out.printf("%%-5", "abc");

12.2.4.6 参数索引
格式说明符可以通过三种方式引用参数:
显式索引 是在格式说明符中包含参数索引时使用。参数索引是一个十进制整数,用于指示参数在参数列表中的位置。第一个参数由 "1$" 引用,第二个参数由 "2$" 引用,依此类推。可以多次引用任何一个参数。
/** * 参数索引 */ @Test public void test3(){ Formatter formatter = new Formatter(System.out); formatter.format("%3$S%1$s", "aVc","cvb","asd","awe"); }

- 相对索引 是在格式说明符中包含 '<' ('u003c') 标志时使用,该标志将导致重用以前格式说明符的参数。如果不存在以前的参数,则抛出 MissingFormatArgumentException。
formatter.format("%s %s %<s %<s", "a", "b", "c", "d")
// -> "b a a b"
// "c" and "d" are ignored because they are not referenced
- 普通索引 在格式说明符中既不包含参数索引也不包含 '<' 标志时使用。每个使用普通索引的格式说明符都分配了一个连续隐式索引,分配在独立于显式索引或相对索引使用的参数列表中。
formatter.format("%s %s %s %s", "a", "b", "c", "d")
// -> "a b c d"
可能有一个使用所有索引形式的格式字符串,例如:
formatter.format("%2$s %s %<s %s", "a", "b", "c", "d")
// -> "b a a b"
// "c" and "d" are ignored because they are not referenced
参数的最大数量受到 Java Machine Specification 定义的 Java 数组 的最大维数的限制。如果参数索引与可用参数不对应,则抛出 MissingFormatArgumentException。
如果参数多于格式说明符,则忽略额外的参数。 除非另行指定,否则向此类中的任何方法或构造方法传递 null 参数都将抛出 NullPointerException。
11.3 Formatter的构造方法
我们花了很大的篇幅用来介绍Formatter中的转换字符和标志,因为这是格式化赖以存在的根本,我们可以将其理解为一种算法.这节我们将来介绍一下Formatter的构造方法。在介绍Formatter的构造方法之前,我们应该有一个认识,那就是Formatter只是一个用于格式化的类,其自身并不能保存数据,只是一个对数据处理的过程,这就要求了其处理过后对数据要有一个释放的目标地址,而Formatter的构造方法中会要求你在创建一个Formatter对象时,指定其目标输出地址。
Formatter提供了很多的构造方法,如上所说这些构造方法有一个共同点,那就是要求提供一个目标输出,查看我们的API,我们可以看到Formatter的构造方法如下几种,下面我们挨个来介绍一下;
|
Formatter() 构造一个新 formatter。 |
|
Formatter(Appendable a) 构造一个带指定目标文件的新 formatter。 |
|
Formatter(Appendable a, Locale l) 构造一个带指定目标文件和语言环境的新 formatter。 |
|
Formatter(File file, String csn, Locale l) 构造一个带指定文件、字符集和语言环境的新 formatter。 |
|
Formatter(OutputStream os) 构造一个带指定输出流的新 formatter。 |
|
Formatter(OutputStream os, String csn) 构造一个带指定输出流和字符集的新 formatter。 |
|
Formatter(OutputStream os, String csn, Locale l) 构造一个带指定输出流、字符集和语言环境的新 formatter。 |
|
Formatter(PrintStream ps) 构造一个带指定输出流的新 formatter。 |
|
Formatter(String fileName, String csn) 构造一个带指定文件名和字符集的新 formatter。 |
|
Formatter(String fileName, String csn, Locale l) 构造一个带指定文件名、字符集和语言环境的新 formatter。 |
注意:上面我们看到了Appendable ,这是一个接口,它的实现类有以下几种:
BufferedWriter, CharArrayWriter, CharBuffer, FileWriter, FilterWriter, LogStream, OutputStreamWriter, PipedWriter, PrintStream, PrintWriter, StringBuffer, StringBuilder, StringWriter, Writer
而在对Formatter的源代码查看的时候,我们发现其多态传递的是StringBuilder,所以下面,我们将构造方法分为两类来介绍,目标输出为字符序列的和目标输出为输出流的,以及目标输出为文件的。下面我们来介绍一下;
11.3.1 目标输出为字符序列
Formatter提供了四个公共的构造方法,这四个方法确定目标输出为字符序列,如下:
|
Formatter() 构造一个新 formatter。 |
|
Formatter(Appendable a) 构造一个带指定目标文件的新 formatter。 |
|
Formatter(Appendable a, Locale l) 构造一个带指定目标文件和语言环境的新 formatter。 |
下面我们通过代码来看一下,并分析源码结构:
无参构造方法:
/** * 无参构造方法 */ @Test public void test1(){ String str = "12345"; Formatter formatter = new Formatter(); formatter.format("常规格式化:%b", str); System.out.println(formatter.toString());//true }
我们针对其源码进行分析如下图:
private Appendable a;//成员私有,所以提供了一个toString()输出 private final Locale l; private final char zero;
public Formatter() { this(Locale.getDefault(Locale.Category.FORMAT), new StringBuilder()); }
private Formatter(Locale l, Appendable a) { this.a = a; this.l = l; this.zero = getZero(l); }
public String toString() { ensureOpen(); return a.toString(); } private void ensureOpen() { if (a == null) throw new FormatterClosedException(); }
通过指定语言环境:
/** * 通过制定语言环境,常见Formatter对象 */ @Test public void test2(){ Formatter formatter = new Formatter(Locale.CHINA); formatter.format("常规格式化:%b", false); System.out.println(formatter.toString());//false }
public Formatter(Locale l) { this(l, new StringBuilder()); }
通过指定语言环境和目标输出方式:
/** * 通过指定语言环境和目标输出方式: */ @Test public void test4(){ Formatter formatter = new Formatter(new StringBuilder(), Locale.US); formatter.format("常规格式化:%b", false); System.out.println(formatter.toString());//false }
我们发现,前面的无参构造和通过指定语言环境的构造方法底层依赖的都是这个构造方法,实际上Formatter中绝大部分的构造都是依赖该构造方法存在的.
通过指定目标输出方式:
/** * 通过指定目标输出方式: */ @Test public void test5(){ Formatter formatter = new Formatter(new StringBuilder()); formatter.format("常规格式化:%b", false); System.out.println(formatter.toString());//false }
public Formatter(Appendable a) { this(Locale.getDefault(Locale.Category.FORMAT), nonNullAppendable(a)); }
11.3.2 目标输出为文件的
Formatter还提供了用于将格式化结果输出到文件的构造方法,下面我们来认识一下:
|
Formatter(File file, String csn, Locale l) 构造一个带指定文件、字符集和语言环境的新 formatter。 |
|
Formatter(String fileName, String csn) 构造一个带指定文件名和字符集的新 formatter。 |
|
Formatter(String fileName, String csn, Locale l) 构造一个带指定文件名、字符集和语言环境的新 formatter。 |
下面我们来挨个认识一下这些构造方法:
@Test public void test1() throws FileNotFoundException{ Formatter formatter = new Formatter(new File("a.txt")); String str = "测试1"; formatter.format("格式化S:%s", str); formatter.flush(); formatter.close(); }

我们看到格式化后的输出为我们给出的文件地址,并且我们也了解到了Formatter实际上也是一个流,能够实现流的一些操作.
除了我们可以指定目标输出外,还可以指定编码集和语言环境:
@Test public void test2() throws FileNotFoundException, UnsupportedEncodingException{ Formatter formatter = new Formatter("a.txt", "ISO-8859-1", Locale.CHINA); String str = "测试2"; byte[] bytes = str.getBytes("ISO-8859-1"); String str2 = new String(bytes, "GBK"); System.out.println(str2); System.out.println(); formatter.format("格式化S:%s", str); formatter.close(); }

本地环境编码是使用GBK,所以我们看到了乱码,这是编码和解码使用不合理的编码集造成的
11.3.3 目标输出为输出流的
上面我们接触了目标输出为字符序列和文件的,但是实际上我们日常测试中最常见到的却是输出流,如System.out。Formatter提供了很多构造方法,其中目标输出为输出流的,下面我们来认识一下:
|
Formatter(OutputStream os) 构造一个带指定输出流的新 formatter。 |
|
Formatter(OutputStream os, String csn) 构造一个带指定输出流和字符集的新 formatter。 |
|
Formatter(OutputStream os, String csn, Locale l) 构造一个带指定输出流、字符集和语言环境的新 formatter。 |
|
Formatter(PrintStream ps) 构造一个带指定输出流的新 formatter。 |
|
Formatter(Appendable a) 构造一个带指定目标文件的新 formatter。 |
我们注意到最后一个构造方法,我们在11.3.1中介绍过,这是由于Appendable接口的实现类中既有字符序列,又有一些流,所以在这里我们也把其列举出来;
/** * 其实File也是输出流,只是我们将其单独列出介绍 * @throws FileNotFoundException */ @Test public void test2() throws FileNotFoundException{ Formatter formatter = new Formatter(new OutputStreamWriter(new FileOutputStream(new File("./src/a.txt")))); Formatter formatter2 = new Formatter(System.out); formatter.format("格式化:%s", "目标是输出流"); formatter.close(); formatter2.format("格式化:%s", "目标是控制台字符输出流"); Formatter formatter3 = new Formatter(new PrintStream(new FileOutputStream("./src/b.txt"))); formatter3.format("格式化:%s", "目标是输出流"); formatter3.close(); }



如上,我们对Formatter的构造方法进行了讲解,下面我们对Formatter中的方法进行深入了解一下;
11.4 Formatter中的功能方法
Formatter提供格式化功能,那么Formatter类中最重要的就是格式化方法format()了,除此之外,由于Formatter中会将格式化的数据输出到流中,因此会有一个流的刷新和关闭操作;针对字符序列则是toString();除此之外Formatter还提供了一个方法,该方法返回一个输出的目标文件可以是字符序列,也可以是输出流;
除了上面的方法,Formatter还提供额两个不常用的方法.一个用于返回格式化时使用得语言环境,一个是返回返回由此 formatter 的 Appendable 方法上次抛出的 IOException 异常。下面我们我们来对其中的方法进行一些练习和分析;
11.4.1 Formatter中的流刷新和关闭操作
有过IO经验的开发人员会知道,如果要将输出流中的内容输出的话,需要做的是将流中数据刷新到输出流的输出目的地;而这种操作可以有两种方式,一种是先刷新然后再关闭流,另一种是直接关闭流,此时会先在close()进行刷新,然后再关闭;而Formatter中格式化后的数据有两个目的地,一个是字符序列,此时不牵涉到流的操作,我们不考虑。另一个则是将格式化的数据通过输出流输出到目的地,此时需要进行流的相关操作,所以观察API我们发现,Formatter实现了两个接口Closeable和Flushable。实现这两个接口的同时也实现了两个接口中的方法,flush()和close(),而这两个方法动态由相应输出流决定.下面是Formatter中两个方法的源码;
public void flush() { ensureOpen(); if (a instanceof Flushable) { try { ((Flushable)a).flush();//实际的流刷新和关闭操作,由创建Formatter实例时的流参数决定,这是多态的体现 } catch (IOException ioe) { lastException = ioe; } } }
public void close() { if (a == null) return; try { if (a instanceof Closeable) ((Closeable)a).close(); } catch (IOException ioe) { lastException = ioe; } finally { a = null; } }
11.4.2 Formatter中针对字符序列的输出操作
格式化的结果出来流就是字符序列,针对字符序列提供了一个转换为字符串的操作toString();
public String toString() { ensureOpen(); return a.toString(); }
11.4.3 Formatter中的格式化操作方法
Formatter中最重要的就要属其格式化的操作方法了,Formatter中有两个用于格式化的方法,这两个是重载的方法,其实也可以说是一个方法,因为其中一个方法,依赖于另一个方法。下面我们针对这个方法来介绍:
|
Formatter |
format(Locale l, String format, Object... args) 使用指定的语言环境、格式字符串和参数,将一个格式化字符串写入此对象的目标文件中。 |
这个方法中的参数有三个,第一个是语言环境,第二个是格式化规范,第三个则是要格式化的数据。我们在11.2中其实已经有了介绍,这里不再赘述。
11.4.4 Formatter中提供的其它方法
Formatter除了以上的方法,外还有三个其它的方法,一个是获取格式化所需的语言环境的方法;
@Test public void test1(){ Formatter formatter = new Formatter(System.out,Locale.UK);//Local由这里决定,不由format()中传入的参数决定 formatter.format(Locale.US, "时间格式化:%tT ", new Date()); formatter.format(Locale.UK, "字符串格式化:%s ", "修齢"); System.out.println(formatter.locale().toString());//可以看出这个Local是根据你本地的Local决定的 }

用于获取输出目的地的方法out()
@Test public void test2(){ Formatter formatter = new Formatter(System.out,Locale.UK); formatter.format(Locale.US, "时间格式化:%tT", new Date()); PrintStream ps = (PrintStream) formatter.out(); ps.append('!'); ps.close(); }
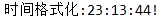
Formatter还提供了一个方法,该方法使用与获取Appendable 方法上次抛出的 IOException 异常。想要了解这个方法,应该首先来了解一下Formatter类中的一个成员字段
private IOException lastException;
该字段用于记录Appendable使用时抛出的异常,实际上,我们每次操作时,在catch中都会有一个赋值运算,将lastException指向catch的Exception,举例如下:
public void close() { if (a == null) return; try { if (a instanceof Closeable) ((Closeable)a).close(); } catch (IOException ioe) { lastException = ioe; } finally { a = null; } }
到了这里关于格式化类,我们认识的也就差不多了,至于遗漏的以后再慢慢补充!