计算机就是个机器,这个机器由CPU、内存、硬盘和输入输出设备组成。计算机上运行着操作系统,操作系统提供对外的接口供各厂商和开发语言,开发运行在其上的驱动和应用程序。
操作系统将时间分成细小的时间碎片,每个时间碎片都单独分配给一个应用程序(进程),并且频繁的切换。只是因为时间碎片很细小,并且切换速度很快,所以看起来就好像虽有的应用程序都在同时执行一样。
对于程序员而言,我们写程序基本不用考虑其他应用程序,只用想好怎么做自己的事情就OK了。不同的应用程序能够实现不同的功能。但是本质上计算机只会执行预先写好的指令而已,这些指令也只是操作数据或者设备。所谓程序基本上就是告诉计算机要操作的数据和执行的指令序列(所以我在一篇文章中写过程序=数据结构+算法),即对什么数据做什么操作。如读文档,就是将数据从磁盘加载到内存,然后CPU处理再将数据返回到内存,内存中的数据输入到输出设备。
基本上,所有的数据都需要先存放在内存中进行处理,程序的很大一部分工作就是操作在内存中的数据。数据在计算机内部都是以二进制存储的,并没有数据类型的概念。这对于程序员而言是很不方便处理的,为了方便操作数据,高级程序语言引入了数据类型和变量的概念。数据类型对数据归类、方便理解和操作,对于Java语言而言数据类型分为基本数据类型和引用数据类型两种,如图4.1所示。在本章节中我们就来认识一下Java中的数据类型;
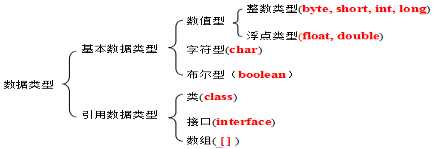
图4.1 Java数据类型
1.1 基本数据类型
在Java中有8种基本数据类型来存储数值、字符和布尔值。这些数据在计算机中或占据不同的存储空间或者是存储不同类型的数据,下面我们来了解一下;
1.1.1 整数类型
整数类型用来存储整数数值,即没有小数部分的数值,也叫定点类型。可以是正数、负数,也可以是0(需要注意的是数学上的0.0和计算机中的0.0不同,数学中的0.0和0是相等的,但是在计算机中0.0和0属于不同的数据类型,前者是浮点类型,而后者是int类型或者其它整数类型)。根据所占内存的大小不同,可以分为byte、short、int和long 4种类型。他们所占的内存和取值范围如表4.2所示。整数默认的类型为int型。整数类型是带符号的数值类型。

图4.2 整数类型(1个字节是8位)
1.1.1.1.byte型
byte类型是有符号数值,使用byte关键字来定义byte型变量,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。byte型是整型中分配内存空间最少的,只分配1个字节,取值范围也是最小的,只在-128~127之间,在使用时一定要注意,以免数据溢出产生错误。
【例4.1】定义byte型变量,并对其进行简单赋值操作,验证其几点要素;
package cn.basic.datatype.bytes;
public class BytePractice{
public static void main(String[] args){
byte a = 45 , b = 127 , c ;
System.out.println(a+b);//整数类型的默认类型为int,所以再给byte类型进行运算时会先将其转换为int类型,然后进行运算
//System.out.println(c); 我们声明了变量却未给其赋值,这里会报未初始化变量,局部变量必须赋值
/* b = 128 ; byte类型的内存空间为1字节,取值范围为-128-127,所以这里会报损失精度的问题,但是仍然可以通过强制转型来解决,结果就是输出与实际数值不符,这是精度损失造成的
System.out.println(b);*/
}
}
注意:成员字段如果没有初始化,那么编译时会自动初始化为默认值。但局部变量如果没有初始化则会在编译时报错“变量未经初始化”;这和类的加载是有关系的,关于类的加载,我们在以后的JVM中再做叙述。
1.1.1.2.Short型
Short型是短整型,使用short关键字来定义short型变量,可以一次定义多个变量并对其赋值,也可以不进行赋值。系统给short型在内存中分配2个字节,取值范围也比byte大得多,在-32768~32767之间,虽然取值范围变大,但仍要注意溢出。
【例4.2】定义short型变量
short a = 23 ; //定义short型变量a、b、c,并赋值给a、b
1.1.1.3.int型
int型即整型,使用int关键字来定义int型变量,可以一次定义多个变量并对其赋值,也可以不进行赋值。int型变量取值范围很大(4个字节),在-2147483648~2147483647之间,足够在一般情况下使用,所以是整数变量中应用最广泛的。int类型也是整数类型的默认类型。这意味着整数类型如果不做说明,那么会自动转换为int类型。
【例4.3】定义int型变量
int a = 23 , b = 78 ; ////定义int型变量a、b、c,并赋值给a、b
1.1.1.4.long型
long型即为长整形,使用long关键字来定义long型变量,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。而在对long型变量进行赋值时结尾必须加上“L”或“l”(因为I和i的大写相似,所以我们一般使用L,便于阅读。),否则将不被认为是long型,而会被默认作为int型处理,这时可能会出现溢出内存的错误,如下图就是一个溢出的错误。所以当数值过大超过int型范围时就用long型,系统分给long型8个字节,取值范围更大,在-9223372036854775808~9223372036854775807之间。

【例4.4】定义long型变量,并对其进行一些分析;
package cn.basic.datatype.longs;
public class LongPractice{
public static void main(String[] args){
long a = 3890 , b; //当我们定义一个变量时如果他的数值超过int的范围,却又不对其进行末尾强制,
//b = 922337203685477 ; 那么程序会将其当做int处理,则会发生错误,提示超出范围
//System.out.println(b); 提示我们数值过大
System.out.println(a);
b = 922337203685477L;
System.out.println(b);
b = 922337203685477l;
System.out.println(b);
//b = 922337203685477 L; 我们在定义long型变量时要注意,初始化的后面紧跟"L"或"l",不能有空格的存在,否则会提示错误
System.out.println(b);
}
}
我们在定义long型数据时末尾最好加L,因为l和1是不好区分的;
上面的四种整数类型在Java程序中有3种表示形式,分别为十进制、八进制、和十六进制。
【例4.5】整数的各型运算
package cn.basic.datatype.integer;
public class IntegerPractice{
public static void main(String[] args){
byte a = 127 ;
short b = 3276 ;
int c = 214748364 ;
long d = 21474836423444L ;
long resultL = a + b + c + d ;
//int resultD = a + b + c + d ;当一个高精度的数据类型向低精度转换时,会报可能损失精度的错误
//int dd = (int)d;
int dd = new Long(d).intValue();
int resultD = a + b + c + dd ;
System.out.println("结果为"+resultL);
System.out.println("结果为"+resultD);
}
}

1.1.2 浮点类型
在计算机系统的发展过程中,曾经提出过多种方法表示实数,但是到目前为止使用最广泛的是浮点表示法。相对于定点数而言,浮点数利用指数使小数点的位置可以根据需要而上下浮动,从而可以灵活地表达更大范围的实数。如上面的4中整数类型都是属于定点类型。浮点类型表示有小数部分的数字。Java语言中浮点类型分为单精度浮点类型(float)和双精度浮点类型(double),它们具有不同的取值范围,如图所示。浮点型默认的类型为double。

1.1.2.1 float型
float型即为单精度浮点型,使用float关键字来定义float型变量,可以一次定义一个或多个变量并对其进行赋值,也可以不进行赋值。在对float型进行赋值时末尾必须加上“f”或“F”,如果不加,系统会将其默认作为double型来处理,float型的取值范围在1.4E-45~3.4028235E38之间。
【例4.6】对float型进行定义;
package cn.basic.datatype.floats;
public class FloatPractice{
public static void main(String[] args){
Float a = 1.4E-45F ;
System.out.print(a);
}
}
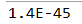
1.1.2.2 double型
double型即双精度浮点型,使用double关键字来定义double型变量,可以一次定义多个变量并对其进行赋值,也可以不进行赋值。在给double型赋值时,可以使用后缀“D”或“d”明确表明这是一个double类型数据,但加不加并没有硬性要求,可以加也可以不加,double型变量的取值范围在4.9E-324和1.2976931348623157E-308之间。
单精度和双精度的区别我们会专门在一篇涉及精度的文章中讲解。
【例4.6】定义一个double型变量和float型变量,并对它们进行赋值、运算和输出;
package cn.basic.datatype.doubles;
class DoublePractice{
public static void main(String[] args){
double a = 987.987123456789012D , b = 789.789879887918799d ;
double c = 68.8978978977 ;
float aa = 987.987123F ; //当我们定义一个float型变量却又不对其进行末尾"F"或"f",那么会提示错误可能损失精度
float d = 987.987123456789012F ;
float e = 987.987153456789012F , f = 987.987144456789012f ;
System.out.println(a+"和"+b) ;
System.out.println(c) ;
System.out.println(aa+"和"+d+"和"+e+"和"+f) ;
}
}

1.1.3 字符类型
在Java的基本数据类型中,我们最难以说清楚的只怕就是char类型了,当然很多开发人员可能不引以为然,认为char不就是单引号括起来的一个字符吗?其实不然,char代表一个字符,可是这个字符却是要存储到计算机中的,这就牵涉到了编码的问题(计算机只能表示数值类型的数据)。Java是使用Unicode作为默认编码的,要想真正弄清楚char,那么我们需要先从Unicode编码讲起。
了解了Unicode,我们就明白了在Java中为什么使用Unicode作为默认的编码集,Char型即字符类型。使用char关键字进行声明,用于存储单个字符,在定义字符型变量时,要用单引号‘’括起来。如‘s’表示一个字符,且单引号中只能有一个字符,多了就不是字符类型,而是字符串类型,需要用双引号进行声明。char类型描述的是UTF-16编码中的一个代码单元(这也就是为什么char需要两个字节的存储空间了)。
与C、C++语言一样,Java语言也可以把字符作为整数对待,由于Unicode编码采用无符号编码,可以存储65536个字符(0x0000~0xffff),所以Java中的字符几乎可以处理所有国家的语言文字。若想得到一个0~65536之间的数所代表的Unicode表中相应位置上的字符,也必须使用char型显式转换。
注意:Java使用Unicode编码,但是要注意这里面的区别,Unicode是一个很大的字符编码集,分为多层,而char使用的是UTF-16编码,所以才有65536这一说。
在字符类型中有一种特殊的字符,以反斜线“”开头,后跟一个或多个字符,具有特定的含义,不同于字符原有的意义,叫做转义字符,Java中的转义字符如下所示。


注意:转义字符也是字符,所以在使用时同样要加‘’单引号。
【例4.7】创建一个类CharPractice,实现将Unicode表中某些位置上的一些字符以及一些字符在Unicode表中的位置在控制台上面输出。
package cn.basic.datatype.ch;
class CharPractice{
public static void main(String[] args){
int a = 'd' , aa = 97 ;
char b = 97 , c = 'a' ;
char d = '\' , e = '' , f = '
' , g = 'u2605' , h = 'u0052' ; //转义字符
char i = 'u4e08';
System.out.println(a+"和"+aa+"和"+b+"和"+c) ;
System.out.println(d+"和"+e+"和"+"和"+g+"和"+h) ;
System.out.println(f) ;
System.out.println(i);
}
}

注意:char描述的只是UTF-16的一个代码单元,不能完全表示Unicode中的所有字符.所以我们在程序中建议使用String.
1.1.4 布尔类型
布尔类型又称逻辑类型,只有“true”和“false”两个值,分别代表布尔逻辑中的“真”和“假”,使用boolean关键字来声明布尔类型变量,通常被用在流程控制中作为判断条件。
【例4.8】声明一个布尔变量,并对其进行输出;
boolean abc = true , cba = false ;
System.out.println(abc+"还是"+cba) ;
if(abc)System.out.println("真就是真!");
else{
System.out.println("假就是假!");
}
if(cba)System.out.println("真就是真!");
else{
System.out.println("假就是假!");
}

1.2 引用数据类型
Java中除了提供基本数据类型外,还提供了引用数据类型,讲起引用数据类型就不得不说面向对象了;
Java是一种面向对象的设计语言,它将具有相同属性和行为的一类事物封装进类中,我们研究的时候只有研究该类的一个抽象个体,这个个体就是对象。对象也是一种数据类型,在内存中分配内存空间,通过引用来访问,这就是引用数据类型,关于引用详见揭秘对象。
Java中引用数据类型和基本数据类型的不同就在于存储的位置和所能实现的功能。基本数据类型根据作用域分为运行时常量池和局部变量表中,而引用类型却是都存放在堆中,基本数据类型只是用来作为运算的数据,而对象则是类的一个实例,其中包含了类中数据的一份copy和功能的实现。所能实现的功能也大相径庭。关于引用类型我们认识到这里也就可以了。
1.3 数据类型转换
类型转换是将一个值从一种类型更改为另一种类型的一个过程。例如,可以将String类型数据“457”转换为一个数值型,而且可以将任意类型的数据转换为String类型。数据类型转换有很多种,这里我们只讲解基本数据类型的转换,至于基本数据类型和引用数据类型的转变(自动拆装箱),后边我们会在其它文章中叙述。
基本数据类型的转换如果从低精度数据类型向高精度数据类型转换,则永远不会溢出,并且总是成功的;而把高精度数据类型向低精度数据类型转换时则必然会提示有精度损失,有可能失败(取决于高精度数据精度是否超过了低精度的最高精度位)。
数据类型转换有两种方式,即隐式转换和显示转换。
1.3.1 隐式数据类型转换
从低精度类型向高精度类型的转换,系统将会自动执行,程序员无需进行任何操作。这种类型的转换称为隐式转换,也叫自动类型转换。下列基本数据类型会涉及数据转换,不包括逻辑类型和字符类型。这些类型按精度从低到高排列顺序为byte < short < int< long < float < double。
注意:byte,short,char之间不会互相转换,他们三者在计算时首先会转换为int类型,有多种类型的数据混合运算时,系统首先自动的将所有数据转换成容量最大的那一种数据类型,然后再进行计算。
【例4.9】将下面int型数据转换为float型数据;
int x = 50 ;
float y = x ;
System.out.println(y) ; //输出的结果为50.0
隐式数据类型转换也需要遵守一定的规则,那么在运算时各个类型之间要怎么转换呢?各种情况下数据类型之间转换一般遵守如下规则。

【例4.10】创建一个类ImplicitConvertPractice,在这个类中声明各种基本数据类型变量,然后进行一系列操作,查看结果。

package cn.basic.datatype.change;
class ImplicitConvertPractice{
public static void main(String[] args){
byte a = 127 ;
short b = 37 ;
char ch = 'a' ;
System.out.println(ch) ;
int xy = a + b + ch ;
System.out.println("当byte short和char一起运算时,他们会先转换为int型在进行计算,因为整数类型默认为int型: " + xy) ;
int x = 50 ;
long c = 922068547 ;
float y = x ;
double d = 92233747.9798698 ;
System.out.println("当byte型和short型在一起运算时其运算结果为:" + (a+b) ) ;
System.out.println("当byte、short型和int型在一起运算时其运算结果为:" + (a+b+x)) ;
System.out.println("当byte、short、int型和long型在一起运算时其运算结果为:" + (a+b+c+x)) ;
System.out.println("当byte、short、int、long型和float型在一起运算时其运算结果为:" + (a+b+x+c+y)) ;
System.out.println("当byte、short、int、long、float型和double型在一起运算时其运算结果为:" + (a+b+c+x+y+d)) ;
}
}

并不是所有的隐式转换都是安全的,隐式转换也要注意精度的问题,如果我们在运算过程中低精度向高精度转换时超出了高精度的取值范围,那么也会造成精度损失的问题,如下代码演示
/** * 隐式转换也不近是安全的 */ @org.junit.Test public void test1(){ int i = Integer.MAX_VALUE - 3; byte b = 4; int a = i + b; System.out.println("i="+i+" b="+b+" a="+a); }
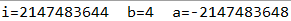
我们看到最后的结果和预想的不一致,这就是运算过程中超出最高精度,造成损失的结果。
1.3.2 显式数据类型转换
当把高精度的变量赋值给低精度的变量时,必须使用显式类型转换(又叫强制类型转换)。语法如下:
(低精度类型名)要转换的值
当我们把一个高精度想一个低精度转换时,不可超出这些变量取值范围,否则会发生数据溢出的现象,此时会造成数据丢失,所以在使用强制类型转换时,一定要加倍小心,不要超出变量的取值范围,否则就得不到的想要结果。比如我们进行一次byte和short之间的显示转换
byte a = 127 ;
short b = 516 ;
byte ab = (byte)b ; //由于short的范围超出了byte的127所以发生溢出,数据损失
System.out.println(ab) ; //结果为4
原理如下:

boolean类型不能被转换为其他类型,反之亦然;
【例4.11】我们创建一个类ExplicitConvertPractice,声明各种数据类型,并对其进行转换操作;
package cn.basic.datatype.change;
class ExplicitConvertPractice{
public static void main(String[] args){
byte a = 127 ;
short b = 516 ;
byte ab = (byte)b ;
byte abc = (byte)(b - a - a - a - a) ;
char ch = 'a' ;
System.out.println(ch) ;
int xy = a + abc + ch ;
System.out.println("当byte short和char一起运算时,他们会先转换为int型在进行计算,因为整数类型默认为int型: " + xy) ;
System.out.println("当数据范围过大时会发生数据损失: "+ ab ) ; //显示转换数据丢失
System.out.println("当数据范围合适时显示转换: "+ abc ) ;
int x = 50 ;
double d = 92247.8698 ;
int bx = (int)(d - x) ;
System.out.println("当double型和int型在一起强制转换时结果为为:" + bx ) ;
boolean boo = false;
//System.out.println((int)boo);
}
}

【例4.12】:分析System.out.println(‘a’)与System.out.println(’a’+1) 的区别;byte b1=3,b2=4,b; b=b1+b2; b=3+4; 哪句是编译失败的呢?为什么呢?
class QuestionPractice{
public static void main(String[] args){
char a = 'a' ;
System.out.println('a') ;//因为字符类型没有参与运算,所以仍以字符类型输出
System.out.println(a);
System.out.println('a'+1) ;//字符类型和一个常量进行运算,字符类型和常量会都先转换为int类型,然后运算
byte b1 = 3 , b2 = 4 , b3 , b4 ;
// b3 = b1 + b2 ; b1和b2是变量,因为变量的值会变化,不确定具体的值,所以默认使用int类型进行存储,他会先自动转换为int型,计算结果为int型,而b3是byte型,是强制转换,
b3 = (byte)(b1 + b2) ;
b4 = 3 + 4 ; //3和4都是常量,所以java在编译时期会检查该常量的和是否超出byte类型的范围。如果没有可以赋值。
System.out.println(b3);
System.out.println(b4);
}
}

分析:当我们声明一个字符变量,并对它进行输出时,那么我们这是输出的就只是一个字符,当我们对着个字符比变量实现运算输出时,那么这时字符会先转换成int型然后计算,结果以int型输出;
1.4 计算机中的默认值
我们知道成员变量是可以只声明不赋值的,但是局部变量却必须声明并赋值才能使用,那么这是为什么呢?这其实和类的加载有关系。关于类的加载,我放在后面JVM中讲解;这里我们只看一下各种数据类型在类加载后的默认值。
package basic.value;
public class Test {
public int i;//所有数值类型默认初始化为0
public static byte bb;
public final byte bbb = 45;//成员如果被final修饰,那么意味着是常量,此时必须赋值
char ch;
short s;
long l;
float f;
double d;//浮点类型默认是0.0
boolean b;//布尔默认false
public static void main(String[] args) {
Test test = new Test();
System.out.println(bb);//静态方法中可以直接调用静态,非静态只能初始化后才能加载
System.out.println(test.s);
System.out.println(test.i);
System.out.println(test.l);
System.out.println(test.ch);
System.out.println(test.f);
System.out.println(test.d);
System.out.println(test.b);
}
}
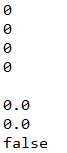
这里没有列出引用类型,但是引用类型如果没有赋值也是有默认值的,引用类型是null;
多学一点:精度问题
在上文我们几次说到了精度的损失问题,这里我特地总结了一篇精度损失的问题来探讨这个问题,可以作为一家之言帮助理解;