接下来要写4篇的进度报告,准备把RDD编程和SparkSQL放在这几天一起弄掉(没回老家的大年三十稍微有些无聊)。
这一篇我想先笼统一下各方面的知识,省的有不理解的地方。
首先是RDD。
作为一个分布式的数据构造,RDD对我来说方法是抽象的,而且一般来说面向我的都是函数式的编程操作,很难体会到RDD真正意义上的数据转换和行动操作,所以通过学习RDD的构造和运转方式可以更好地理解RDD在Spark中的作用。
RDD(Resilient Distributed Dataset) 叫着 弹性分布式数据集。
RDD的特点:
1. 是一个分区的只读记录的集合;
2. 一个具有容错机制的特殊集;
3. 只能通过在稳定的存储器或其他RDD上的确定性操作(转换)来创建;
4. 可以分布在集群的节点上,以函数式操作集合的方式,进行各种并行操作。
另外从名称中得出另外的RDD特点——弹性。
1. 基于Lineage的高效容错(第n个节点出错,会从第n-1个节点恢复,血统容错);
2. Task如果失败会自动进行特定次数的重试(默认4次);
3. Stage如果失败会自动进行特定次数的重试(可以值运行计算失败的阶段),只计算失败的数据分片;
4. 数据调度弹性:DAG TASK 和资源管理无关;
5. checkpoint(检查点);
6. 自动的进行内存和磁盘数据存储的切换。
笼统的了解了特点之后就需要了解构造(如何实现特性)。
来自网络的构造图,显示了RDD的关系和属性——
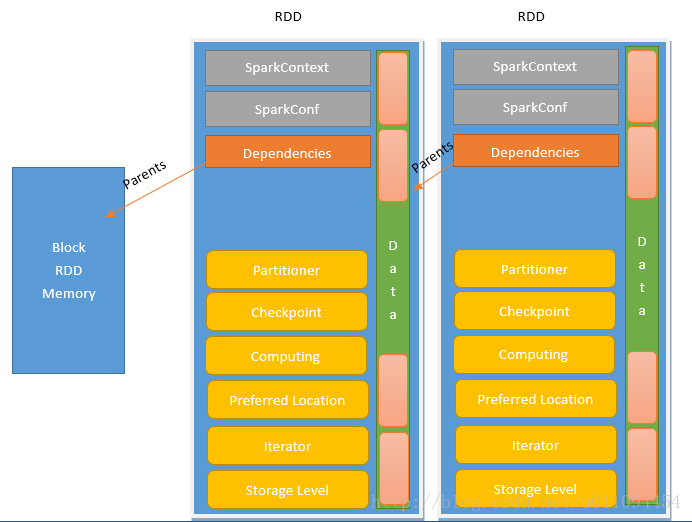
值得一提的是RDD内部并不保存数据。
RDD 只是数据集的抽象,分区内部并不会存储具体的数据。Partition 类内包含一个 index 成员,表示该分区在 RDD 内的编号,通过 RDD 编号 + 分区编号可以唯一确定该分区对应的块编号,利用底层数据存储层提供的接口,就能从存储介质(如:HDFS、Memory)中提取出分区对应的数据。
之后就是SparkSQL中的DataFrame。
SparkSQL作为Spark中的数据仓库,本身甚至拥有了比Spark更快的计算速度、更高的计算复杂度,也就是说甚至可以直接使用到机器学习图计算等复杂的算法库中(这也说明DataFrame和python的深度学习中的一些概念相似)。
Spark中的DataFrame从形式上看最大的不同点是其天生是分布式的。可以简单认为Spark中的DaraFrame是一个分布式的Table。形式如下所述:
|
1
2
3
4
5
6
7
8
|
Name Age Tel
String Int Long
String Int Long
String Int Long
...
String Int Long
String Int Long
String Int Long
|
而RDD是形如以下所述:
|
1
2
3
4
5
6
7
|
Person
Person
Person
...
Person
Person
Person
|
DataFrame 是一个分布式数据容器,更像传统数据库的二维表格,除了数据以外,还掌握数据的结构信息, 即 schema。同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct、 array 和 map)。 从 API 易用性的角度上 看,DataFrameAPI 提供的是一套高层的关系操作,比函数式的 RDDAPI 要更加友好,门槛更低。