背景:
1.抽取不全
https://lemon.baidu.com/a?id=169074&flowSrcId=12004
黄金微雕瘦脸永久吗?做完三个月就开始反弹了 → 'tags': '微雕_1,瘦脸_1' 黄金微雕没有抽取出来
2.抽取词过于宽泛
https://lemon.baidu.com/a?id=26502&flowSrcId=12004
'tags': '迪丽热巴双眼皮_1,整形_1,割双眼皮_1,双眼皮_1' → 整形这个词比较宽泛,不能召回真实的结果
3. 标签粒度较粗,不能较好体现文章的主题
关键词提取流程:
1.LAC进行分词
可以通过加载词表进而可以将词更好的分开。具体的应用可以参考:https://github.com/baidu/lac/tree/master/python
代码如下:
from LAC import LAC
import jieba
MARK_2_name = {"n": u"普通名词", "f": u"方位名词", "s": u"处所名词", "t": u"时间",
"nr": u"人名", "ns": u"地名", "nt": u"机构名", "nw": u"作品名",
"nz": u"其他专名", "v": u"普通动词", "vd": u"动副词", "vn": u"名动词",
"a": u"形容词", "ad": u"副形词", "an": u"名形词", "d": u"副词",
"m": u"数量词", u"q": u"量词", "r": u"代词", "p": u"介词",
"c": u"连词", "u": u"助词", "xc": u"其他虚词", "w": u"标点符号",
"PER": u"人名", "LOC": u"地名", "ORG": u"机构名", "TIME": u"时间"}
lac = LAC()
HAS_MEANING = set([u"人名", u"地名", u"机构名"])
NO_MEANING = set([u"数量词", u"量词", u"代词", u"介词", u"连词", u"助词", u"其他虚词", u"标点符号", u"副词"])
def read(path):
r = []
with open(path) as f:
lines = f.readlines()
for line in lines:
line = line.strip(' ')
r.append(line)
return r
def test_lac(text):
path = '/home/work/limingqi01/limingqi01/extract_tag/yimei.words.txt'
s = read(path)
lac.load_customization(path, sep=None)
res = lac.run(text)
for i, j in zip(res[0], res[1]):
if i in s:
print(i)
其中百度的LAC分词方式,要比jieba分词更好用的多,可以针对具体领域的词进行人为干预,非常适合应用场景。
2.词表扩充:
(1)通过寻找词的同义词或者近义词的方式:
import synonyms
print(synonyms.nearby('隆鼻'))
(2)通过query扩展的方式:调用其接口进行query扩充词表
(3)通过query改写的方式:调用其接口进行query扩充词表
3.图文标签:
参考链接:https://zhuanlan.zhihu.com/p/87128357
参考链接:https://mp.weixin.qq.com/s/CEPBXaJfrIO1w0yX7YdZZA
4.关键词提取方法:
(1)TextRank:
TextRank算法是由网页重要性排序算法PageRank算法迁移而来:PageRank算法根据万维网上页面之间的链接关系计算每个页面的重要性;TextRank算法将词视为“万维网上的节点”,根据词之间的共现关系计算每个词的重要性,并将PageRank中的有向边变为无向边。TextRank算法是由PageRank算法改进而来的,二者的思想有相同之处,区别在于:PageRank算法根据网页之间的链接关系构造网络,而TextRank算法根据词之间的共现关系构造网络;PageRank算法构造的网络中的边是有向无权边,而TextRank算法构造的网络中的边是无向有权边.
(2)tf-idf:
是自然语言处理中的一个简单的模型。tf代表term frequency,也就是词频,而idf代表着inverse document frequency,叫做逆文档频率,这两个属性都是属于单词的属性。概括来说,tf-idf模型是用来给文档中的每个词根据重要程度计算一个得分,这个得分就是tf-idf。
代码实现:
import jieba.analyse
#准备语料
corpus = "《知否知否应是绿肥红瘦》是由东阳正午阳光影视有限公司出品,侯鸿亮担任制片人,"
"张开宙执导,曾璐、吴桐编剧,赵丽颖、冯绍峰领衔主演,朱一龙、施诗、张佳宁、曹翠芬、"
"刘钧、刘琳、高露、王仁君、李依晓、王鹤润、张晓谦、李洪涛主演,王一楠、"
"陈瑾特别出演的古代社会家庭题材电视剧"
#textrank
keywords_textrank = jieba.analyse.textrank(corpus)
print(keywords_textrank)
#tf-idf
keywords_tfidf = jieba.analyse.extract_tags(corpus)
print(keywords_tfidf)
参数设置:
sentence:待提取关键词的语料
topK: 提取多少个关键词,默认为20个
withWeight: 若为True,返回值形式为(word, weight)。若为False,返回的只有words,默认为False
allowPOS: 允许哪些词性作为关键词,默认的词性为’ns’, ‘n’, ‘vn’, ‘v’
withFlag: 若为True,返回值形式为(word, pos)。若为False,返回的只有words,默认为False。其中pos为词性。
优缺点:上面两种算法还是需要结合具体的应用场景进行比较,算法的结果可能会不尽人意,需要建立完善的词表,需要进行多个算法结果的评估,
才能给出更有应用价值的标签,标签是非常基础的工作,基础工作做到极致,在推荐和搜索中才能起到很好的作用。
5.内容tag的具体应用:
例子:
Title:做双眼皮老了会怎样?
Content:很多人认为年轻的时候【割双眼皮】,会随着年龄的增【长脸】型的变化影响双眼皮的形状。有的爱美者在做完双眼皮多年后,
会发现自己的双眼皮好像消失了,其实是变成了内双。很多求美者担心老了以后双眼皮会出现后遗症,做的双眼皮是否成功,术后会
很快显现出来,只要术中医生技术过关,这些问题都可以避免。人老以后都会出现下垂的状况。
在上面这个问答中,标红的和【】括起来的都是医美词,【】括起来的不仅仅是医美词,同时也是标签词。而我们的任务就是
给例如上面的这个物料打上标签(例如【割双眼皮】、【长脸】),并排除置信度不高的标签(例如【长脸】)。
一个简单的打标签方式是将医美词典加入分词器(jieba, lac等等)然后对物料进行分词,遍历找出其中的标签,并以词频作为
其权重。但这样有问题,因为物料讲的是割双眼皮的事,但标签【割双眼皮】和【长脸】将有相同的权重(词频一样)。因此需要对
这样的打标签方式进行改进。
(1)基于相关词增强的标签抽取
1.1 保守的增强策略
所谓保守的增强策略指的是:即只有当标签词能匹配上时才用其相关词增强该标签词。
针对上面的问题,我们提出了基于相关词增强的标签打法。我们可以通过在大量物料上训练词向量,并通过词向量相似度找出
每个标签词的相关词。然后利用相关词增强标签词。
例如【割双眼皮】的相关词为:
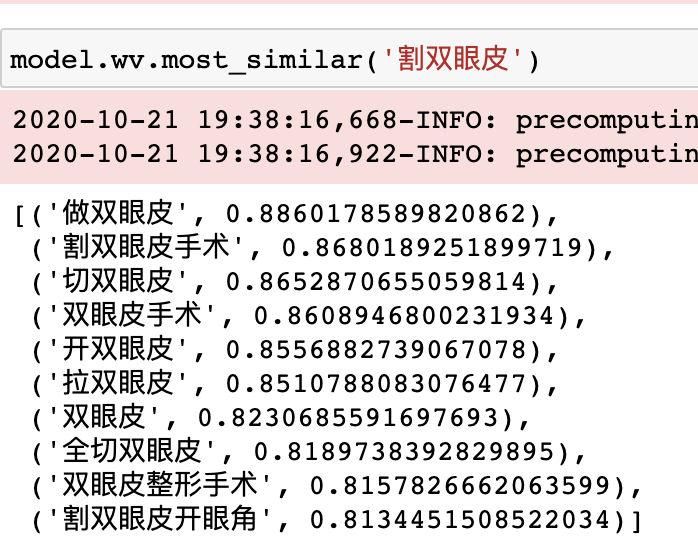
而【长脸】的相关词是:

这样一来,只要标签词的相关词在物料中,那么我们就可以用其相关词来增强它的权重。
Title:做双眼皮老了会怎样?
Content:
很多人认为年轻的时候【割双眼皮】,会随着年龄的增【长脸】型的变化影响双眼皮的形状。有的爱美者在做完双眼皮多年后,
会发现自己的双眼皮好像消失了,其实是变成了内双。很多求美者担心老了以后双眼皮会出现后遗症,做的双眼皮是否成功,术后会
很快显现出来,只要术中医生技术过关,这些问题都可以避免。人老以后都会出现下垂的状况。
其中做双眼皮, 双眼皮, 做完双眼皮都是标签词【割双眼皮】的相关词。而【长脸】在本文中并无相关词,因此,我们更倾向于把
【割双眼皮】作为其标签。我们设计了一个用相关词增强标签词的权重计算公式。如下:
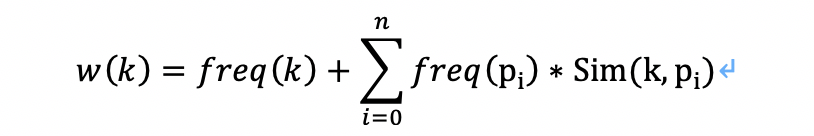
其中, k是标签词。 freq(·)是词频函数,即返回一个词的词频。 n是所有该文本中出现的k的相关词个数。pi表示k的第i个相关词
Sim(·) 为cos相似度函数。
1.2 激进的增强策略
所谓激进的增强策略指的是:即无论标签词能否匹配上,都用已经匹配上的相关词召回并增强标签词。
这需要我们构建从相关词到标签词的映射。这很容易。略~
此时,我们只需找出物料中的相关词,然后用它召回标签词,假如多个相关词召回同一个标签词(权重为),那么该标签词
的权重就是这几个召回的标签词权重之和。值得注意的是在这样的策略下,能大幅度提高标签覆盖率,但也导致打的标签过泛。
1.3 词向量训练
我们在多达400W+的物料上训练了不下10个词向量模型,包括Fasttext, Skip-Gram, Cbow模型。其中Fasttext表现较好,且
能较好处理OOB的情况,故选用。最终参数设置为:
(词向量维度:100, 迭代次数:20, 窗口大小:5,最小词长:1, 最大词长:6, 词最小出现次数:5)
(2)基于推荐的标签抽取
我们可以将打标签这个任务抽象为标签推荐,对于一个物料(医美内容),我们可以找出其中的医美词。我们的目的是为
物料打上标签,然而,并非所有医美词都是标签词。我们可以根据物料中包含的医美词,给物料『推荐』相应的标签词,这就
将打标签任务转换成了推荐任务。我们需要优化的就是如何给物料推荐最符合的标签词。
2.1 用协同过滤法抽取标签
一种简单的基于推荐的标签抽取是基于协同过滤的标签抽取。其核心思想是:
-
包含医美词A的物料中有多少比例的物料也包含医美词B,若包含A的物料中大部分也包含B,那可以认为A和B较为相似
-
得到了相似度之后可以利用推荐系统的思路给物料打上标签。
2.1.1 计算医美词之间的相似度
假设包含医美词 a 的物料数为 N(a),包含医美词 b 的物料数为 N(b),那么 a 与 b 的相似度为:
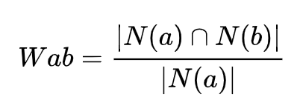
上述公式可以理解为包含医美词 a 的物料中,有多少比例的物料也包含 b,比例越高,说明 a 与 b 的相似度越高。但是这样的公式
有一个问题,如果医美词 b 很热门,很多物料都包含,那么相似度就会无限接近1,这样就会造成所有的医美词拿出来,都与 b 有
极高的相似度,这样就没有办法证明医美词之间的相似度是可靠的了。为了避免出现类似的情况,可以通过以下公式进行改进:
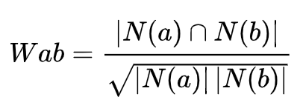
2.1.2 物料打标签
获得了医美词之间的相似度后,根据以下公式来计算标签 b在物料 u 上的得分:
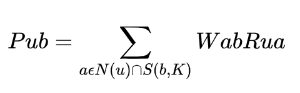
其中,N(u)是物料包含的医美词集合,S(b,K)是和医美词 b 最相似的前 K 个医美词的集合,Wab 是医美词 a 和 b 的相似度,Rua 是
医美词 a 在物料 u 中的词频(反应了a在物料u中的重要程度)。根据最终的标签在物料上的得分,我们会选取得分最高的几个标签
作为物料的标签。