高级软工结对第二次作业
github项目地址
需求分析
本次结对项目对最终程序的功能要求如下:
编码实现一个部门与学生的智能匹配的程序。
实现一个智能自动分配算法,根据输入信息,输出部门和学生间的匹配信息(一个学生可以确认多个他所申请的部门,一个部门可以分配少于等于其要求的学生数的学生) 及未被分配到学生的部门和未被部门选中的学生。
本项目的关键在于设计一个智能匹配算法,该算法主要实现根据输入的学生和部门数据,输出符合部门要求的匹配名单。现从部门角度做出如下需求分析:
- 优先考虑将本部门作为第一部门意愿的学生
- 优先考虑空闲时间段和本部门常规活动时间段相符程度大的学生
- 综合考虑学生空闲时间与本部门常规活动时间符合度、兴趣标签与本部门特点标签符合度、绩点高低
数据模型
模型的分析与建立
根据需求分析建立如下数据模型:
- 部门数据模型:
| 字段 | 数量(个) | 类型 |
|---|---|---|
| 部门名称 | 1 | 字符 |
| 人数上限 | 1 | 数值 |
| 特点标签 | 1-5 | 字符 |
| 常规活动时间 | 1-5 | 字符 |
| 录取学生名单 | 1 | 字符 |
注:其中录取学生名单 字段取值由匹配算法产生
部门数据模型样例:
| 部门名称 | 人数上限 | 特点标签 | 常规活动时间 | 录取学生名单 |
|---|---|---|---|---|
| 活动部 | 14 | 看电影,跳舞 | Sun,20:30,21:00;Tue,19:30,20:00;Fri,20:30,23:00 | 沈剑伸,杨伸世 |
- 学生数据模型:
| 字段 | 数量(个) | 类型 |
|---|---|---|
| 学号 | 1 | 字符 |
| 姓名 | 1 | 字符 |
| 绩点 | 1 | 数值 |
| 意愿部门 | 1-5 | 字符 |
| 意愿部门数 | 1 | 数值 |
| 未匹配意愿数 | 1 | 数值 |
| 兴趣标签 | 1-5 | 字符 |
| 空闲时间 | 1-5 | 字符 |
| 各部门综合得分 | 1-20 | 数值 |
注:其中意愿部门数、未匹配意愿数 、各部门综合得分 字段取值由匹配算法产生
学生数据模型样例:
| 学号 | 姓名 | 绩点 | 意愿部门 | 意愿部门数 | 未匹配意愿数 | 兴趣标签 | 空闲时间 | 各部门综合得分 |
|---|---|---|---|---|---|---|---|---|
| 170312369 | 沈剑伸 | 1.07 | 策划部,权益部,客服部,外联部 | 4 | 0 | 策划,乒乓球,学习 | Fri,22:30,23:30;Sat,19:30,20:00 | 25.07,30,26,28 |
注:由于时间段为随机产生,为避免部门常规时间与所有学生的空闲时间都无法匹配的情况,将时间段限制在19:00-23:00
代码规范
规定在编程过程中须严格遵循以下规范:
- 对于代码的各个功能和参数进行了详细注释
- 变量以及函数命名的规范:使用驼峰命名法进行命名
- 使用类来封装面向对象的概念
代码佐证如下:
class Department
{
public:
Department(string name, string limitNum, string feature, string normalDate)
{
setLimitNum(limitNum);
setFeature(feature);
setNormalDate(normalDate);
setName(name);
}
private:
string name; //部门名称
int limitNum; //人数上限
int existing; //已选人数
vector<string> feature; //特点标签
vector<vector<float>> normalDate; //常规活动时间
vector<Student> stuList;//创建被录取学生名单
public:
void setLimitNum(string limitNum);
void setExisting();
void setFeature(string feature);
void setNormalDate(string normalDate);
void addMember();
void setName(string name);
string getName();
int getExisting();
int getLimitNum();
vector<vector<float>> getNormalDate();
vector<string>getFeature();
friend vector<float> timeCut(string normalDate);
friend vector<string> slice(string s, const char* b);
void setStu(Student s);
vector<Student> getStu();
};
匹配算法
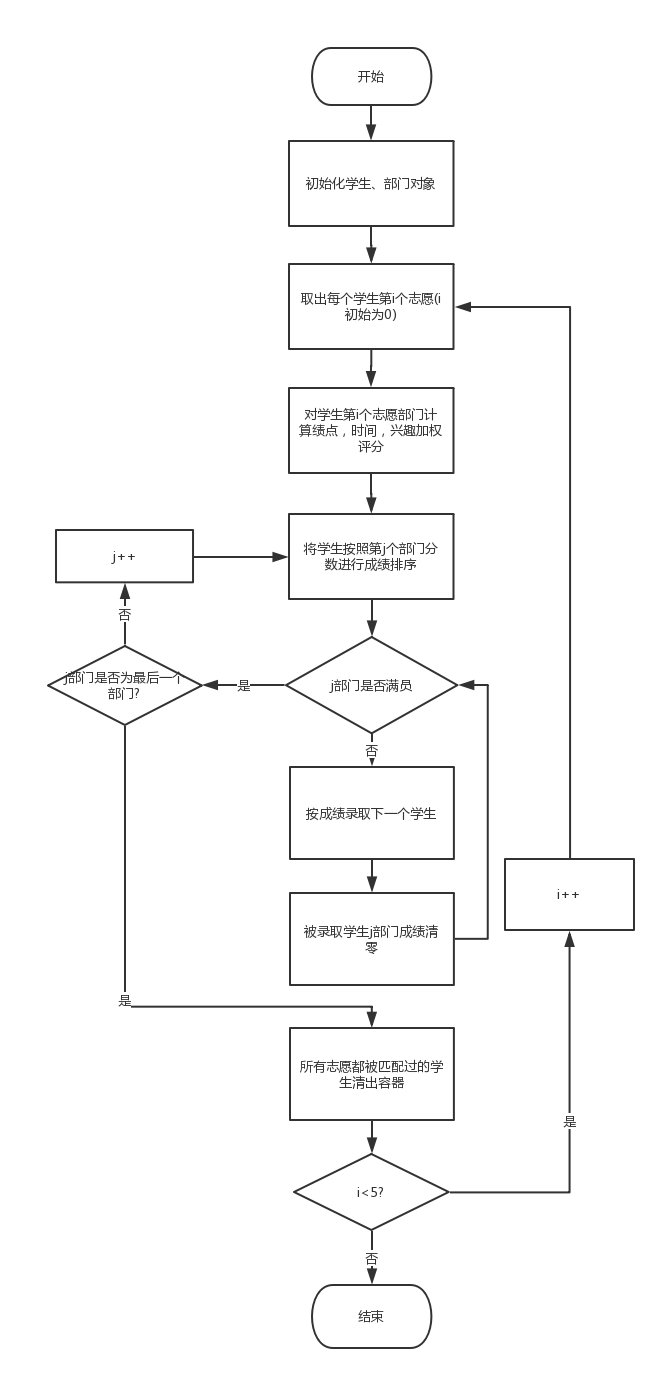
算法描述
- 遍历所有学生的第i(1-5)志愿部门并计算第一志愿对应的部门综合得分
- 以第i(1-5)志愿得分为依据进行降序排序后进行录取(将录取学生加入录取学生名单)
- 循环执行以上步骤直到所有部门录取人数达到上限(每个部门最多15人)或所有学生志愿(每个学生最多5个)均已计算过得分
算法流程如下图:
算法分析
本算法结合部门需求,从实际出发,模拟现实生活中部门招新过程,即每个部门最先匹配的是第一志愿填报本部门的学生,根据学生信息进行评估录取,若录取人数未达到上限则进行第二轮录取,即开始遍历学生的第二志愿。即考虑以下两条原则:
- 志愿优先
- 综合得分优先
关键代码
匹配算法的关键代码如下:
void Match::start()
{
//遍历5个志愿
for (int i = 0; i < 5; i++)
{
//学生对象遍历
vector<Student>::iterator stuIter = stu.begin();
while (stuIter != stu.end())
{
//匹配学生第i志愿部门,进行对应的匹配评分
string intent = stuIter->getIntentDepart()[i];
if (intent == "")
{
stuIter->setNotMatch();
matchOver.push_back(*stuIter);
stuIter = stu.erase(stuIter);
continue;
}
vector<Department>::iterator Iter = dep.begin();
//查找到学生第i志愿部门对象
while (Iter != dep.end())
{
Iter->getName();
if (Iter->getName() == intent)
{
break;
}
Iter++;
}
//将绩点作为成绩的一部分算入匹配分数
stuIter->changeMark(intent, stuIter->getGpa());
//如果学生空闲时间和部门活动时间完全不匹配则分数归零,匹配下一学生的志愿
timeMatch(*stuIter, *Iter);
//匹配兴趣标签并打分
tagMatch(*stuIter, *Iter);
//学生未匹配志愿减一
stuIter->setNotMatch();
stuIter++;
}
vector<Department>::iterator depIter = dep.begin();
//在第i个志愿下,按照不同部门对学生分别进行分数排序,取出每个部门对应的成绩非零的同学加入部门
while (depIter != dep.end())
{
order(stu, depIter->getName());
stuIter = stu.begin();
while (stuIter != stu.end())
{
if (depIter->getExisting() == depIter->getLimitNum() || !stuIter->getMark(depIter->getName()))
{
stuIter++;
continue;
}
depIter->setStu(*stuIter);
stuIter->setMarkZero(depIter->getName());
depIter->setExisting();
stuIter->setAccess();
//如果学生所有志愿完成匹配,则转移学生对象至matchOver容器
if (!stuIter->getNotMatch())
{
matchOver.push_back(*stuIter);
stuIter = stu.erase(stuIter);
}
else
{
stuIter++;
}
}
depIter++;
}
}
}
结果分析评价
测试报告
根据以上算法形成的算法测试报告如下:
| 优先条件 | 匹配学生个数 | 未匹配学生个数 | 实际耗时(s) | 输出文件路径 |
|---|---|---|---|---|
| 志愿优先 | 192 | 108 | 29.313 | 文件路径 |
性能分析
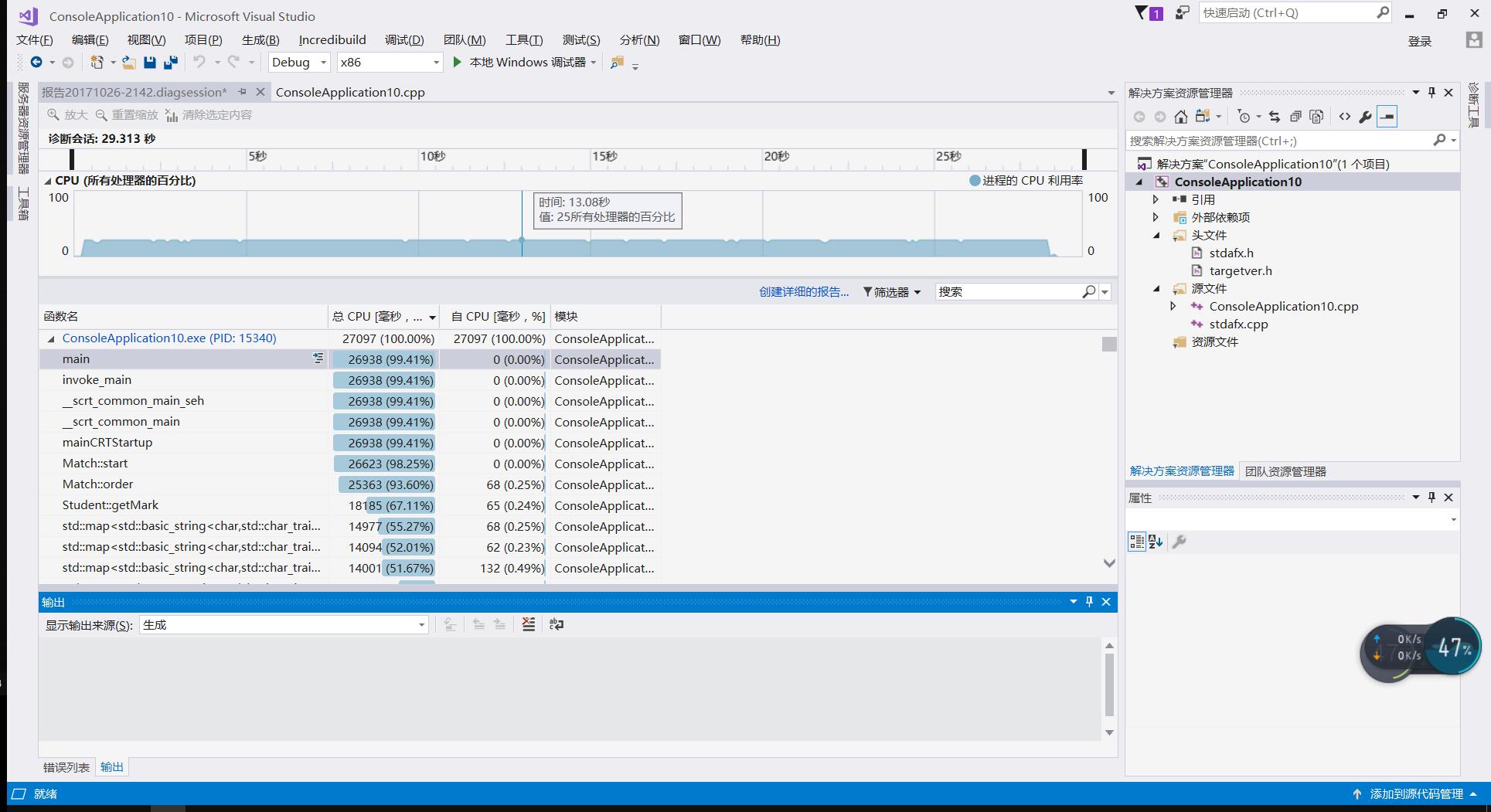
性能分析结果如上图所示,排序占用了93.60%的时间,不出意外的占用了大部分时间,因为这里采用了冒泡排序的方法。如果改进排序方法,程序性能可能取得进一步的提升。
结果分析
该算法对于不同优先条件变更的适应能力很好,对于不同的优先条件,我们只需要调整对应条件的评分权重,使该条件的得分足够大即可,所以改动也只需要几分钟而已。
结对感受
林翔的结对感受
林翔的结对感受:本次的作业极大的锻炼了我的代码能力。在与李明皇的结对过程中,感受到了他的认真严谨的态度。在设计算法模型和敲代码时我们经常发生争论,但是最后都能很好的解决问题。
李明皇的结对感受
本次结对项目所给的时间有点紧,还好这几天课比较少,不然可能完成不了。时间主要花在了算法设计和最后的debug上。
以前对C++的实践主要停留在做题的层面上,在真正的编程中发现了在题目中学不到的东西,比如代码的规范性对编程效率起到了很大的作用,好的规范会使代码review事半功倍。
队友林翔在结对编程中很给力,他的逻辑思维一直很清晰,对于整个算法的把握了然于胸,能够很快的想到我没有考虑的地方并给出解决方案。