为什么要分表
首先要知道什么情况下,才需要分表个人觉得单表记录条数达到百万到千万级别时就要使用分表了,分表的目的就在于此,减小数据库的负担,缩短查询时间.
表分割有两种方式:
1水平分割:根据一列或多列数据的值把数据行放到两个独立的表中。
水平分割通常在下面的情况下使用:
表很大,分割后可以降低在查询时需要读的数据和索引的页数,同时也降低了索引的层数,提高查询速度。
表中的数据本来就有独立性,例如表中分别记录各个地区的数据或不同时期的数据,特别是有些数据常用,而另外一些数据不常用。
需要把数据存放到多个介质上。
水平分割会给应用增加复杂度,它通常在查询时需要多个表名,查询所有数据需要union操作。在许多数据库应用中,这种复杂性会超过它带来的优点,因为只要索引关键字不大,则在索引用于查询时,表中增加两到三倍数据量,查询时也就增加读一个索引层的磁盘次数。
2垂直分割:把主码和一些列放到一个表,然后把主码和另外的列放到另一个表中。
如果一个表中某些列常用,而另外一些列不常用,则可以采用垂直分割,另外垂直分割可以使得数据行变小,一个数据页就能存放更多的数据,在查询时就会减少I/O次数。 其缺点是需要管理冗余列,查询所有数据需要join操作。
场景案例:
博客系统
垂直分割:
文章标题,作者,分类,创建时间等,是变化频率慢,查询次数多,而且最好有很好的实时性的数据,我们把它叫做冷数据。
而博客的浏览量,回复数等,类似的统计信息,或者别的变化频率比较高的数据,我们把它叫做活跃数据。
所以,在进行数据库结构设计的时候,就应该考虑分表,首先是纵向分表的处理。
这样纵向分表后:
首先存储引擎的使用不同,冷数据使用MyIsam 可以有更好的查询数据。活跃数据,可以使用Innodb ,可以有更好的更新速度。
其次,对冷数据进行更多的从库配置,因为更多的操作是查询,这样来加快查询速度。对热数据,可以相对有更多的主库的横向分表处理。
其实,对于一些特殊的活跃数据,也可以考虑使用memcache ,redis之类的缓存,等累计到一定量再去更新数据库.
水平分割:
当博客的量达到很大时候,就应该采取横向分割来降低每个单表的压力,来提升性能。
例如博客的冷数据表,假如分为100个表,当同时有100万个用户在浏览时,如果是单表的话,会进行100万次请求,而现在分表后,就可能是每个表进行1万个数据的请求(因为,不可能绝对的平均,只是假设),这样压力就降低了很多很多。
mysql分表的方法: http://blog.csdn.net/heirenheiren/article/details/7896546
使用Merge存储引擎展示水平分表实例:
查看mysql的存储引擎
mysql> show engines G;
现实场景模拟
第一步: 创建表member
DROP table IF EXISTS member;
create table member(
id bigint auto_increment primary key,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
第二步:创建存储过程,插入百万数据

#如果存在已定义的存储过程inserts,删除掉
drop procedure IF EXISTS inserts;
#自定义结束符
delimiter //
#创建存储过程
create procedure inserts()
begin
DECLARE i int;
set i = 1;
WHILE(i <= 10) DO
insert into member(name,sex) values(concat('name',i),i%2);
SET i = i+1;
END WHILE;
end;
#使用自定义结束符结束存储过程定义
//
#还原结束符为;
delimiter ;
#调用存储过程
call inserts();
MySQL的语法默认使用分号";"作为一条SQL语句结束的标志.可以使用delimiter命令将其修改成其他符号,如:"delimiter //" 表示以//作为提交符号.
为了演示分表,所以实例中插入10条数据模拟.
第三步:创建分表
#分表1#
DROP table IF EXISTS tb_member1;
create table tb_member1(
id bigint primary key auto_increment ,
name varchar(20),
sex tinyint not null default '0'
)ENGINE=MyISAM DEFAULT CHARSET=utf8 AUTO_INCREMENT=1 ;
#分表2#
DROP table IF EXISTS tb_member2;
#复制表1
create table tb_member2 like tb_member1;
第四步:创建主表,这里主表的定义与要分的目标表有不同
#主表#
DROP table IF EXISTS tb_member;
create table tb_member(
id bigint auto_increment ,
name varchar(20),
sex tinyint not null default '0',
INDEX(id)
)ENGINE=MERGE UNION=(tb_member1,tb_member2) INSERT_METHOD=LAST AUTO_INCREMENT=1 ;
查询tb_member表的索引信息
mysql> show index from tb_member G;
第五步:将目标表数据分到两个分表中去
INSERT INTO tb_member1(tb_member1.id,tb_member1.name,tb_member1.sex)
SELECT member.id,member.name,member.sex
FROM member where member.id%2=0 ;
INSERT INTO tb_member2(tb_member2.id,tb_member2.name,tb_member2.sex)
SELECT member.id,member.name,member.sex
FROM member where member.id%2=1 ;
当然实际场景根据需要进行唯一标识操作,取hash啊什么的等等,这里只使用简单去求模分表.
第六步: 查看分表数据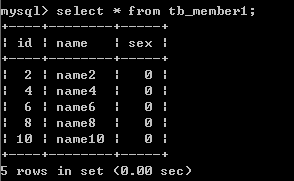
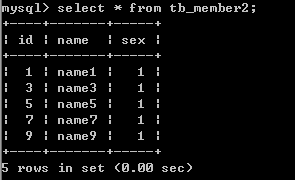
第七步: 查看总表数据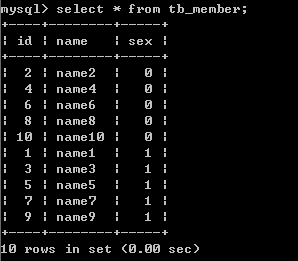
这样就把表member中的数据分开了, 分成的表组为 tb_member为主表,tb_member1与tb_member2为分表.分表后,数据都是存放在分表里,总表只是一个外壳,存取数据发生在一个一个的分表里面。
对于merge表,需要注意的是
1. 每个子表的结构必须一致,主表和子表的结构需要一致,
2. 每个子表的索引在merge表中都会存在,所以在merge表中不能根据该索引进行唯一性检索。
3. 子表需要是MyISAM引擎
4. REPLACE在merge表中不会工作
5. AUTO_INCREMENT 不会按照你所期望的方式工作
创建Mysql Merge表的参数 INSERT_METHOD有几个参数 。
LAST 如果你执行insert 指令来操作merge表时,插入操作会把数据添加到最后一个子表中。
FIRST 同理,执行插入数据时会把数据添加到第一个子表中。