一,Mysql数据库中一个表里有一千多万条数据,怎么快速的查出第900万条后的100条数据?
怎么查,谁能告诉我答案?有没有人想着,不就一条语句搞定嘛
select * from table limit 9000000,100;
那我们试试,去执行下这个SQL看看吧
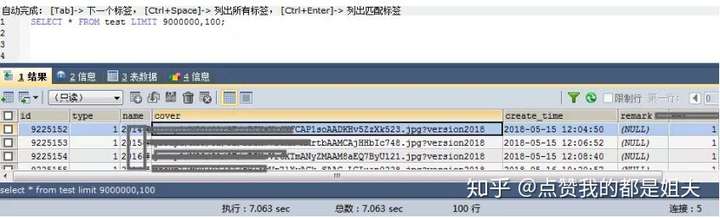
看见了吗,查了100条数据用了7.063s。这能算的上是快速查询吗,估计没人能接受了这种速度吧!基于这个问题,我今天就要说说大数据时的快速查询了。
首先,我演示下大数据分页查询,我的test表里有1000多万条数据,然后使用limit进行分页测试:select * from test limit 0,100;
耗时:0.005s
select * from test limit 1000,100;
耗时:0.006s
select * from test limit 10000,100;
耗时:0.013s
select * from test limit 100000,100;
耗时:0.104s
select * from test limit 500000,100;
耗时:0.395s
select * from test limit 1000000,100;
耗时:0.823s
select * from test limit 5000000,100;
耗时:3.909s
select * from test limit 10000000,100;
耗时:10.761s
我们发现一个现象,分页查询越靠后查询越慢。这也让我们得出一个结论:
1,limit语句的查询时间与起始记录的位置成正比。
2,mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
对大数据量limit分页性能优化
说到查询优化,我们首先想到的肯定是使用索引。利用了索引查询的语句中如果条件只包含了那个索引列,那在这种情况下查询速度就很快了。因为利用索引查找有相应的优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
我的test表使用InnoDB作为存储引擎,id作为自增主键,默认为主键索引。那我们现在用覆盖索引查询,看看效果如何:
SELECT id FROM test LIMIT 9000000,100;
总耗时4.256s,相对于7.063s少了很多。
现在优化的方案有两种,即通过id作为查询条件使用子查询实现和使用join实现;
1,id>=的(子查询)形式实现
select * from test where id >= (select id from test limit 9000000,1)limit 0,100
耗时 4.262s;
2,使用join的形式;
SELECT * FROM test a JOIN (SELECT id FROM test LIMIT 9000000,100) b ON a.id = b.id
耗时 4.251s;这两种优化查询使用时间比较接近,其实两者用的都是一个原理,所以效果也差不多。但个人建议最好使用join,尽量减少子查询的使用。注:目前是千万级别查询,如果将至百万级别,速度会更快,我有亲自测试一下语句,查询时间0.410s。
SELECT * FROM test a JOIN (SELECT id FROM test LIMIT 1000000,100) b ON a.id = b.id
二,你用过mysql那些存储引擎,他们都有什么特点和区别?
这是高级开发者面试时经常被问的问题。实际我们在平时的开发中,经常会遇到的,在用SQLyog等工具创建表时,就有一个引擎项要你去选。如下图:

Mysql的存储引擎有这么多种,实际我们在平时用的最多的莫过于InnoDB和MyISAM了。所有如果面试官问道mysql有哪些存储引擎,你只需要告诉这两个常用的就行。那他们都有什么特点和区别呢?MyISAM:默认表类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的顺序访问方法) 的缩写,它是存储记录和文件的标准方法。不是事务安全的,而且不支持外键,如果执行大量的select,insert MyISAM比较适合。InnoDB:支持事务安全的引擎,支持外键、行锁、事务是他的最大特点。如果有大量的update和insert,建议使用InnoDB,特别是针对多个并发和QPS较高的情况。注:在MySQL 5.5之前的版本中,默认的搜索引擎是MyISAM,从MySQL 5.5之后的版本中,默认的搜索引擎变更为InnoDB。MyISAM和InnoDB的区别:
- InnoDB支持事务,MyISAM不支持。对于InnoDB每一条SQL语言都默认封装成事务,自动提交,这样会影响速度,所以最好把多条SQL语言放在begin和commit之间,组成一个事务;
- InnoDB支持外键,而MyISAM不支持。
- InnoDB是聚集索引,使用B+Tree作为索引结构,数据文件是和(主键)索引绑在一起的(表数据文件本身就是按B+Tree组织的一个索引结构),必须要有主键,通过主键索引效率很高。MyISAM是非聚集索引,也是使用B+Tree作为索引结构,索引和数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描。而MyISAM用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快。
- Innodb不支持全文索引,而MyISAM支持全文索引,查询效率上MyISAM要高;5.7以后的InnoDB支持全文索引了。
- InnoDB支持表、行级锁(默认),而MyISAM支持表级锁。;
- InnoDB表必须有主键(用户没有指定的话会自己找或生产一个主键),而Myisam可以没有。
- Innodb存储文件有frm、ibd,而Myisam是frm、MYD、MYI。
- Innodb:frm是表定义文件,ibd是数据文件。
- Myisam:frm是表定义文件,myd是数据文件,myi是索引文件。
三,Mysql复杂查询语句的优化,你会怎么做?
说到复杂SQL优化,最多的是由于多表关联造成了大量的复杂的SQL语句,那我们拿到这种sql到底该怎么优化呢,实际优化也是有套路的,只要按照套路执行就行。复杂SQL优化方案:
- 使用EXPLAIN关键词检查SQL。EXPLAIN可以帮你分析你的查询语句或是表结构的性能瓶颈,就得EXPLAIN 的查询结果还会告诉你你的索引主键被如何利用的,你的数据表是如何被搜索和排序的,是否有全表扫描等;
- 查询的条件尽量使用索引字段,如某一个表有多个条件,就尽量使用复合索引查询,复合索引使用要注意字段的先后顺序。
- 多表关联尽量用join,减少子查询的使用。表的关联字段如果能用主键就用主键,也就是尽可能的使用索引字段。如果关联字段不是索引字段可以根据情况考虑添加索引。
- 尽量使用limit进行分页批量查询,不要一次全部获取。
- 绝对避免select *的使用,尽量select具体需要的字段,减少不必要字段的查询;
- 尽量将or 转换为 union all。
- 尽量避免使用is null或is not null。
- 要注意like的使用,前模糊和全模糊不会走索引。
- Where后的查询字段尽量减少使用函数,因为函数会造成索引失效。
- 避免使用不等于(!=),因为它不会使用索引。
- 用exists代替in,not exists代替not in,效率会更好;
- 避免使用HAVING子句, HAVING 只会在检索出所有记录之后才对结果集进行过滤,这个处理需要排序,总计等操作。如果能通过WHERE子句限制记录的数目,那就能减少这方面的开销。
- 千万不要 ORDER BY RAND()
接下来会继续总结一些面试中的问题共享给大家,如果觉得内容不错请关注我,我会不定期的推送一些干货给大家。