X86硬件配置
|
硬件名称 |
规格参数 |
备注 |
|
设备型号 |
Dell PowerEdge R730 |
3台 |
|
CPU |
2 * 8核Intel Xeon E5-2630v3@2.40GHz |
|
|
内存 |
8 * 16GB DDR4@2133MHz |
|
|
磁盘1 |
6 * 600GB HDD |
操作系统安装到其中1块硬盘,其余硬盘做数据存储 |
|
网卡1 |
1 * 4口千兆以太网卡 |
管理网络使用1个 |
|
网卡2 |
1 * 2口万兆以太网卡 |
数据内部通信网络 |
网络环境
|
服务器架构 |
主机名 |
角色 |
BMC IP |
OS IP |
数据通信IP |
备注 |
|
X86 |
hadoop1 |
NN、SNN、DN、RM、NM、JH、ZK、… |
192.168.13.25 |
192.168.13.45 |
10.5.1.1 |
CM Server &Agent |
|
|
hadoop2 |
DN、NM、ZK |
192.168.13.26 |
192.168.13.46 |
10.5.1.2 |
CM Agent |
|
|
hadoop3 |
DN、NM、ZK |
192.168.13.27 |
192.168.13.47 |
10.5.1.3 |
CM Agent |
主机网络配置
通过操作系统自带的nmtui网络配置工具配置主机IP、主机名。此处以hadoop1为例,其他节点参照网络规划进行配置。
# nmtui
进入配置界面,选择编辑连接
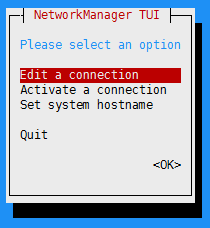
在以太网列表中选择操作系统管理网络接口进行配置:

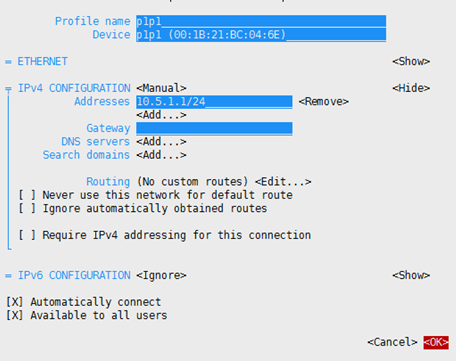
选择数据通信网络接口配置Hadoop内部通信网络:
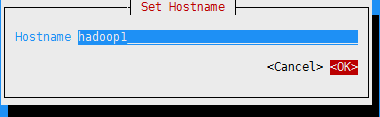
选择配置系统主机名,修改主机名:

关闭防火墙与SELinux
开启防火墙和SELinux功能影响后续服务的部署,所有节点关闭这些服务。
1、设置开机时禁用防火墙
# systemctl disable firewalld
2、禁用SELinux
# sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
3、执行完以上操作后重启系统。
配置hosts
配置主机别名与数据内部通信IP进行映射,以下操作在hadoop1上进行:
# vi /etc/hosts

在hadoop1上将/etc/hosts拷贝到其他节点:
# scp /etc/hosts root@hadoop2:/etc/hosts
# scp /etc/hosts root@hadoop3:/etc/hosts
配置SSH免密登录
集群间通信需要所有节点配置SSH免密登录,这里需要创建密钥并拷贝公钥到其他节点。
在所有节点上进行操作:
1、创建密钥
# ssh-keygen
(根据提示一路回车)
2、拷贝公钥到其他节点
# ssh-copy-id hadoop1
# ssh-copy-id hadoop2
# ssh-copy-id hadoop3
安装并行分布式shell工具
pdsh是一个并行分布式shell,能够对多节点并行命令操作,它由epel软件仓库提供。这里在hadoop1上安装即可,需要访问互联网:
# yum -y install epel-release
# yum -y install pdsh-rcmd-ssh
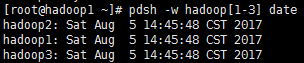
查看多个节点的系统日期检测功能是否正常,-w为指定操作的主机IP或主机别名,支持缩写,如hadoop[1-3]表示“hadoop1,hadoop2,hadoop3”
# pdsh -w hadoop[1-3] date

配置yum本地源
一些基础的软件包可以使用操作系统镜像iso文件中提供的而不需要访问互联网。
在hadoop1上执行以下操作:
1、在所有节点上创建存放iso镜像文件的目录
# pdsh -w hadoop[1-3] "mkdir /root/tools"
2、将iso镜像文件从hadoop1传到其他节点(事先已将该镜像文件上传到hadoop1)
# pdsh -w hadoop[2-3] "scp root@hadoop1:~/tools/CentOS-7-x86_64-DVD-1611.iso /root/tools/"
3、挂载iso镜像并将目录下所有文件拷贝到yum本地源目录
# pdsh -w hadoop[1-3] "mkdir /media/CentOS"
# pdsh -w hadoop[1-3] "mount -o loop /root/tools/CentOS-7-x86_64-DVD-1611.iso /mnt/"
# pdsh -w hadoop[1-3] "cp -av /mnt/* /media/CentOS/"
4、创建本地源文件
# vi /etc/yum.repos.d/CentOS-Media.repo
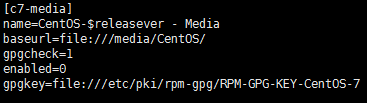
# pdsh -w hadoop[2-3] "scp root@hadoop1:/etc/yum.repos.d/CentOS-Media.repo /etc/yum.repos.d/CentOS-Media.repo"
5、建立yum本地源cache
# pdsh -w hadoop[1-3] "yum --disablerepo=* --enablerepo=c7-media clean all"
# pdsh -w hadoop[1-3] "yum --disablerepo=* --enablerepo=c7-media makecache"
配置NTP时间同步
集群内节点间通信需要确保所有节点的系统时间不会相差太大,否则将影响服务正常运行。
这里在hadoop1上执行操作:
1、安装ntp软件包
# pdsh -w hadoop[1-3] "yum --disablerepo=* --enablerepo=c7-media -y install ntp"
2、配置NTP Server,选择hadoop1作为集群中NTP本地时间同步服务端:
# cp /etc/ntp.conf /etc/ntp.conf_orig
# vi /etc/ntp.conf
restrict 192.168.13.0 mask 255.255.255.0 nomodify notrap
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server cn.ntp.org.cn iburst
server 127.127.1.0
fudge 127.127.1.0 stratum 2
3、配置NTP Client,除hadoop1以外其他节点均作为客户端向hadoop1请求时间同步
# cp /etc/ntp.conf_orig /etc/ntp.conf_client
# vi /etc/ntp.conf_client
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server 192.168.13.45 iburst
将Client端配置文件上传到其他节点
# pdsh -w hadoop[2-3] "scp root@hadoop1:/etc/ntp.conf_client /etc/ntp.conf"
4、重启NTP服务,等待一段时间后查看是否同步成功
# pdsh -w hadoop[1-3] "systemctl restart ntpd"
# pdsh -w hadoop[1-3] "ntpstat | grep sync"
如果长时间未同步,可尝试重启所有client节点NTP服务:
# pdsh -w hadoop[2-3] 'systemctl restart ntpd'

# pdsh -w hadoop[1-3] date
5、将系统时间写入硬件时钟
# pdsh -w hadoop[1-3] "hwclock -w"
6、设置NTP服务开机自启动
# pdsh -w hadoop[1-3] "systemctl enable ntpd"