场景
很多查询要通过某些字段(一个或多个字段)排序后获取前N行,或者跳过M行,取N行,这种情况下,采用B树索引的自身排序特性,可以快速定位并获取数据。
实战
oracle
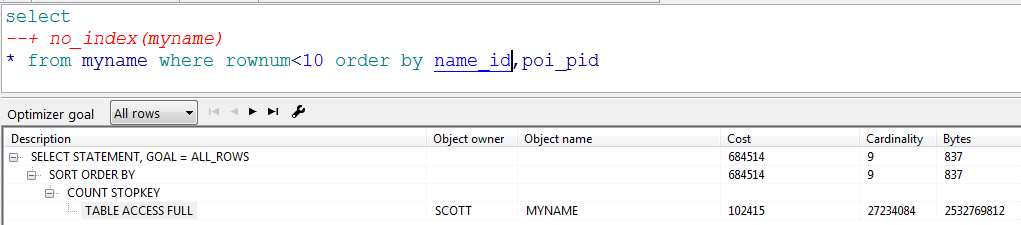
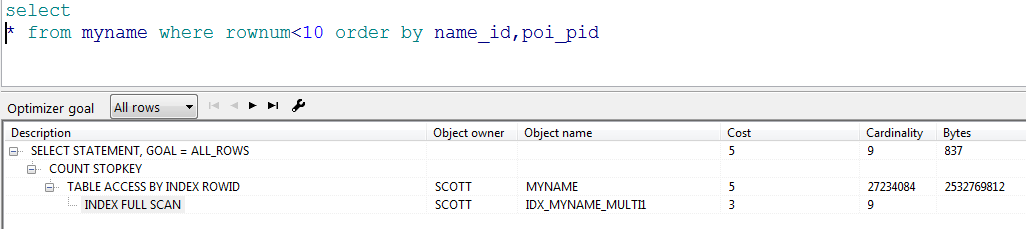
myname表存储有两千多万的数据,现需要按照其中两个字段name_id和poi_pid都降序排列后,取出前10行,如果没有索引,会进行全表扫描,性能较差,执行计划如下:
现在name_id和poi_pid上创建复合索引:
create index idx_myname_multi1 on myname(name_id,poi_pid);
执行计划采用索引全扫描,执行时间和性能都有很大提升:
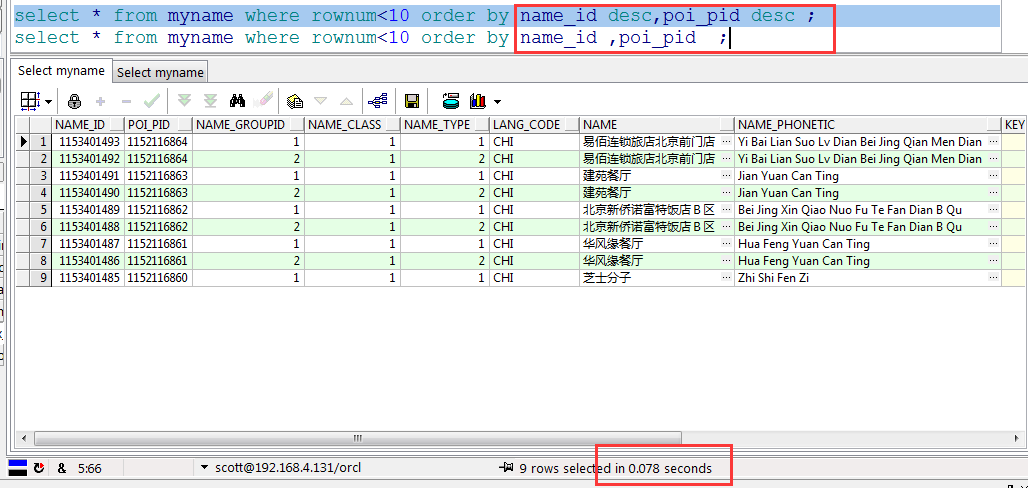
对于索引字段的排序,要不都升序,要不都降序。
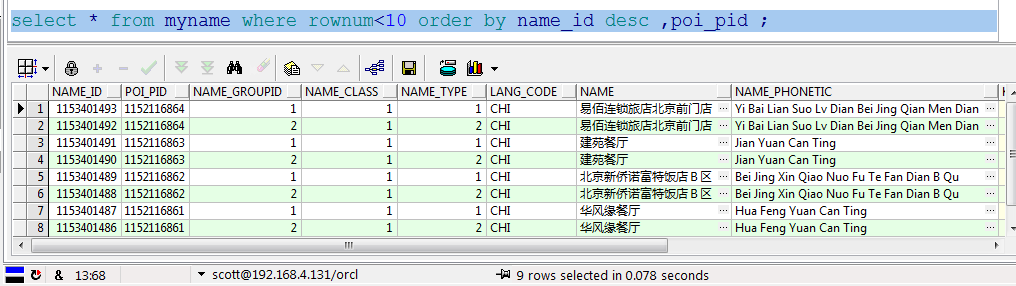
对于某些字段需要升序、某些字段需要降序,则需要再额外创建对应所需要的排序索引,比方说需要按照name_id的降序排列、poi_pid的升序排列:
create index idx_myname_multi2 on myname(name_id desc,poi_pid);
执行查询:

同样也应用于name_id升序、poi_pid降序:
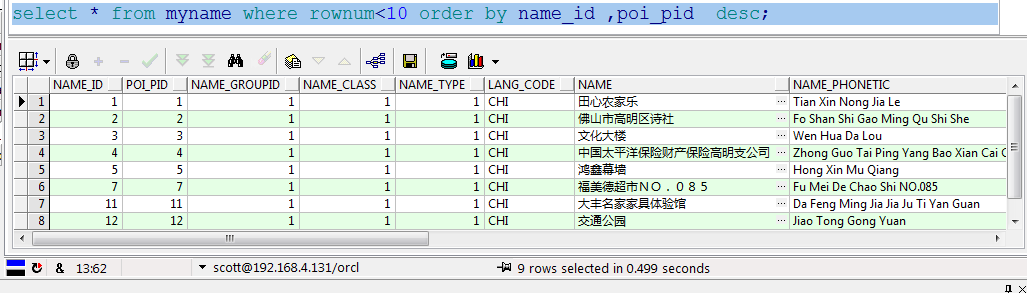
postgresql
原理类似于oracle,只不过在语法上有些不同。
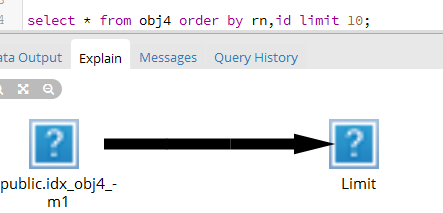
表obj4有400多万数据,在列rn和id上分别创建了两个复合索引:
CREATE INDEX idx_obj4_m1 ON public.obj4 USING btree (rn, id);
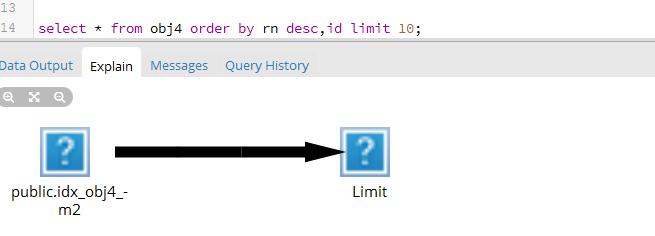
CREATE INDEX idx_obj4_m2 ON public.obj4 USING btree (rn DESC, id);
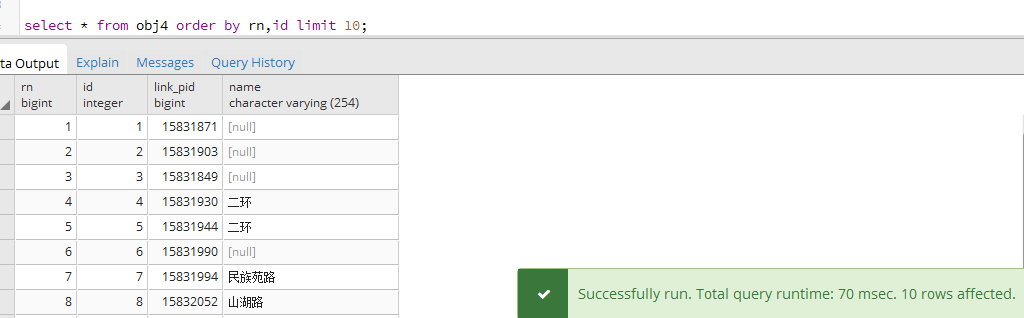
执行查询: