近期,我所在的团队将一项微服务迁移到中央平台。这套中央平台捆绑有CI/CD,基于Kubernetes 的运行时以及其他功能。这项演习也将作为先头试点,用于指导未来几个月内另外150 多项微服务的进一步迁移。而这一切,都是为了给西班牙的多个主要在线平台(包括Infojobs、Fotocasa 等)提供支持。
在将应用程序部署到 Kubernetes 并路由一部分生产流量过去后,情况开始发生变化。Kubernetes 部署中的请求延迟要比 EC2 上的高出 10 倍。如果不找到解决办法,不光是后续微服务迁移无法正常进行,整个项目都有遭到废弃的风险。
为什么 Kubernetes 中的延迟要远高于 EC2?
为了查明瓶颈,我们收集了整个请求路径中的指标。这套架构非常简单,首先是一个 API 网关(Zuul),负责将请求代理至运行在 EC2 或者 Kubernetes 中的微服务实例。在 Kubernetes 中,我们仅代表和 NGINX Ingress 控制器,后端则为运行有基于 Spring 的 JVM 应用程序的 Deployment 对象。
|
EC2
|
|
|
+---------------+
|
|
|
| +---------+ |
|
|
|
| | | |
|
|
|
+-------> BACKEND | |
|
|
|
| | | | |
|
|
|
| | +---------+ |
|
|
|
| +---------------+
|
|
|
+------+ |
|
|
|
Public | | |
|
|
|
-------> ZUUL +--+
|
|
|
traffic | | | Kubernetes
|
|
|
+------+ | +-----------------------------+
|
|
|
| | +-------+ +---------+ |
|
|
|
| | | | xx | | |
|
|
|
+-------> NGINX +------> BACKEND | |
|
|
|
| | | xx | | |
|
|
|
| +-------+ +---------+ |
|
|
|
+-----------------------------+
|
问题似乎来自后端的上游延迟(我在图中以「xx」进行标记)。将应用程序部署至 EC2 中之后,系统大约需要 20 毫秒就能做出响应。但在 Kubernetes 中,整个过程却需要 100 到 200 毫秒。
我们很快排除了随运行时间变化而可能出现的可疑对象。JVM 版本完全相同,而且由于应用程序已经运行在 EC2 容器当中,所以问题也不会源自容器化机制。另外,负载强度也是无辜的,因为即使每秒只发出 1 项请求,延迟同样居高不下。另外,GC 暂停时长几乎可以忽略不计。
我们的一位 Kubernetes 管理员询问这款应用程序是否具有外部依赖项,因为 DNS 解析之前就曾引起过类似的问题,这也是我们目前找到的可能性最高的假设。
可能原因
假设一:DNS 解析
在每一次请求时,我们的应用程序都像域中的某个 AWS ElasticSearch 实例(例如 elastic.spain.adevinta.com)发出 1 到 3 条查询。我们在容器中添加了一个 shell,用于验证该域名的 DNS 解析时间是否过长。
来自容器的 DNS 查询结果:
|
[root@be-851c76f696-alf8z /]# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
|
|
|
;; Query time: 22 msec
|
|
|
;; Query time: 22 msec
|
|
|
;; Query time: 29 msec
|
|
|
;; Query time: 21 msec
|
|
|
;; Query time: 28 msec
|
|
|
;; Query time: 43 msec
|
|
|
;; Query time: 39 msec
|
来自运行这款应用程序的 EC2 实例的相同查询结果:
|
bash-4.4# while true; do dig "elastic.spain.adevinta.com" | grep time; sleep 2; done
|
|
|
;; Query time: 77 msec
|
|
|
;; Query time: 0 msec
|
|
|
;; Query time: 0 msec
|
|
|
;; Query time: 0 msec
|
|
|
;; Query time: 0 msec
|
前者的平均解析时间约为 30 毫秒,很明显,我们的应用程序在其 ElasticSearch 上造成了额外的 DNS 解析延迟。
但这种情况非常奇怪,原因有二:
- Kubernetes 当中已经包含大量与 AWS 资源进行通信的应用程序,而且都没有出现延迟过高的情况。因此,我们必须弄清引发当前问题的具体原因。
- 我们知道 JVM 采用了内存内的 DNS 缓存。从配置中可以看到,TTL 在 $JAVA_HOME/jre/lib/security/java.security 位置进行配置,并被设置为 networkaddress.cache.ttl = 10。JVM 应该能够以 10 秒为周期缓存所有 DNS 查询。
为了确认 DNS 假设,我们决定剥离 DNS 解析步骤,并查看问题是否可以消失。我们的第一项尝试是让应用程序直接与 ELasticSearch IP 通信,从而绕过域名机制。这需要变更代码并进行新的部署,即需要在 /etc.hosts 中添加一行代码以将域名映射至其实际 IP:
|
34.55.5.111 elastic.spain.adevinta.com
|
通过这种方式,容器能够以近即时方式进行 IP 解析。我们发现延迟确实有所改进,但距离目标等待时间仍然相去甚远。尽管 DNS 解析时长有问题,但真正的原因还没有被找到。
网络管道
我们决定在容器中进行 tcpdump,以便准确观察网络的运行状况。
|
[root@be-851c76f696-alf8z /]# tcpdump -leni any -w capture.pcap
|
我们随后发送了多项请求并下载了捕捉结果(kubectl cp my-service:/capture.pcap capture.pcap),而后利用 Wireshark 进行检查。
DNS 查询部分一切正常(少部分值得讨论的细节,我将在后文提到)。但是,我们的服务处理各项请求的方式有些奇怪。以下是捕捉结果的截图,显示出在响应开始之前的请求接收情况。
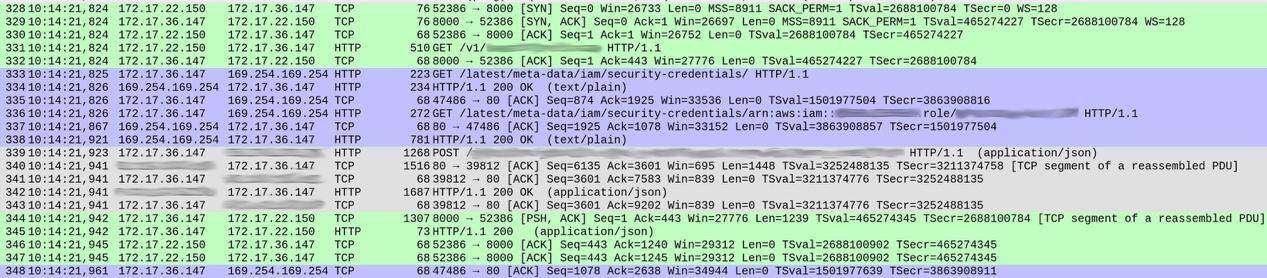
数据包编号显示在第一列当中。为了清楚起见,我对不同的 TCP 流填充了不同的颜色。
从数据包 328 开始的绿色部分显示,客户端(172.17.22.150)打开了容器(172.17.36.147)间的 TCP 连接。在最初的握手(328 至 330)之后,数据包 331 将 HTTP GET /v1/…(传入请求)引向我们的服务,整个过程耗时约 1 毫秒。
来自数据包 339 的灰色部分表明,我们的服务向 ElasticSearch 实例发送了 HTTP 请求(这里没有显示 TCP 握手,是因为其使用原有 TCP 连接),整个过程耗费了 18 毫秒。
到这里,一切看起来还算正常,而且时间也基本符合整体响应延迟预期(在客户端一侧测量为 20 到 30 毫秒)。
但在两次交换之间,蓝色部分占用了 86 毫秒。这到底是怎么回事?在数据包 333,我们的服务向 /latest/meta-data/iam/security-credentials 发送了一项 HTTP GET 请求,而后在同一 TCP 连接上,又向 /latest/meta-data/iam/security-credentials/arn:…发送了另一项 GET 请求。
我们进行了验证,发现整个流程中的每项单一请求都发生了这种情况。在容器内,DNS 解析确实有点慢(理由同样非常有趣,有机会的话我会另起一文详加讨论)。但是,导致高延迟的真正原因,在于针对每项单独请求的 AWS Instance Metadata Service 查询。
假设二:指向 AWS 的流氓调用
两个端点都是 AWS Instance Metadata API 的组成部分。我们的微服务会在从 ElasticSearch 中读取信息时使用该服务。这两条调用属于授权工作的基本流程,端点通过第一项请求产生与实例相关的 IAM 角色。
|
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/
|
|
|
arn:aws:iam::<account_id>:role/some_role
|
第二条请求则向第二个端点查询实例的临时凭证:
|
/ # curl http://169.254.169.254/latest/meta-data/iam/security-credentials/arn:aws:iam::<account_id>:role/some_role`
|
|
|
{
|
|
|
"Code" : "Success",
|
|
|
"LastUpdated" : "2012-04-26T16:39:16Z",
|
|
|
"Type" : "AWS-HMAC",
|
|
|
"AccessKeyId" : "ASIAIOSFODNN7EXAMPLE",
|
|
|
"SecretAccessKey" : "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY",
|
|
|
"Token" : "token",
|
|
|
"Expiration" : "2017-05-17T15:09:54Z"
|
|
|
}
|
客户可以在短时间内使用这些凭证,且端点会定期(在 Expiration 过期之前)检索新凭证。这套模型非常简单:出于安全原因,AWS 经常轮换临时密钥,但客户端可以将密钥缓存几分钟,从而抵消检索新凭证所带来的性能损失。
照理来说,整个过程应该由 AWS Java SDK 为我们处理。但不知道为什么,实际情况并非如此。搜索了一遍 GitHub 问题,我们从#1921 当中找到了需要的线索。
AWS SDK 会在满足以下两项条件之一时刷新凭证:
- Expiration 已经达到 EXPIRATION_THRESHOLD 之内,硬编码为 15 分钟。
- 最后一次刷新凭证的尝试大于 REFRESH_THRESHOLD,硬编码为 60 分钟。
我们希望查看所获取凭证的实际到期时间,因此我们针对容器 API 运行了 cURL 命令——分别指向 EC2 实例与容器。但容器给出的响应要短得多:正好 15 分钟。现在的问题很明显了:我们的服务将为第一项请求获取临时凭证。由于有效时间仅为 15 分钟,因此在下一条请求中,AWS SDK 会首先进行凭证刷新,每一项请求中都会发生同样的情况。
为什么凭证的过期时间这么短?
AWS Instance Metadata Service 在设计上主要代 EC2 实例使用,而不太适合 Kubernetes。但是,其为应用程序保留相同接口的机制确实很方便,所以我们转而使用 KIAM,一款能够运行在各个 Kubernetes 节点上的工具,允许用户(即负责将应用程序部署至集群内的工程师)将 IAM 角色关联至 Pod 容器,或者说将后者视为 EC2 实例的同等对象。其工作原理是拦截指向 AWS Instance Metadata Service 的调用,并利用自己的缓存(预提取自 AWS)及时接上。从应用程序的角度来看,整个流程与 EC2 运行环境没有区别。
KIAM 恰好为 Pod 提供了周期更短的临时凭证,因此可以合理做出假设,Pod 的平均存在周期应该短于 EC2 实例——默认值为 15 分钟。如果将两种默认值放在一起,就会引发问题。提供给应用程序的每一份证书都会在 15 分钟之后到期,但 AWS Java SDK 会对一切剩余时间不足 15 分钟的凭证做出强制性刷新。
结果就是,每项请求都将被迫进行凭证刷新,这使每项请求的延迟提升。接下来,我们又在 AWS Java SDK 中发现了一项功能请求,其中也提到了相同的问题。
相比之下,修复工作非常简单。我们对 KIAM 重新配置以延长凭证的有效期。在应用了此项变更之后,我们就能够在不涉及 AWS Instance Metadata Service 的情况下开始处理请求,同时返回比 EC2 更低的延迟水平。
总结
根据我们的实际迁移经验,最常见的问题并非源自 Kubernetes 或者该平台其他组件,与我们正在迁移的微服务本身也基本无关。事实上,大多数问题源自我们急于把某些组件粗暴地整合在一起。
我们之前从来没有复杂系统的整合经验,所以这一次我们的处理方式比较粗糙,未能充分考虑到更多活动部件、更大的故障面以及更高熵值带来的实际影响。
在这种情况下,导致延迟升高的并不是 Kubernetes、KIAM、AWS Java SDK 或者微服务层面的错误决策。相反,问题源自 KIAM 与 AWS Java SDK 当中两项看似完全正常的默认值。单独来看,这两个默认值都很合理:AWS Java SDK 希望更频繁地刷新凭证,而 KIAM 设定了较低的默认过期时间。但在二者结合之后,却产生了病态的结果。是的,各个组件能够正常独立运行,并不代表它们就能顺利协作并构成更庞大的系统。
原文链接: