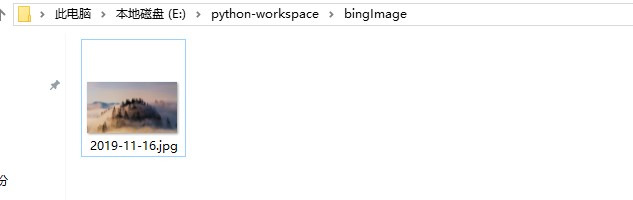
这两天在接触爬虫,记录一下学习
使用了两个包
下载器使用的是第三方的requests,
Requests 使用的是 urllib3,继承了urllib2的所有特性。Requests支持HTTP连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
有关requests使用有个比较详细的文档:requests快速上手。
解析使用的正则表达式 re。
1 import re 2 import requests 3 import datetime 4 5 url = 'https://www.bing.com/' 6 html = requests.get(url).text #获取这个网页源码 7 Nurl = re.findall('id="bgLink" rel="preload" href="(.*?)&',html,re.S) #正则表达式写好 8 for temp in Nurl: #循环获取里边的图片,其实这里只有一个 9 url = 'https://www.bing.com' + temp 10 print(url) 11 pic = requests.get(url) #接着把图片保存下来,再提前准备一个bingImage目录用来存放 12 file = 'bingImage\' + str(datetime.datetime.now().year)+'-'+str(datetime.datetime.now().month)+'-'+str(datetime.datetime.now().day) + '.jpg' 13 #print(file) 14 fp = open(file,'wb') 15 fp.write(pic.content) 16 fp.close()
运行后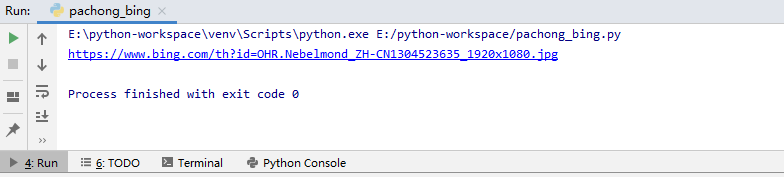
成功到手今日份的美图