学习爬虫, 首先要懂的是网页. 支撑起各种光鲜亮丽的网页的不是别的, 全都是一些代码. 这种代码我们称之为 HTML, HTML 是一种浏览器(Chrome, Safari, IE, Firefox等)看得懂的语言, 浏览器能将这种语言转换成我们用肉眼看到的网页. 所以 HTML 里面必定存在着很多规律, 我们的爬虫就能按照这样的规律来爬取你需要的信息.
其实除了 HTML, 一同构建多彩/多功能网页的组件还有 CSS 和 JavaScript.

网页基本组成部分
在真正进入爬虫之前, 我们先来做一下热身运动, 弄明白网页的基础, HTML 有哪些组成部分, 是怎么样运作的. 如果你已经非常熟悉网页的构造了, 欢迎直接跳过这一节!
<! html lang="cn">
<head>
<meta charset="UTF-8">
<title>scraping tutorrial python</title>
<link rel ="icon" href="https://www.cnblogs.com/******/*****/**** .png">
</head>
<body>
<h1>爬虫测试</h1>
<p>
这是一个在<a href="https://www.cnblogs.com">python</a>
<a href="https://www.cnblogs.com/tutorrial/scraping">爬虫</a>简单测试
</p>
</body>
我制作了一个非常简易的网页, 给大家呈现以下最骨感的 HTML 结构. 如果你点开它, 呈现在你眼前的, 就是下面这张图的上半部分. 而下半部分就是我们网页背后的 HTML code.
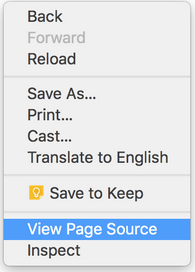
如何看到 HTML 的 source code 的? 其实很简单, 在你的浏览器中 (我用的是 Google Chrome), 显示网页的地方, 点击鼠标右键, 大多数浏览器都会有类似这样一个选项 “View Page Source”. 点击它就能看到页面的源码了.
在 HTML 中, 基本上所有的实体内容, 都会有个 tag 来框住它. 而这个被 tag 住的内容, 就可以被展示成不同的形式, 或有不同的功能. 主体的 tag 分成两部分, header 和 body. 在 header 中, 存放这一些网页的网页的元信息, 比如说 title, 这些信息是不会被显示到你看到的网页中的. 这些信息大多数时候是给浏览器看, 或者是给搜索引擎的爬虫看.