今天完成了上篇博客报告中的最后一道题:
编写独立应用程序,读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后,统计出文件的行数;通过 sbt 工具将整个应用程序编译打包成 JAR 包, 并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
首先创建一个文件夹/root/spark/sparkapp作为应用程序根目录:
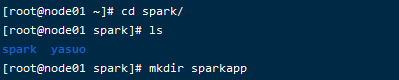
然后创建文件夹结构:

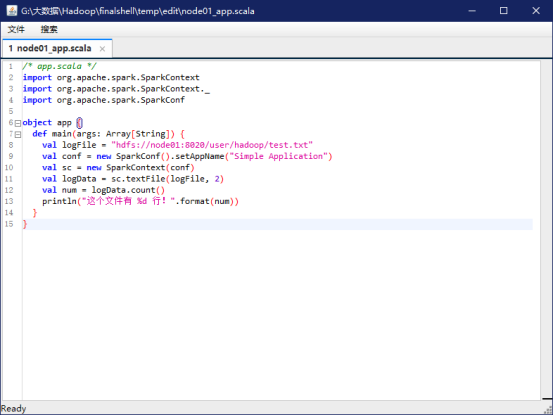
在该目录下新建一个app.scala文件:

添加如下代码:
接下来在sparkapp中新建app.sbt:
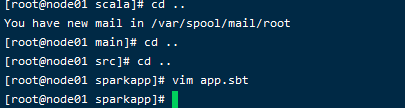
添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系:
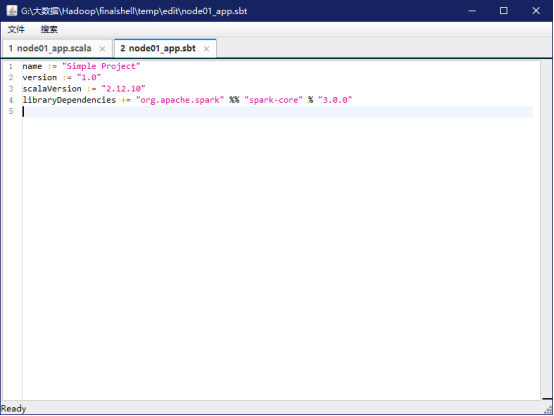
注意:文件 app.sbt 需要指明 Spark 和 Scala 的版本,如下图所示:
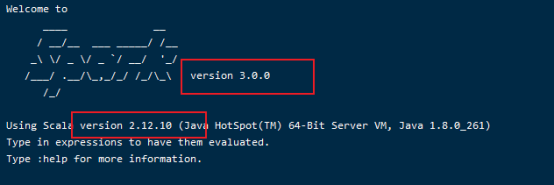
然后使用 sbt 打包 Scala 程序,为了保证 sbt文件能正常运行,先执行如下命令检查整个应用程序的文件结构:
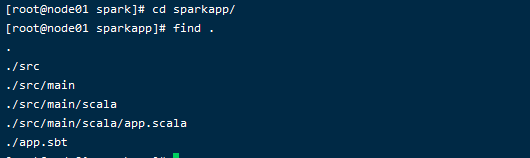
然后我们就可以通过如下代码将整个应用程序打包成 JAR:
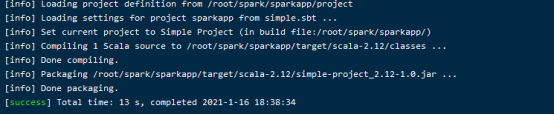
输出:
