1.给出结对成员的学号及姓名
- 李嘉群 061500513
- 刘双玉 031502424
2.首页给出项目的Github链接
https://github.com/424baopu/software/tree/master/Match
3.贴出你们生成的一组最“好”的数据(这里的数据特指 input_data.txt,数据给出对应链接即可),并详细说明"数据生成"程序的原理以及你们所考虑的因素。
- 数据输入链接:
https://github.com/424baopu/software/blob/master/Match/Project/myinput_data.txt - 数据生成程序的原理:
-
预处理:生成时间和标签的字符串数组
-
时间:一周七天,一天6段
8:00~10:0010:00~12:0014:00~16:0016:00~18:0018:00~20:0020:00~22:00共分为42个时间片 -
标签:多组标签,选取可能有联系标签放入同一组,保证每组内标签不会互斥,比如,积极与消极在一组。
-
学生:(意愿,时间,标签无重复)
- 1)学号:按6个班级,每班50人,从031502101到031502650
- 2)空闲时间:10~14 按照每天12个空闲时段从42个时间片中选取1014个
- 3)部门意愿:从部门编号里随机取0到5个数据
- 4)兴趣标签:从已有的且在同一组的标签里随意选取2-5个标签
-
部门:(时间,标签无重复)
- 1)部门纳新人数:随机生成10-15人
- 2)活动时间:从已有时间段内2-3个
- 3)部门标签:从已有的且在同一组的标签里随意选择2-3个
- 4)部门编号:从D001到D020
-
考虑的因素:部门的活动时间尽量合理,考虑不会在短时间内有多次活动,选取时间有1~2天的间隔,在同一组里选择标签,标签有点不太合理。
-
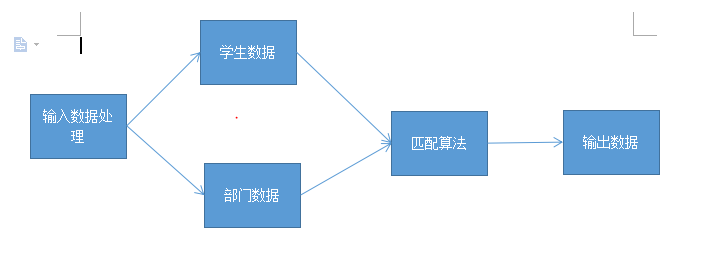
4.详细说明你们数据建模及匹配程序的思路及实现方式
(1)整体模块介绍
-
1)程序主要分为输入数据的处理(
Input.java),匹配算法(Match.java),学生模块(Student.java),部门模块(Department.java),输出模块(Output.java) -
2)流程图
(2)数据建模
把学生和部门抽象成类
-
学生模型:
- 1)学号(String no)
- 2)兴趣标签(String[] tags)
- 3)所选的部门(String[] departments)
- 4)空闲时间(String[] freeTime)
- 5)处理后的空闲时间(int[][] dateTime)(将字符串转换为数字)
- 6)被录取的次数(int numAdmit) -
部门模型:
- 1) 部门编号(String no)
- 2)限制人数(int memberLimit)
- 3)部门标签(String[] tags)
- 4)部门活动时间(String[] eventSchedules)
- 5)处理后的活动时间(int[][] dateTime)
- 6)剩余名额(int numRemaining) -
输入处理模型:
- 1)dealInput()函数:处理json格式的数据
- 2)dealDepartments()函数:将处理好的部门数据放入创建好的部门数组中
- 3)dealStudents()函数:将处理好的学生数据放入创建好的学生数组中 -
输出处理模型:
- 1)getAdmitted()函数:获取被录取的学生学号和相应的部门号
- 2)getUnluckyDepartment()函数:获取没有学生选取的部门号
- 3)getUnluckStudent()函数:获取没有被部门录取的学生学号 -
匹配模型:
- 1)
matchProcess()函数:对部门和学生按一定的条件进行匹配 -
isFreeTimeConflict()函数:判断部门时间和学生空余时间是否冲突,用于根据时间进行匹配
- 3)
filter()函数:根据学生与当前部门标签匹配程度,学生已经被部门录取数目来对学生进行筛选,筛选公式:0.3 * (匹配标签个数/学生总标签个数) + 1 / (被录取次数 + 1)
- 1)
(3)匹配算法的实现
-
考虑因素(重要性从高到低)
- 1)考虑学生第一志愿,第一志愿是学生最想进的部门。
- 2)学生空余时间和部门活动时间冲突问题。
- 3)考虑到部门录取的限制人数。
- 4)学生已经被录取次数:录取次数少的同学优先。
- 5)学生与部门兴趣标签匹配度:兴趣标签匹配度高的同学优先
-
算法思想
-
1)先按时间匹配
- 先对学生的空闲时间和部门活动时间进行合并(在输入处理的过程中导入给定的json数据,并对能合并的时间段进行合并),得到一个时间区间。 - 根据让学生的空闲时间和部门的活动时间进行5轮匹配(学生的空闲时间区间应包含部门活动时间区间),用一个`Map<String,ArrayList<String>>`来存储一个部门被录取的学生列表。在这期间,第一轮是拿每个学生的空余时间与他们所选的第一志愿进行匹配(这样就考虑到了第一志愿优先的原则),第二轮是拿每个学生的空余时间与他们所选的第二志愿进行匹配,第三、四、五轮同样如此(可能有学生只选了少于五个部门,因此在判断过程中要进行判断一下)。 - 若匹配,则把该学生的学号加进该部门号对应的列表中;若学生和部门有一个时间不匹配,则筛掉。 -
2)后按标签匹配(对时间不冲突的学生与部门,再次筛选)
- 先对部门剩余名额`numRemaining`进行判断,如果剩余名额大于0,则继续进行录取,如果无剩余名额,则不再录取。 - 对于有剩余名额的部门,对兴趣标签进行匹配,在此过程中要根据学生已经被部门录取的次数,以及其他因素的考虑,最终录取的标准为:标签匹配度=0.3 * (匹配标签个数/学生总标签个数) + 1 / (被录取次数 + 1)。除以总标签个数是消除学生填报过多标签带来的优势,乘以0.3是因为,录取次数少带来的优势数值最大为1,标签匹配度也可能为1,乘以0.3再次削弱影响。- 然后对学生的标签匹配度进行排序,标签匹配度大的优先录取。部门录取一个学生的同时,应对部门的剩余名额
numRemaining和学生的空闲时间freeTime以及学生被录取的次数numAdmit进行更新。
- 然后对学生的标签匹配度进行排序,标签匹配度大的优先录取。部门录取一个学生的同时,应对部门的剩余名额
-
3)流程图

5.你们在代码遵循了一定的规范,在博客中描述结对团队遵循的代码规范,并截取部分关键代码佐证说明
代码规范:
- 1)命名:类名基本用的是第一个字母大写,方法名,变量名和函数名采用驼峰命名法,对于命名,基本的要求是见名知意。
- 2)缩进:eclipse切换到下一行时自动产生。
- 3)分行:每个语句占用一行,比较清晰。
- 4)注释:简单的程序没注释,复杂的程序注释放在相应语句的上方。相应变量的注释放到右边。
-
- {}的使用:见代码,采用了第一个"{"紧跟for或者if后面的方式。
代码示例:
- 函数示例:
private void matchProcess(int index) {
//将报名情况填入Map
for(int j = 0; j < Input.stu.length; j++) {
//如果此轮志愿不为空
if(Input.stu[j].getDeptments().length > index) {
//取得学号与部门编号,如果二者时间不冲突,则加入map
String dept = Input.stu[j].getDeptments()[index];
String no = Input.stu[j].getNo();
if(isFreeTimeConflict(index,dept) == false){
map.get(dept).add(no);
}
}
}
//对时间不冲突的学生与部门,第二次筛选
for(int i = 0; i < Input.depa.length; i++) {
String dno = Input.depa[i].getNo();
ArrayList<String> tmp = map.get(dno);//报名学生学号List
int num = Input.depa[i].getNumRemaining();//部门剩余名额
//如果部门还可以录取
if(num > 0) {
/*
* 如果部门剩余名额小于报名人数,根据优先级排序,只取出前num个学生,全部录取
* 参数为:部门下标,学生学号List,部门剩余名额
*/
tmp = filter(i,tmp,num);
result.get(dno).addAll(tmp);
//对部门剩余名额,学生录取个数,学生空闲时间进行更新
int newNum = num - tmp.size();
Input.depa[i].setNumRemaining(newNum);
updateStuStatus(i, tmp);
}
}
}
- 类示例:
public class Student {
String no;
String[] tags;
String[] deptments;
String[] freeTime;
int[][] dateTime;//将空闲时间字符串转为数字
int numAdmit;
static Map<String, Integer>week;
static Map<String, Integer>hours;
Student(int dept_sz,int tag_sz,int free_sz) {
tags = new String[tag_sz];
deptments = new String[dept_sz];
freeTime = new String[free_sz];
dateTime = new int[free_sz][2];
numAdmit = 0;
}
6.结果评估。对于程序的匹配结果,你们是否满意?请对你们程序处理结果进行分析
理想结果:
时间冲突的学生与部门一定不匹配,对于学生:不如意值(学生不冲突志愿个数 - 被录取次数)应该尽可能平均。对于部门:录取人数在不冲突志愿与部门录取上限取较小一个。
对测试数据的思考:如果数据太小,部门不冲突志愿申请总数小于部门人数限制,测试无意义,如果数据太大,一轮志愿部门就招满人了,测试也没有意义。
测试结果:为了计算方便,去除时间冲突,将部门例会时间设为无,每个志愿均有效,然后控制前150个学生标签匹配度为1,后150个学生标签匹配度为0.最后得出不如意值方差为1.6764888888888967,相对满意。
7.已经尝试过结对编码,你一定很多话要说。请发表结对感受,以及两个人对彼此结对中的闪光点或建议的分享
(1)eclipse的安装和使用
- 由于是采用java编程,需要java编程的软件,于是装eclipse,jdk配置好了,从官网上下载了一个eclipse,怎么装也装不上去,卸载了 好几次,又重装了好几次,最后还是舍友发给我的一个eclipse网址,终于装上了。使用eclipse的感觉就是,真的很智能,生成类后,可以自动类的成员函数。调用一个函数时,也可以自动生成该函数的框架,用起来还不错,而且不容易乱。(ps:可能是电脑问题)
(2)java的学习
- 原来没怎么用过java编程,对java的了解也没那么多。队友说用java处理json数据比用C或者C++简单,于是就用了java语言。自己感觉java挺好用,有很多集成的东西,例如一些字符串的处理都有专门的函数,包括json数据的处理也有专门的对象和函数,处理起来比较方便和简单。学C++时感觉最难的是指针,java里没有指针,不那么容易乱,语法和C++也都差不多,容易入门。就是在观看博客时,感觉java程序中的变量名贼长,可能也是一个特点吧。。。
(3)代码规范
- 原来写代码也没怎么在意代码规范的问题,软工可能是大学第一门让我注重代码规范的课。队友找我商量代码命名的问题,一开始并没有感觉那么重要,后来看了一下队友写的代码,感觉不太好懂,一些命名并不是那么直观,后来对于函数和变量的命名商讨了一下,力图做到见名知意。基于缩进还有{}的问题也做了一些谈论,具体实现情况详见代码。
(4)总结
- 自己的代码功力不够,如果是自己去完成这项任务,可能还挺艰难的。相比较下,队友强很多,有许多要向队友学习的。感觉队友对于细节的把握很到位,考虑的比较全面。最重要的是,我在一旁观看队友敲代码时,觉得她脑中的框架特别清晰,而且具体的数据存储啊,函数的使用之类的,都有具体的规划,还有一点是感觉队友对于代码的纠错能力很强,遇到错误可以及时的找到问题,修改代码。自己平时敲代码时,整体构思还是有所欠缺,没什么规划。总之,有很多要学习的。