- 线程生命周期的开销:线程比较少的情况使用new Thread(task)无多大影响,但是如果涉及到线程比较多的情况,应用的性能就会受到影响,如果jdbc创建连接一样,new Thead创建线程也会耗资源、耗时间的。
- 资源的消耗量:活动线程会消耗系统性能,如果运行的线程数量多余可用的处理器数,那么就会有大量空闲的线程占用内存,会给垃圾收集器带来压力,如果有cpu资源竞争,还会有其他性能开销。
- 限定创建线程的数目:如果不设定创建线程的数量,一个任务一个线程无限创建线程,高负载情况下就有可能造成OutOfMemoryError错误。所以像tomcat这种servlet容器的线程池都设置了最大线程数量的。
Executor框架组成
Eexecutor接口:包含Eexecutor、ExecutorService、ScheduledExecutorService
ThreadPool线程池:包含ThreadPoolExecutor、ScheduledThreadPoolExecutor
Fork/Join框架:JDK1.7新增
类之间的关系如下: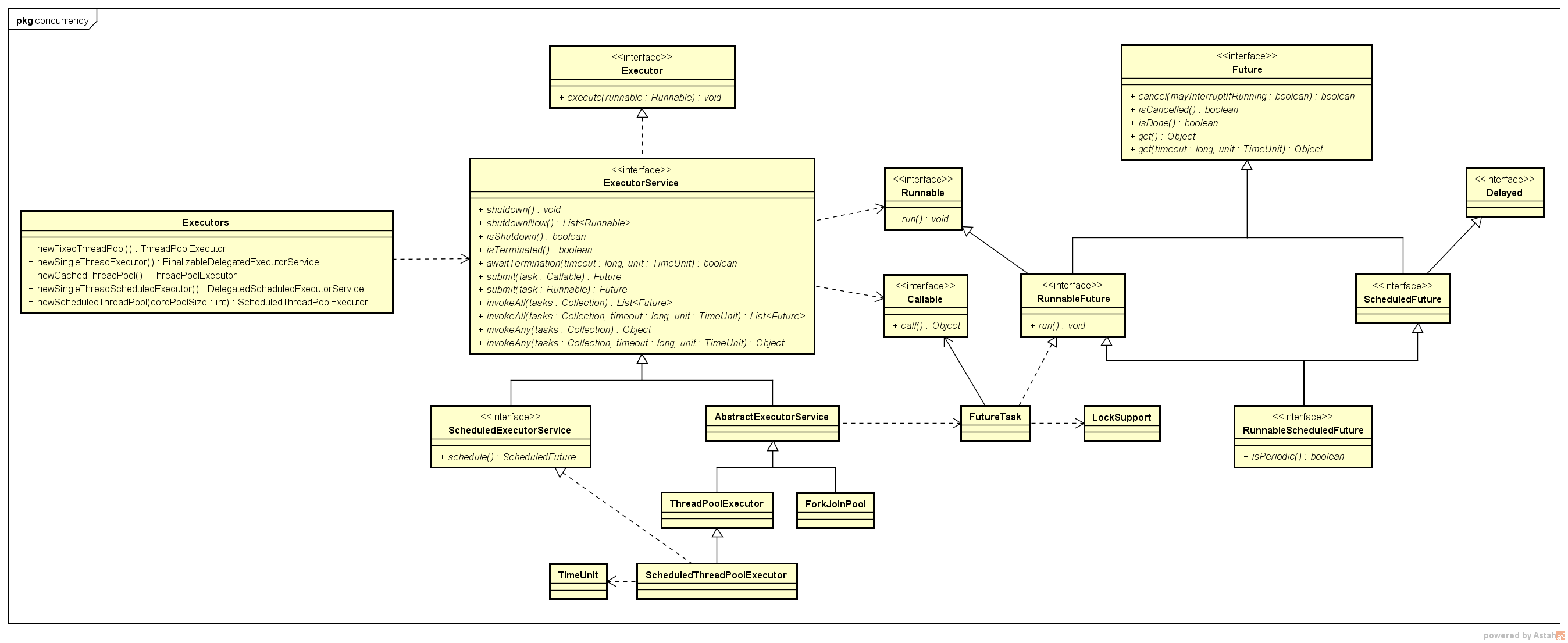
Executor框架将线程的创建与执行解耦,可以异步调用,让任务相互独立,用阻塞队列管理任务,直接在当前线程中消费队列,可以减少线程之间进行资源竞争,也可以减少线程的创建和系统的开销,要廉价多了。这种设计就是经典并发模式Active Object Models(也称Actor Models)的实现,如下图: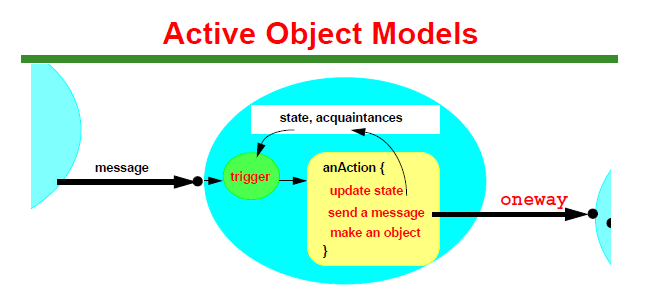
可以参考execute方法,就按照上面的模式来的。另外Executors工厂类创建了不同的连接池,为任务的执行分配了不同执行策略。
线程池
concurrent包里面主要包含ThreadPoolExecutor、ScheduledThreadPoolExecutor两种线程池,Executors类提供了很多创建线程池的方法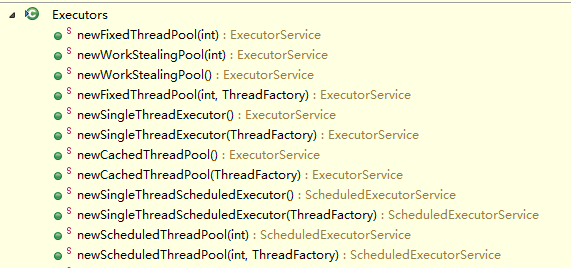
,newFixedThreadPool创建定长的线程池、newWorkStealingPool创建ForkJoinPool(jdk1.8新增)、newCachedThreadPool创建缓存线程池(可以回收空闲的线程)、newSingleThreadExecutor创建当个线程池(保证FIFOLIFO优先级),newScheduledThreadPool创建定时器线程池,如果有特殊处理的,也可以根据自己的需求来创建连接池,如tomcat也是基于ThreadPoolExecutor实现了自己的连接池。
ThreadPoolExecutor
public (int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
从ThreadPoolExecutor最简单的构造函数可以看出,线程池总是依赖阻塞队列而工作的,newFixedThreadPool与newSingleThreadExecutor使用的是LinkedBlockingQueue无界队列,newCachedThreadPool使用SynchronousQueue,ThreadPoolExecutor还定义了一个Worker执行任务线程,除此之外,还有个非常重要的变量ctl(线程池控制状态)由执行器状态和工作线程的数量组成,在控制执行的时候都是围绕这个变量来判断。
处理任务
参考前面的Active Object Models图,可以将线程池执行任务主要分为3个步骤:
1、如果任务少于线程池大小时,就作为firstTask分别创建工作线程执行任务
2、如果第n个任务超出了线程池大小,就加入到阻塞队列,并从新检测执行器状态状态以及工作线程数量(有可能线程发生RuntimeException挂掉,最后可工作线程数量变为0),如果工作线程挂完了就重新启动一个线程(解决线程泄露问题)。阻塞队列的任务执行就在第一步所创建的线程执行,参考代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//判断当前任务或者检测阻塞队列
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
大专栏 concurrent包分析之Executor框架 Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
3、如果任务入队列失败了,就重新开启一个线程去执行,如果还是失败了,就可以确定是执行器关闭了或者线程池已经达到饱和状态了。
线程池原理
从上面的执行步骤来就可以看出线程池依赖于阻塞队列,然后基于生产者消费者模式实现的,execute()方法一直添加任务(生产者),当任务数量超出线程池的最大长度就添加到阻塞队列等待排队执行,而第一次创建的所有工作线程(最大数量为线程池的最大长度)就会一直判断线程池里面是否有任务执行,如果有就执行任务(消费者)。这样做就可以重用线程了,不用每次去创建线程,性能肯定比一个任务一个线程好多了。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor由ScheduledFutureTask、DelayedWorkQueue组成,实现任务执行还是用的父类ThreadPoolExecutor的工作线程。jdk1.5之前使用定时任务都用的Timer,但是与ScheduledThreadPoolExecutor有着明显区别:
- Timer使用的System.currentTimeMillis()毫秒来控制时间,ScheduledThreadPoolExecutor使用System.nanoTime()纳秒控制更加精准,并且可以使用TimeUnit进行时间的跨单元转换。
- Timer只有单个工作线程,ScheduledThreadPoolExecutor可以配置多个工作线程。
- 如果工资线程发生异常,Timer会造成线程泄露没有重启的线程,ScheduledThreadPoolExecutor会一直检测工作线程的数量,如果没有工作线程了,会一直添加数量小于线程池的工作线程(使用父类ThreadPoolExecutor的addaddWorker方法)
从以上比较可以看出,ScheduledThreadPoolExecutor就是取代Timer的。
还是从一个简单的例子看ScheduledThreadPoolExecutor是如何工作的。addWork参考领导/跟随者模式
@Test
public void testScheduleAtFixedRate() throws Exception {
ScheduledThreadPoolExecutor p = new ScheduledThreadPoolExecutor(1);
CountDownLatch latch = new CountDownLatch(3);
p.scheduleAtFixedRate(new Task(latch), 0, 1000, TimeUnit.MILLISECONDS);
latch.await();
}
线程池都是基于生产者消费者模式的,所以ScheduledThreadPoolExecutor也不例外,执行任务的时候会一直像队列里面添加任务:
private void delayedExecute(RunnableScheduledFuture<?> task) {
if (isShutdown())
reject(task);
else {
//添加到队列,让工作线程去消费
super.getQueue().add(task);
if (isShutdown() &&
!canRunInCurrentRunState(task.isPeriodic()) &&
remove(task))
task.cancel(false);
else
//启动线程
ensurePrestart();
}
}
ScheduledThreadPoolExecutor第一次执行用的父类ThreadPoolExecutor的addWorker方法添加工作线程并启动它,然后每个工作线程会检查队列里面是否有消费的线程,参考ThreadPoolExecutor的runWorker方法,与ThreadPoolExecutor有点不同的是,ScheduledThreadPoolExecutor使用的是延时阻塞队列DelayedWorkQueue。每次消费就进行take操作:
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
if (first == null)
available.await();
else {
long delay = first.getDelay(NANOSECONDS);
if (delay <= 0)
//返回队列中的执行任务之前,要先执行finally模块中的唤醒操作
return finishPoll(first);
first = null; // don't retain ref while waiting
if (leader != null)
available.await();
else {
//领导线程初始化为null,当前线程为线程池中的线程
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
//当前线程等待延迟时间到期
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
available.signal();
lock.unlock();
}
}
参考资料: