(一)分析函数语法
function_name(<argument>,<argument>...) over(<partition by clause><order by clause> <windowing_clause>);
function_name:函数名称,如count(),sum(),avg(),max(),min()等
argument : 参数
over() : 开窗函数
partition_clause:分区(分组)子句
order by clause:排序字句,数据记录排序,累计计算
windowing clause:开窗子句,定义分析函数在操作行的集合。分析函数有三种:rows、range、specifying。
(二)分析函数使用汇总
(2.1)count() over():统计分区各组中的行数,partition by可选,order by可选。
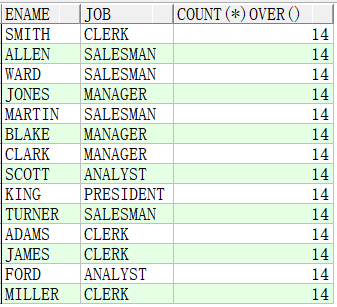
例子1:统计总人数
SQL> SELECT ename,job,COUNT(*) OVER() FROM emp; --总计数
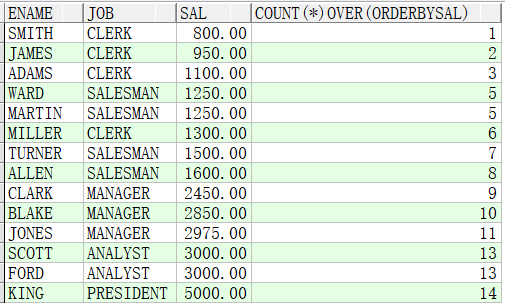
例子2:按照sal排序,统计总人数
SELECT ename,job,sal,COUNT(*) OVER(ORDER BY sal) FROM emp; --按照薪资递加计数
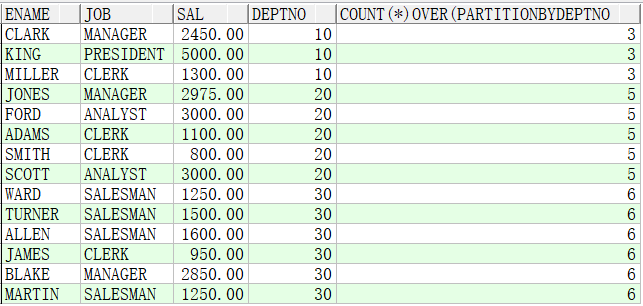
例子3:统计各个部门的总人数
SELECT ename,job,sal,deptno,COUNT(*) OVER(PARTITION BY deptno) FROM emp; --分组计数,统计各个部门的人数
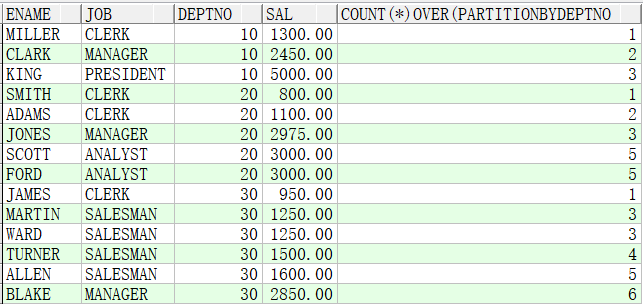
例子4:对部门分组,对各个部门按照薪资排序并计数
SELECT ename,job,deptno,sal,COUNT(*) OVER(PARTITION BY deptno ORDER BY sal) FROM emp; --按照各个部门的薪资水平排序
(2.2)sum() over():记录分区中的总和,partition by可选,order by可选
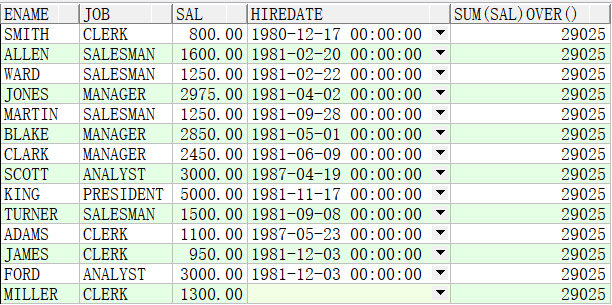
例子1:求出所有部门的薪资总和
SELECT ename,job,sal,hiredate,SUM(sal) OVER() FROM emp;
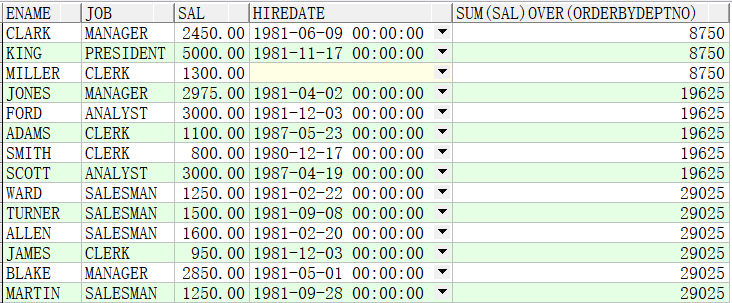
例子2:求出各个部门薪资的累计值,按部门累计
SELECT ename,job,sal,hiredate,SUM(sal) OVER(ORDER BY deptno) FROM emp;
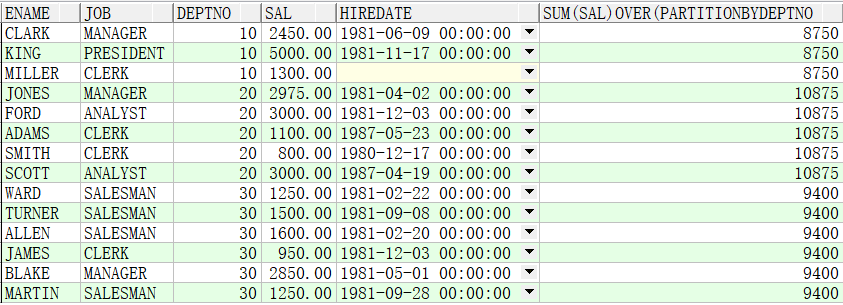
例子3:求出各自部门薪资的总和
SELECT ename,job,deptno,sal,hiredate,SUM(sal) OVER(PARTITION BY deptno) FROM emp
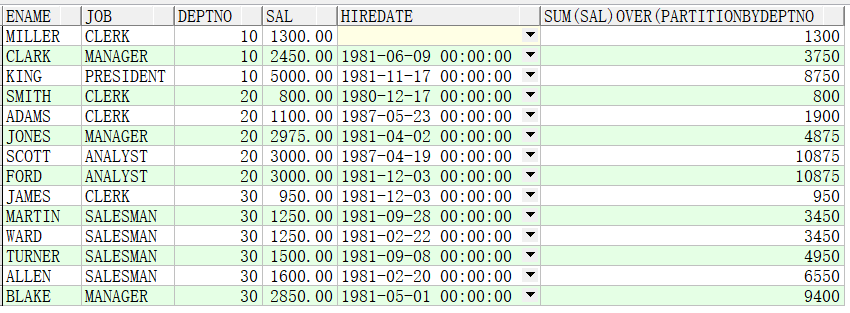
例子4:求出各部门薪资累计值
SELECT ename,job,deptno,sal,hiredate,SUM(sal) OVER(PARTITION BY deptno ORDER BY sal) FROM emp;
(2.3)avg() over():记录分区中的平均值,partition by可选,order by可选
例子1:求出所有人的平均薪资
SELECT ename,sal,hiredate,AVG(sal) OVER() FROM emp;

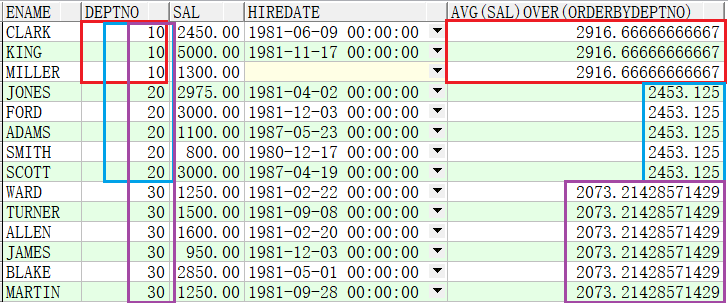
例子2:求出部门的累计薪资。
SELECT ename,deptno,sal,hiredate,AVG(sal) OVER(ORDER BY deptno) FROM emp;
图中红色代表10号部门人员的平均薪资,
蓝色代表10号部门与20号部门人员的平均薪资,
紫色代表10号部门与20号部门与30号部门人员的平均薪资。
例子3.求出各个部门的平均薪资
SELECT ename,deptno,sal,hiredate,AVG(sal) OVER(PARTITION BY deptno) FROM emp;
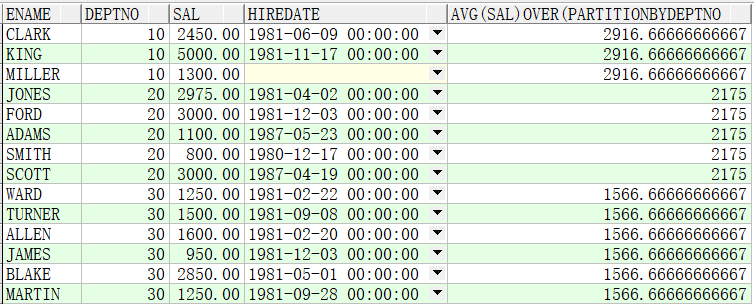
例子4:求出各个部门的平均累计薪资
SELECT ename,deptno,sal,hiredate,AVG(sal) OVER(PARTITION BY deptno ORDER BY sal) FROM emp;

(2.4)min() avg():统计分组中的最小值,partition by可选,order by可选
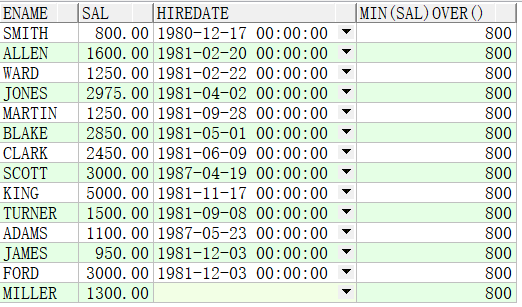
例子1:求所有人中薪资最小值
SELECT ename,sal,hiredate,MIN(sal) OVER() FROM emp;
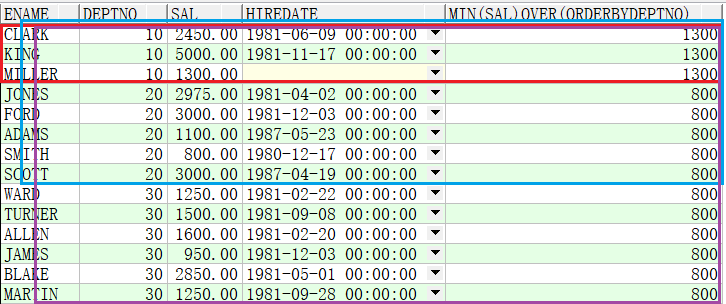
例子2:求出按部门累计的最小薪资
SELECT ename,deptno,sal,hiredate,MIN(sal) OVER(ORDER BY deptno) FROM emp;
图中红圈是10号部门的最低薪资,蓝圈是10号部门与20号部门的最低薪资,紫圈是10号部门、20号部门、30号部门的最低薪资。
例子3:求出各个部门的最低薪资
SELECT ename,deptno,sal,hiredate,MIN(sal) OVER(PARTITION BY deptno) FROM emp;
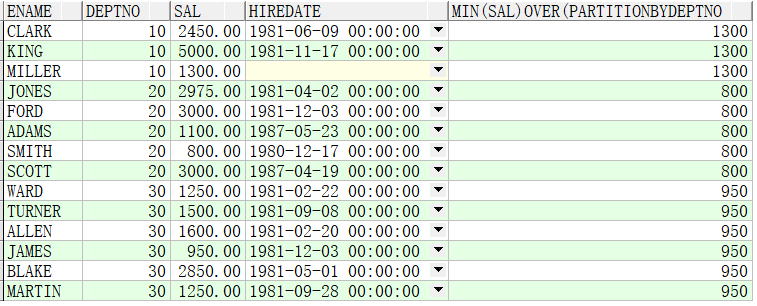
例子4:按照部门求出各自部门的最小薪资,并按照部门分组后再按照薪资排序
SELECT ename,deptno,sal,hiredate,MIN(sal) OVER(PARTITION BY deptno ORDER BY sal) FROM emp;

(2.5)max() avg():统计分组中的最大值,partition by可选,order by可选。用法与上面的min() over()相似。
(2.6)row_number() over():排序,排序序号无重复值,partition by可选,order by必选
例子1:按照薪资水平从高到低输出所有人的信息
SELECT ename,deptno,sal,hiredate,row_number() OVER(ORDER BY sal DESC) FROM emp;
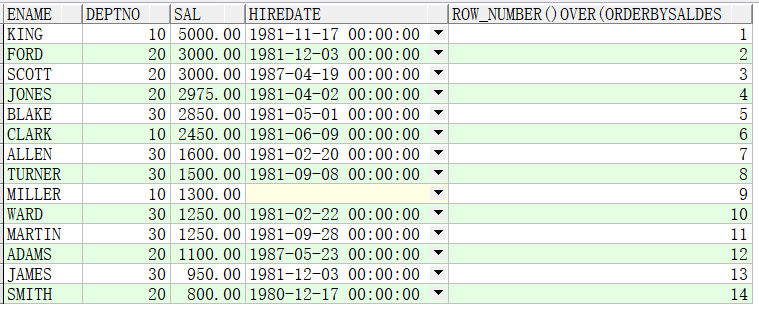
例子2:先按部门分组,再按照薪资水平从高到低输出所有人的信息
SELECT ename,deptno,sal,hiredate,row_number() OVER(PARTITION BY deptno ORDER BY sal DESC) FROM emp;

例子2.1:求出各个部门前2名薪资最高的人员信息
SELECT * FROM (SELECT ENAME, DEPTNO, SAL, HIREDATE, ROW_NUMBER() OVER(PARTITION BY DEPTNO ORDER BY SAL DESC) RN FROM EMP) WHERE RN < 3;

(2.7)rank() over():跳跃排序,排序序号会有重复,partition by可选,order by必选
例子1:先按照部门降序,再按照薪资降序排序
SELECT ename,deptno,sal,hiredate,RANK() OVER(ORDER BY deptno DESC,sal DESC) FROM emp;
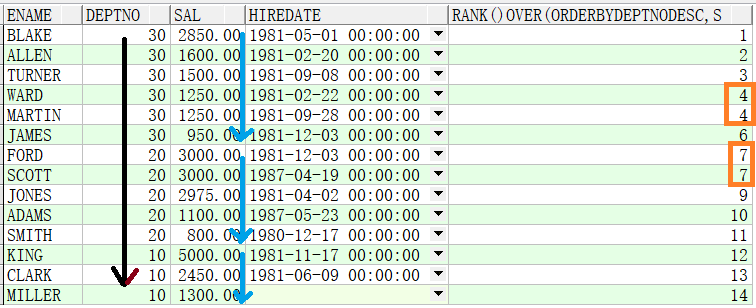
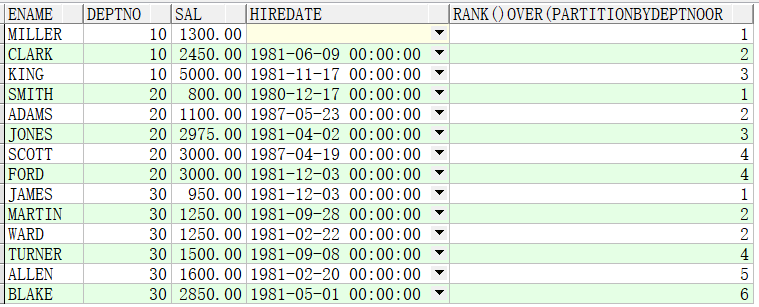
例子2:先按照部门分区(分组),再按照薪资升序排序
SELECT ename,deptno,sal,hiredate,RANK() OVER(PARTITION BY deptno ORDER BY sal) FROM emp;
(2.8)dense_rank() over():连续排序,排序序号会有重复,partition by可选,order by必选
例子1:先按部门排序,再只能找工资排序
SELECT ename,deptno,sal,hiredate,dense_rank() OVER(ORDER BY deptno DESC,sal DESC) FROM emp;
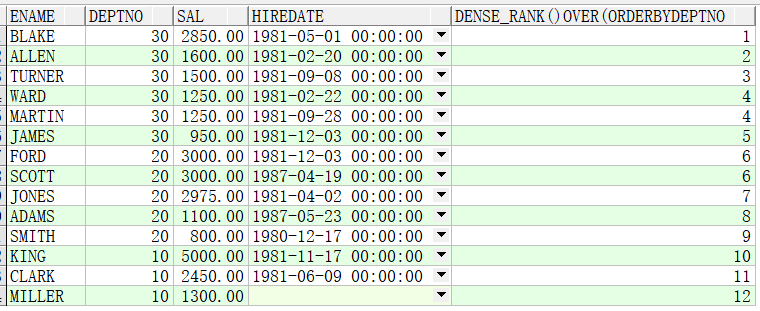
例子2:先按照部门分组,再按照薪资排序
SELECT ename,deptno,sal,hiredate,dense_rank() OVER(PARTITION BY deptno ORDER BY sal) FROM emp;
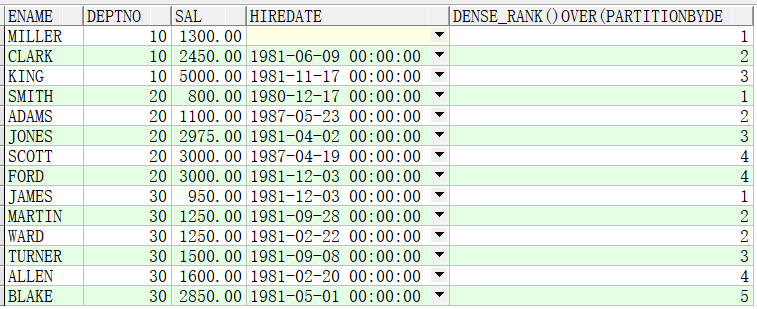
(2.9)ntile(n) over():将记录平均分成n份,多出的按照次序分给前面的组。partition by可选,order by必选。
例子1:将emp表信息按照薪资从低到高分成4份
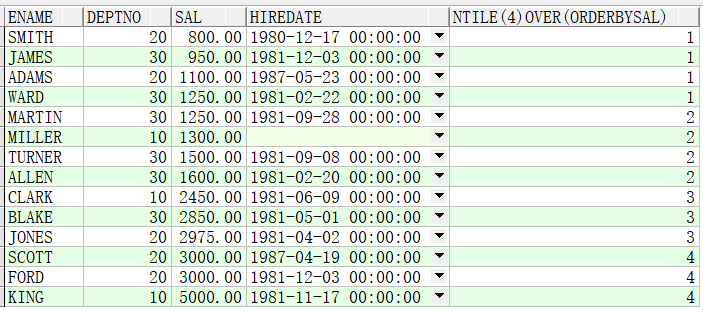
例子2:先按照部门分组,再将每个部门的数据按照薪资从低到高分成4份。
SELECT ename,deptno,sal,hiredate,NTILE(4) OVER(PARTITION BY deptno ORDER BY sal) FROM emp;
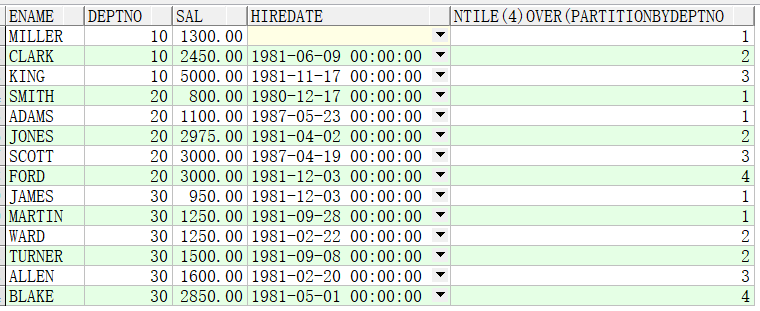
(2.10)first_value() over():取出分区中第一条记录字段的值。partition by可选 ,order by可选。
last_value() over() :取出分区中最后一条记录字段的值。partition by可选,order by可选。
(2.11)lag() over():取出前n行数据,加到当前行作为一个新的列。partition by可选,order by必选。
语法为:lag(field,num,defaultValue) field为要查找的字段,num代表往前查找num行的数据,defaultValue代表没有符合条件的默认值。通过该函数可以去除前n行的数据放入到当前行的新列中。
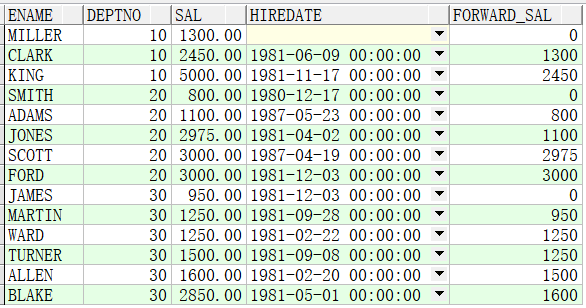
例子1:将前一个用户的薪资作为新的列forward_sal加入到当前用户信息中。
SELECT ename,deptno,sal,hiredate,LAG(sal,1,0) OVER(ORDER BY sal) forward_sal FROM emp;

例子2:按照部门分组,再将前一个用户的薪资作为新的列forward_sal加入到当前用户信息中
SELECT ename,deptno,sal,hiredate,LAG(sal,1,0) OVER(PARTITION BY deptno ORDER BY sal) forward_sal FROM emp;
(2.12)lead() over():取出后n行数据,加到当前行作为一个新的列。partition by可选,order by必选。
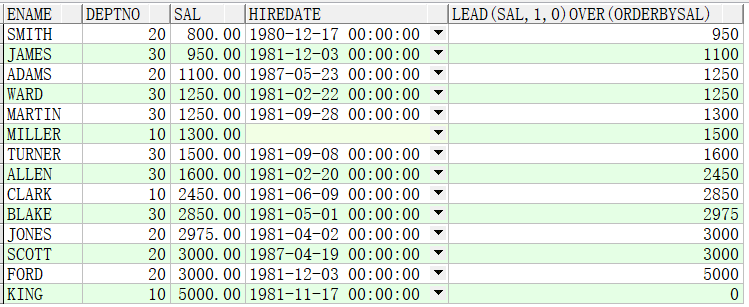
例子1:按照sal从小到大排序,取出后一行的sal数据添加到当前行,作为一个新的列
SELECT ename,deptno,sal,hiredate,LEAD(sal,1,0) OVER(ORDER BY sal) FROM emp;
【完】