很多年前刚毕业那阵写过一篇关于Entity Framework的文章,没发首页却得到100+的推荐。可能是当时Entity Framework刚刚发布介绍EF的文章比较少。一晃这么多年过去了,EF6.1已经发布很久,EF7马上就到来。那篇文章已经显得相当过时,这期间园子里出现了很多介绍EF4/5/6版本的精彩文章,我的工作中也没有在持续使用EF,本来也就不准备再写现在这篇文章了。后来看到之前那篇文章还是有很多朋友在评论里给予鼓励,再加上自己确实在使用新版EF的过程中也总结了一些心得,解决了一些问题。这里打算将这些新的经验分享出来,本文不会像之前那片文章一样从头到尾完整的讲解EF,EF现在覆盖的面太大了,完整的介绍需要一本很厚的书,本文主要是总结一些我感觉EF中特别重要的组件和一些可以被称作最佳实践的使用方式。当然有不对的地方还请各位赐教。(由于对传说中的领域设计不懂,一小部分内容可能不符合“领域设计”的要求,都是自己项目用着顺手的写法)
本文更没有完整的示例,大部分代码都是边修改边测试边粘贴到文章中,下文代码在EF6.1.3中测试过。我的大部分EF使用经验都学习自大名鼎鼎的nopCommerce这个开源项目(后文会提到),有兴趣的TX可以看一下这个项目的代码,一定会有很大收获。当然每家的代码都有自己的风格,能取长补短也是很不错的。
另外感谢园友@liulun提供51cnblogs这个颜值很高的博客园博文编辑器。
下面开始正题(文章很长,慢慢看吧。)
EF的发展历程
还是先来说一下EF从诞生到现在这几年的发展历程吧。在EF最初的版本中,作为一个ORM组件其通过EDM文件(里面是一些xml)来配置数据库与实体类之间的映射,实现数据进出数据库的控制。最初的版本中只支持Database First,即由已有数据库结构生成EDM,继而得到实体类。后来EF在4.0版本起开始支持Model First即先建立EDM,然后生成数据库。
在4.1版本开始,EF迎来了最大的变化--开始支持Code First模式,值得注意的是Code First不是和Database First或Model First平级的概念,而是和EDM平级的概念。使用Code First不再需要EDM来维护实体与数据库之间的映射关系,这个映射完全通过代码来完成,并在程序开始运行时在内存中建立一个映射模型,这也就是Code First这个名称中Code的含义。
使用Code First一般都是先建立实体然后通过代码配置实体到数据库的映射,继而生成数据库(如果数据库已存在,就不需要再生成数据库,可以直接建立代码映射模型),这也就是所谓的Model First模式。当然Code First也支持Database First,通过工具由现有数据库生成实体,及实体映射数据库的代码。
选择
关于EDM的详细信息可以参考前文提到的那片文章,由于Code First的魅力极大,EDM文件又存在不利于版本管理等天生缺陷,基本上处于一个被抛弃的状态。而且看园子中一些文章说在EF7版本可能取消EDM的支持,只保留Code First。我在第一次接触Code Frist后就一直在使用它了,完全不在考虑EDM。
下文中我们将只以Code First为例来介绍EF,而不再涉及EDM。
核心
随着Code First一起出现的DbContext和DbSet类绝对可以称得上EF的功能核心,其取代了之前的ObjectContext和ObjectSet类,提供了与数据库通信,管理内存中实体的重要功能。
DbContext类
主要是负责与数据库进行通信,管理实体到数据库的映射模型,跟踪实体的更改(正如这个类名字Context所示,其维护了一个EF内存中容器,保存所有被加载的实体并跟踪其状态)。关于模型映射和更改跟踪下面都有专门的小节来讨论。Dbcontext中最常用的几个方法如:
-
SaveChanges(和6.0开始增加的异步方法SaveChangesAsync):用于将实体的修改保存到数据库。
-
Set<T>:获取实体相应的DbSet对象,我们对实体的增删改查操作都是通过这个对象来进行的。
还有几个次常用但很重要的属性方法:
-
Database属性:一个数据库对象的表示,通过其SqlQuery、ExecuteSqlCommand等方法可以直接执行一些Sql语句或SqlCommand;EF6起可以通过Database对象控制事务。
-
Entry:获取EF Context中的实体的状态,在更改跟踪一节会讨论其作用。
-
ChangeTracker:返回一个DbChangeTracker对象,通过这个对象的Entries属性,我们可以查询EF Context中所有缓存的实体的状态。
DbSet类
这个类的对象正是通过刚刚提到的Set<T>方法获取的对象。其中的方法都与操作实体有关,如:
-
Find/FindAsync:按主键获取一个实体,首先在EF Context中查找是否有被缓存过的实体,如果查找不到再去数据库查找,如果数据库中存在则缓存到EF Context并返回,否则返回null。
-
Attach:将一个已存在于数据库中的对象添加到EF Context中,实体状态被标记为Unchanged。对于已有相同key的对象存在于EF Context的情况,如果这个已存在对象状态为Unchanged则不进行任何操作,否则将其状态更改为Unchanged。
-
Add:将一个已存在于数据库中的对象添加到EF Context中,实体状态被标记为Added。对于已有相同key的对象存在于EF Context且状态为Added则不进行任何操作。
-
Remove:将一个已存在于EF Context中的对象标记为Deleted,当SaveChanges时,这个对象对应的数据库条目被删除。注意,调用此方法需要对象已经存在于EF Context。
-
Include:详见下面预加载一节。
-
AsNoTracking:相见变更跟踪一节。
-
Local属性:用来跟踪所有EF Context中状态为Added,Modified、Unchanged的实体。作用好像不是太大。没怎么用过。
-
Create:这个方法至今好像没有用到过,不知道干啥的。有了解的评论中给解释下吧。
映射
说一千道一万,EF还是一个ORM工具,映射永远是最核心的部分。所以接下来详细介绍Code First模式下EF的映射配置。
通过Code First来实现映射模型有两种方式Data Annotation和Fluent API。
Data Annotation需要在实体类(我通常的称呼,一般就是一个Plain Object)的属性上以Attribute的方式表示主键、外键等映射信息。这种方式不符合解耦合的要求所以一般不建议使用。
第二种方式就是要重点介绍的Fluent API。Fluent API的配置方式将实体类与映射配置进行解耦合,有利于项目的扩展和维护。
Fluent API方式中的核心对象是DbModelBuilder。
在重写的DbContext的OnModelCreating方法中,我们可以这样配置一个实体的映射:
1
2
3
4
5
6
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Entity<Product>().HasKey(t => t.Id);
base.OnModelCreating(modelBuilder);
}
使用上面这种方式的一个问题是OnModelCreating方法会随着映射配置的增多越来越大。一种更好的方式是继承EntityTypeConfiguration<EntityType>并在这个类中添加映射代码,如:
1
2
3
4
5
6
7
8
9
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
this.ToTable("Product");
this.HasKey(p => p.Id);
this.Property(p => p.Name).IsRequired();
}
}
然后将这个类的实例添加到modelBuilder的Configurations就可以了。
1
modelBuilder.Configurations.Add(new ProductMap());
如果不想手动一个个添加自定的映射配置类对象,还可以使用反射将程序集中所有的EntityTypeConfiguration<>一次性添加到modelBuilder.Configurations集合中,下面的代码展示了这个操作(代码来自nopCommerce项目):
1
2
3
4
5
6
7
8
var typesToRegister = Assembly.GetExecutingAssembly().GetTypes()
.Where(type => !String.IsNullOrEmpty(type.Namespace))
.Where(type => type.BaseType != null && type.BaseType.IsGenericType && type.BaseType.GetGenericTypeDefinition() == typeof(EntityTypeConfiguration<>));
foreach (var type in typesToRegister)
{
dynamic configurationInstance = Activator.CreateInstance(type);
modelBuilder.Configurations.Add(configurationInstance);
}
这样,OnModelCreating就大大简化,并且一劳永逸的是,以后添加新的实体映射只需要添加新的继承自EntityTypeConfiguration<>的XXXMap类而不需要修改OnModelCreating方法。
这种方式给实体和映射提供最佳的解耦合,强烈推荐。
EF CodeFirst的自动发现
例如我们的程序中有一个名为Employee的实体类,我们没有为其定义映射配置(EntityTypeConfiguration<Employee>),但如果我们使用类似下面这样的代码去进行调用,EF会自动为Employee创建默认映射并进行迁移等一系列操作。
1
varemployeeList = context.Set<Employee>().ToList();当然为了能更灵活的配置映射,还是建议手动创建EntityTypeConfiguration<Employee>。
另外2种情况下,EF也会自动创建映射。
类A的对象作为类B的一个导航属性存在,如果类B被包含在EF映射中,则EF也会为类A创建默认映射。
类A继承自类B,如果类A或类B中的一个被包含在EF映射中,则EF也会为另一个创建默认映射(且使用TPH方式进行,详见下文映射高级话题)。
通过上面的介绍可以看到EntityTypeConfiguration类正事Fluent API的核心,下面我们以EntityTypeConfiguration的方法为线,依次了解如何进行Fluent API配置。
基本方法
ToTable:指定映射到的数据库表的名称。
HasKey:配置主键(也用于配置关联主键)
Property:这个方法返回PrimitivePropertyConfiguration的对象,根据属性不同可能是子类StringPropertyConfiguration的对象。通过这个对象可以详细配置属性的信息如IsRequired()或HasMaxLength(400)。
Ignore:指定忽略哪个属性(不映射到数据表)
对于基本映射这几个方法几乎包括了一切,下面是个综合示例:
1
2
3
4
5
6
7
ToTable("Product");
ToTable("Product","newdbo");//指定schema,不使用默认的dbo
HasKey(p => p.Id);//普通主键
HasKey(p => new {p.Id, p.Name});//关联主键
Property(p => p.Id).HasDatabaseGeneratedOption(DatabaseGeneratedOption.None);//不让主键作为Identity自动生成
Property(p => p.Name).IsRequired().HasMaxLength(20).HasColumnName("ProductName").IsUnicode(false);//非空,最大长度20,自定义列名,列类型为varchar而非nvarchar
Ignore(p => p.Description);
使用modelBuilder.HasDefaultSchema("newdbo");可以给所有映射实体指定schema。
PrimitivePropertyConfiguration还有许多可配置的选项,如HasColumnOrder指定列在表中次序,IsOptional指定列是否可空,HasPrecision指定浮点数的精度等等,不再列举。
配置关联
下面一系列示例的主角是产品,为了配合演示还请了产品小伙伴们,它们将在演示过程中逐一登场。
基本上,下面展示的关联的配置都可以从关联类的任意一方的EntityTypeConfiguration<T>开始配置。无论从哪一方起开始配置,不同的写法最终都能实现相同的效果。下面的示例将只展示其中之一配置的方式,等价的另一种配置不再展示。
产品类的基本结构如下,后面演示过程中将根据需要为其添加新的属性。
1
2
3
4
5
6
public class Product
{
public int Id{ get; set; }
public string Name { get; set; }
public string Description { get; set; }
}
1 - 1关联
(虽然看起来最简单,但这个好像是理解起来最麻烦的一种配置)
这种关联从实际关系上来看是两个类共享相同的值作为主键,比如有User表和UserPhoto表,他们都应该使用UserId作为主键,并且通过相同的UserId值进行关联。但这种关系反映在数据库中必须通过外键的概念来实现,这时候就需要一个表的主键既作为主键又作为关联表的外键。EF中各种配置方式无非就是告诉EF CodeFirst让那个表的主键作为另一个表的外键而已,现在不理解的,看一下下面的例子就明白了。(其实,如果用Data Annotation配置反而很简单,[Key],[ForeignKey]标一标就可以了)
这节使用到的是保修卡这个角色,我们知道一个产品对应一个保修卡,产品和保修卡使用相同的产品编号。这正是我们说的1对1的好例子。
1
2
3
4
5
6
public class WarrantyCard
{
public int ProductId { get; set; }
public DateTime ExpiredDate { get; set; }
public virtual Product Product { get; set; }
}
我们给Product也增加保修卡属性:
1
public virtual WarrantyCard WarrantyCard { get; set; }
下面来看看怎么把Product和WarrantyCard关联起来。经过“千百”次的尝试,终于找到了下面这些结果看起来很正确的组合,先列于下方,后面慢慢分析:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
//第一组(两条效果完全相同)
HasRequired(p => p.WarrantyCard).WithRequiredDependent(i => i.Product);
HasRequired(p => p.WarrantyCard).WithOptional(i => i.Product);
//第二组(两条效果完全相同)
HasRequired(p => p.WarrantyCard).WithRequiredPrincipal(i => i.Product);
HasOptional(p => p.WarrantyCard).WithRequired(i => i.Product);
}
}
public class WarrantyCardMap : EntityTypeConfiguration<WarrantyCard>
{
public WarrantyCardMap()
{
ToTable("WarrantyCard");
HasKey(i => i.ProductId);
}
}
除了以上这些组合,其它组合都没法达到效果(都会生成多余的外键)。
第一组Fluent API生成的迁移代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CreateTable(
"dbo.Product",
c => new
{
Id = c.Int(nullable: false),
Name = c.String(),
Description = c.String(maxLength: 200),
})
.PrimaryKey(t => t.Id)
.ForeignKey("dbo.WarrantyCard", t => t.Id)
.Index(t => t.Id);
CreateTable(
"dbo.WarrantyCard",
c => new
{
ProductId = c.Int(nullable: false, identity: true),
ExpiredDate = c.DateTime(nullable: false),
})
.PrimaryKey(t => t.ProductId);
值得注意的是,外键指定在Product表的Id列上,Product的主键Id不作为标识列。
再来看看第二组Fluent API生成的迁移代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CreateTable(
"dbo.Product",
c => new
{
Id = c.Int(nullable: false, identity: true),
Name = c.String(),
Description = c.String(maxLength: 200),
})
.PrimaryKey(t => t.Id);
CreateTable(
"dbo.WarrantyCard",
c => new
{
ProductId = c.Int(nullable: false),
ExpiredDate = c.DateTime(nullable: false),
})
.PrimaryKey(t => t.ProductId)
.ForeignKey("dbo.Product", t => t.ProductId)
.Index(t => t.ProductId);
变化就在于外键添加到WarrantyCard表的主键ProductId上,而且这个键也不做标识列使用了。
对于当前场景这两组配置应该选择那一组呢。对于产品和保修卡,肯定是先有产品后有保修卡,保修卡应该依赖于产品而存在。所以第二组配置把外键设置到WarrantyCard的主键更为合适,让WarrantyCard依赖Product符合当前场景。即Product作为Principal而WarrantyCard作为Dependent,其实这么多代码也无非就是明确两个关联对象Principal和Dependent的地位而已。
使用第二组配置创建表后,我们可以添加数据:
可以一次性添加保修卡和合格证:
1
2
3
4
5
6
7
8
9
10
11
var product = new Product()
{
Name = "空调",
Description = "冰冰凉",
WarrantyCard = new WarrantyCard()
{
ExpiredDate = DateTime.Now.AddYears(3)
}
};
context.Set<Product>().Add(product);
context.SaveChanges();
也可以分开进行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
var product = new Product()
{
Name = "投影仪",
Description = "高分辨率"
};
context.Set<Product>().Add(product);
context.SaveChanges();
WarrantyCard card = new WarrantyCard()
{
ProductId = product.Id,
ExpiredDate = DateTime.Now.AddYears(3)
};
context.Set<WarrantyCard>().Add(card);
context.SaveChanges();
对于查询来说,第一组和第二组配置生成的SQL相同。都是INNER JOIN,这里就不再列出了。
单向1 - *关联(可为空)
这里新登场角色是和发票,发票有自己的编号,有些产品有发票,有些产品没有发票。我们希望通过产品找到发票而又不需要由发票关联到产品。
1
2
3
4
5
6
public class Invoice
{
public int Id { get; set; }
public string InvoiceNo { get; set; }
public DateTime CreateDate { get; set; }
}
产品类新增的属性如下:
1
2
public virtual Invoice Invoice { get; set; }
public int? InvoiceId { get; set; }
可以使用如下代码创建Product到Invoice的关联
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
HasOptional(p => p.Invoice).WithMany().HasForeignKey(p => p.InvoiceId);
}
}
public class InvoiceMap : EntityTypeConfiguration<Invoice>
{
public InvoiceMap()
{
ToTable("Invoice");
HasKey(i => i.Id);
}
}
HasOptional表示一个产品可能会有发票,WithMany的参数为空表示我们不需要由发票关联到产品,HasForeignKey用来指定Product表中的外键列。
还可以通过WillCascadeOnDelete()配置是否级联删除,这个大家都知道,就不多说了。
运行迁移后,数据库生成的Product表外键可为空(注意实体类中表示外键的属性一定要为Nullable类型,不然迁移代码不能生成)。
下面写段代码来测试下这个映射配置,先是创建一个测试对象
1
2
3
4
5
6
7
8
9
10
11
12
var product = new Product()
{
Name = "书",
Description = "码农书籍",
Invoice = new Invoice()//这里不创建Invoice也可以,因为其可以为null
{
InvoiceNo = "12345",
CreateDate = DateTime.Now
}
};
context.Set<Product>().Add(product);
context.SaveChanges();
然后查询,注意,创建和查询要分2次执行,不然不会走数据库,直接由EF Context返回结果了。
1
var productGet = context.Set<Product>().Include(p=>p.Invoice).FirstOrDefault();
通过SS Profiler可以看到生成的SQL如下:
1
2
3
4
5
6
7
8
9
10
SELECT TOP (1)
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
[Extent1].[Description] AS [Description],
[Extent1].[InvoiceId] AS [InvoiceId],
[Extent2].[Id] AS [Id1],
[Extent2].[InvoiceNo] AS [InvoiceNo],
[Extent2].[CreateDate] AS [CreateDate]
FROM [dbo].[Products] AS [Extent1]
LEFT OUTER JOIN [dbo].[Invoices] AS [Extent2] ON [Extent1].[InvoiceId] = [Extent2].[Id]
可以看到对于外键可空的情况,EF生成的SQL使用了LEFT OUTER JOIN,基本上复合我们的期待。
单向1 - *关联(不可为空)
为了演示这个关联,请出一个新对象合格证,合格证有自己的编号,而且一个产品是必须有合格证。
1
2
3
4
5
public class Certification
{
public int Id { get; set; }
public string Inspector { get; set; }
}
我们给Product添加关联合格证的属性:
1
2
public virtual Certification Certification { get; set; }
public int CertificationId { get; set; }
配置Product到Certification映射的代码与之前的类似,就是把HasOptional换成了HasRequired:
1
HasRequired(p => p.Certification).WithMany().HasForeignKey(p=>p.CertificationId);
生成的迁移代码,外键列不能为空。创建对象时Product必须和Certification一起创建。生成的查询语句除了把LEFT OUTER JOIN换成INNER JOIN外其他都一样,不再赘述。
双向1 - *关联
这是比较常见的场景,如一个产品可以对应多张照片,每张照片关联一个产品。先来看看新增的照片类:
1
2
3
4
5
6
7
8
public class ProductPhoto
{
public int Id { get; set; }
public string FileName { get; set; }
public float FileSize { get; set; }
public virtual Product Product { get; set; }
public int ProductId { get; set; }
}
给Product增加ProductPhoto集合:
1
public virtual ICollection<ProductPhoto> Photos { get; set; }
然后是映射配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
HasMany(p => p.Photos).WithRequired(pp => pp.Product).HasForeignKey(pp => pp.ProductId);
}
}
public class ProductPhotoMap : EntityTypeConfiguration<ProductPhoto>
{
public ProductPhotoMap()
{
ToTable("ProductPhoto");
HasKey(pp => pp.Id);
}
}
代码很容易理解,HasMany表示Product中有多个ProductPhoto,WithRequired表示ProductPhoto一定会关联到一个Product。
我们来看另一种等价的写法(在ProductPhoto中配置关联):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
}
}
public class ProductPhotoMap : EntityTypeConfiguration<ProductPhoto>
{
public ProductPhotoMap()
{
ToTable("ProductPhoto");
HasKey(pp => pp.Id);
HasRequired(pp => pp.Product).WithMany(p => p.Photos).HasForeignKey(pp => pp.ProductId);
}
}
有没有感觉和之前单向1 - *的配置很像?其实就是WithMany多了参数而已。随着例子越来越多,大家应该对这几个配置理解的越来越深了。
迁移到数据库后,我们添加些数据测试下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
var product = new Product()
{
Name = "投影仪",
Description = "高分辨率"
};
context.Set<Product>().Add(product);
context.SaveChanges();
ProductPhoto pp1 = new ProductPhoto()
{
FileName = "正面图",
FileSize = 3,
ProductId = product.Id
};
ProductPhoto pp2 = new ProductPhoto()
{
FileName = "侧面图",
FileSize = 5,
ProductId = product.Id
};
context.Set<ProductPhoto>().Add(pp1);
context.Set<ProductPhoto>().Add(pp2);
context.SaveChanges();
试一试一次读取Product及ProductPhoto:
1
var productGet = context.Set<Product>().Include(p=>p.Photos).ToList();
生成的SQL如下:
1
2
3
4
5
6
7
8
9
10
11
12
SELECT
[Limit1].[Id] AS [Id],
[Limit1].[Name] AS [Name],
[Limit1].[Description] AS [Description],
[Extent2].[Id] AS [Id1],
[Extent2].[FileName] AS [FileName],
[Extent2].[FileSize] AS [FileSize],
[Extent2].[ProductId] AS [ProductId],
CASE WHEN ([Extent2].[Id] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1]
FROM (SELECT TOP (1) [c].[Id] AS [Id], [c].[Name] AS [Name], [c].[Description] AS [Description]
FROM [dbo].[Product] AS [c] ) AS [Limit1]
LEFT OUTER JOIN [dbo].[ProductPhoto] AS [Extent2] ON [Limit1].[Id] = [Extent2].[ProductId]
有点小复杂,用LEFT OUTER JOIN的原因是,可能有的Product没有ProductPhoto。
* - *关联
这次轮到产品标签登场了。一个产品可以有多个标签,一个标签也可对应多个产品:
1
2
3
4
5
6
public class Tag
{
public int Id { get; set; }
public string Text { get; set; }
public virtual ICollection<Product> Products { get; set; }
}
给Product增加标签集合:
1
public virtual ICollection<Tag> Tags { get; set; }
映射代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
HasMany(p => p.Tags).WithMany(t => t.Products).Map(m => m.ToTable("Product_Tag_Mapping"));
}
}
public class TagMap : EntityTypeConfiguration<Tag>
{
public TagMap()
{
ToTable("Tag");
HasKey(t => t.Id);
}
}
比较特殊的就是需要指定一个关联表保存多对多的映射关系。
1
2
3
4
5
6
7
8
9
10
11
12
CreateTable(
"dbo.Product_Tag_Mapping",
c => new
{
Product_Id = c.Int(nullable: false),
Tag_Id = c.Int(nullable: false),
})
.PrimaryKey(t => new { t.Product_Id, t.Tag_Id })
.ForeignKey("dbo.Product", t => t.Product_Id, cascadeDelete: true)
.ForeignKey("dbo.Tag", t => t.Tag_Id, cascadeDelete: true)
.Index(t => t.Product_Id)
.Index(t => t.Tag_Id);
一般情况下使用自动生成的外键就好,也可以自己定义外键名称。
1
2
3
4
5
6
HasMany(p => p.Tags).WithMany(t => t.Products).Map(m =>
{
m.ToTable("Product_Tag_Mapping");
m.MapLeftKey("Pid");
m.MapRightKey("Tid");
});
迁移代码变成如下:
1
2
3
4
5
6
7
8
9
10
11
12
CreateTable(
"dbo.Product_Tag_Mapping",
c => new
{
Pid = c.Int(nullable: false),
Tid = c.Int(nullable: false),
})
.PrimaryKey(t => new { t.Pid, t.Tid })
.ForeignKey("dbo.Product", t => t.Pid, cascadeDelete: true)
.ForeignKey("dbo.Tag", t => t.Tid, cascadeDelete: true)
.Index(t => t.Pid)
.Index(t => t.Tid);
把映射代码中的WithMany参数去掉,就是一种单向* - *的映射效果。如我们需要通过Product找到所有Tag,但不需要通过Tag找到有这个标签的Product。有点类似与单向1 - *。
但这里不管WithMany是否有参数,生成的迁移代码都是一样的。
我们也写点数据进去,测试下:
1
2
3
4
5
6
7
8
9
10
11
12
var product = new Product()
{
Name = "投影仪",
Description = "高分辨率",
Tags = new List<Tag>
{
new Tag(){Text = "性价比高"}
}
};
context.Set<Product>().Add(product);
context.SaveChanges();
使用预加载(Include(p=>p.Tags))时的SQL:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
SELECT
[Project1].[Id] AS [Id],
[Project1].[Name] AS [Name],
[Project1].[Description] AS [Description],
[Project1].[C1] AS [C1],
[Project1].[Id1] AS [Id1],
[Project1].[Text] AS [Text]
FROM ( SELECT
[Limit1].[Id] AS [Id],
[Limit1].[Name] AS [Name],
[Limit1].[Description] AS [Description],
[Join1].[Id] AS [Id1],
[Join1].[Text] AS [Text],
CASE WHEN ([Join1].[Product_Id] IS NULL) THEN CAST(NULL AS int) ELSE 1 END AS [C1]
FROM (SELECT TOP (1) [c].[Id] AS [Id], [c].[Name] AS [Name], [c].[Description] AS [Description]
FROM [dbo].[Product] AS [c] ) AS [Limit1]
LEFT OUTER JOIN (SELECT [Extent2].[Product_Id] AS [Product_Id], [Extent3].[Id] AS [Id], [Extent3].[Text] AS [Text]
FROM [dbo].[Product_Tag_Mapping] AS [Extent2]
INNER JOIN [dbo].[Tag] AS [Extent3] ON [Extent3].[Id] = [Extent2].[Tag_Id] ) AS [Join1] ON [Limit1].[Id] = [Join1].[Product_Id]
) AS [Project1]
ORDER BY [Project1].[Id] ASC, [Project1].[C1] ASC
如你所料,因为现在存在3个表,所以使用了2次JOIN。
一点补充
之前的示例中用到多次HasForeignKey()方法来指定外键,如果实体类中不存在表示外键的属性,我们可以用下面的方式指定外键列,这样这个外键列只存在于数据库,不存在于实体中:
1
HasOptional(p => p.Invoice).WithMany().Map(m => m.MapKey("DbOnlyInvoiceId"));
对于关联的映射EF提供了很多方法,可谓让人眼花缭乱,上面只写了我了解的一部分,如有没有覆盖到的场景,欢迎大家在评论中讨论。
dudu老大也曾写了很多关于EF映射的文章,这应该是EF中最令人迷惑的一点,不知道未来某个版本能否简化一下呢?
映射高级话题
创建索引
在EF6.1中,没有原生的方式使用Fluent API创建索引,(Data Annotation配置方式下可以使用IndexAttribute标识一个属性映射包含索引)我们可以借助Annotation让Fluent API也可以用上IndexAttribute来实现映射中索引的配置,如下代码。
1
2
3
4
this.Property(ls => DepartId).HasColumnAnnotation("DepartId ", new IndexAnnotation(new IndexAttribute("IX_ DepartId ")
{
IsUnique = true
}))
重要说明
上面这段代码是来自msdn中EF官方文档的代码,但我亲测不能生成正确的DbMigration配置,其生成的迁移代码如下(并不能正确生成索引):
1
2
3
4
5
6
7
8
AlterColumn("dbo.LineSpecific","LineBaseId", c => c.Int(nullable:false,
annotations:newDictionary<string, AnnotationValues>
{
{
"LineBaseId",
newAnnotationValues(oldValue:null, newValue:"IndexAnnotation: { Name: IX_LineBaseId, IsUnique: False }")
},
}));可以使用方式,请继续往下读
国外有同行把这个进行了封装,可以使用Fluent API的方式对映射中索引进行配置:
这个扩展中的代码很简单,主要就是通过反射完成了上面代码(那段不能工作的代码)的配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
//调用入口
public static EntityTypeConfiguration<TEntity> HasIndex<TEntity>(
this EntityTypeConfiguration<TEntity> entityTypeConfiguration,
string indexName,
Func<EntityTypeConfiguration<TEntity>, PrimitivePropertyConfiguration> propertySelector,
params Func<EntityTypeConfiguration<TEntity>, PrimitivePropertyConfiguration>[] additionalPropertySelectors)
where TEntity : class
{
return entityTypeConfiguration.HasIndex(indexName, IndexOptions.Nonclustered,
propertySelector, additionalPropertySelectors);
}
//一个支持多种参数的重载
public static EntityTypeConfiguration<TEntity> HasIndex<TEntity>(
this EntityTypeConfiguration<TEntity> entityTypeConfiguration,
string indexName, IndexOptions indexOptions,
Func<EntityTypeConfiguration<TEntity>, PrimitivePropertyConfiguration> propertySelector,
params Func<EntityTypeConfiguration<TEntity>, PrimitivePropertyConfiguration>[] additionalPropertySelectors)
where TEntity : class
{
AddIndexColumn(indexName, indexOptions, 1, propertySelector(entityTypeConfiguration));
for (int i = 0; i < additionalPropertySelectors.Length; i++)
{
AddIndexColumn(indexName, indexOptions, i + 2, additionalPropertySelectors[i](entityTypeConfiguration));
}
return entityTypeConfiguration;
}
//将IndexAttribute添加到IndexAnnotation
private static void AddIndexColumn(
string indexName,
IndexOptions indexOptions,
int column,
PrimitivePropertyConfiguration propertyConfiguration)
{
var indexAttribute = new IndexAttribute(indexName, column)
{
IsClustered = indexOptions.HasFlag(IndexOptions.Clustered),
IsUnique = indexOptions.HasFlag(IndexOptions.Unique)
};
var annotation = GetIndexAnnotation(propertyConfiguration);
if (annotation != null)
{
var attributes = annotation.Indexes.ToList();
attributes.Add(indexAttribute);
annotation = new IndexAnnotation(attributes);
}
else
{
annotation = new IndexAnnotation(indexAttribute);
}
propertyConfiguration.HasColumnAnnotation(IndexAnnotation.AnnotationName, annotation);
}
//对属性进行反射得到IndexAnnotation的帮助方法
private static IndexAnnotation GetIndexAnnotation(PrimitivePropertyConfiguration propertyConfiguration)
{
var configuration = typeof (PrimitivePropertyConfiguration)
.GetProperty("Configuration", BindingFlags.Instance | BindingFlags.NonPublic)
.GetValue(propertyConfiguration, null);
var annotations = (IDictionary<string, object>) configuration.GetType()
.GetProperty("Annotations", BindingFlags.Instance | BindingFlags.Public)
.GetValue(configuration, null);
object annotation;
if (!annotations.TryGetValue(IndexAnnotation.AnnotationName, out annotation))
return null;
return annotation as IndexAnnotation;
}
这个库的使用方式很简单,而且可以用Fluent API编码,最终代码颜值很高(代码来自官方示例):
1
2
3
4
5
6
7
.HasIndex("IX_Customers_Name", // Provide the index name.
e => e.Property(x => x.LastName), // Specify at least one column.
e => e.Property(x => x.FirstName)) // Multiple columns as desired.
.HasIndex("IX_Customers_EmailAddress", // Supports fluent chaining for more indexes.
IndexOptions.Unique, // Supports flags for unique and clustered.
e => e.Property(x => x.EmailAddress));
当然最重要的是这个库可以生成正确的Migration代码:
1
CreateIndex("dbo. Customers ", " EmailAddress ", unique: true);
映射包含继承关系的实体类
对于包含继承关系的实体类,在使用EF CodeFirst映射时可以采用TPH、TPT和TPC三种方式完成:
TPH:这是EF CodeFirst采用的默认方式,继承关系中的所有实体会被映射到同一张表。
TPT:所有类型映射到不同的表中,子类型所映射到的表只包含不存在于基类中的属性。子类映射的表的主键同时作为关联基类表的外键。
TPC:每个子类映射到不同的表,表中同时包含基类的属性。这种情况下查询非常复杂,真的完全不知道其存在的意义。后文也就不详细介绍了。
先介绍一下几演示所用的实体类,我们的产品类依然存在,这次多了几个孩子。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class Product
{
public int Id{ get; set; }
public string Name { get; set; }
public string Description { get; set; }
}
public class PaperProduct:Product
{
public int PageNum { get; set; }
}
public class ElectronicProduct : Product
{
public double LifeTime { get; set; }
}
public class CD : ElectronicProduct
{
public float Capacity { get; set; }
}
它们的关系如图所示:
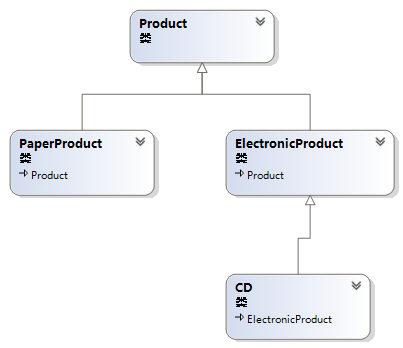
图1. Product类继承关系图
TPH(Table-Per-Hierarchy)
由于所有继承层次的类在一个表中,使用一个列区分这些类就是这种方式最重要的一点。默认情况下,EF CodeFirst使用一个名为Discriminator的列并以类型名字符串作为值来区分不同的类。
我们可以使用如下配置来修改这个默认设置,另外由于TPH是EF CodeFirst的默认选择,无需附加其他配置。
1
2
3
4
5
6
7
8
9
10
11
12
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
Map<Product>(p => { p.Requires("ProductType").HasValue(0); }).ToTable("Product");
HasKey(p => p.Id);
Map<PaperProduct>(pp => { pp.Requires("ProductType").HasValue(1); });
Map<ElectronicProduct>(ep => { ep.Requires("ProductType").HasValue(2); });
Map<CD>(cd => { cd.Requires("ProductType").HasValue(3); });
}
}
Requires方法指定区分实体的列的名称,HasValue指定区分值。
特别注意,如果想要自定义表名的话,ToTable要和Map<Product>()在一行中调用,且ToTable()在后。。
添加点数据做测试:
1
2
3
4
5
6
7
8
var product = new Product() { Name = "投影仪", Description = "高分辨率" };
var paperproduct = new PaperProduct() { Name = "《天书》", PageNum = 5 };
var cd = new CD() { Name = "蓝光大碟", LifeTime = 50, Capacity = 50 };
context.Set<Product>().Add(product);
context.Set<Product>().Add(paperproduct);
context.Set<Product>().Add(cd);
context.SaveChanges();
看一下数据库中表结构和数据:

图2. TPH下的数据表
EF按我们的配置添加了名为ProductType的列。当然我们也看到有很多为NULL的列。对于数据的查询不存在JOIN,就不再展示了。
TPT(Table-Per-Type)
这种方式下,所有存在于基类的属性被存储于一张表,每个子类存储到一张表,表中只存子类独有的属性。子类表的主键作为基类表的主键的外键实现关联。直接上配置代码:
1
2
3
4
5
6
7
8
9
10
11
12
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
ToTable("Product");
HasKey(p => p.Id);
Map<PaperProduct>(pp => { pp.ToTable("PaperProduct"); });
Map<ElectronicProduct>(ep => { ep.ToTable("ElectronicProduct"); });
Map<CD>(cd => { cd.ToTable("CD"); });
}
}
如下是迁移代码,按我们所想针对基类和子类都生成了表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
CreateTable(
"dbo.Product",
c => new
{
Id = c.Int(nullable: false, identity: true),
Name = c.String(),
Description = c.String(maxLength: 200),
})
.PrimaryKey(t => t.Id);
CreateTable(
"dbo.PaperProduct",
c => new
{
Id = c.Int(nullable: false),
PageNum = c.Int(nullable: false),
})
.PrimaryKey(t => t.Id)
.ForeignKey("dbo.Product", t => t.Id)
.Index(t => t.Id);
CreateTable(
"dbo.ElectronicProduct",
c => new
{
Id = c.Int(nullable: false),
LifeTime = c.Double(nullable: false),
})
.PrimaryKey(t => t.Id)
.ForeignKey("dbo.Product", t => t.Id)
.Index(t => t.Id);
CreateTable(
"dbo.CD",
c => new
{
Id = c.Int(nullable: false),
Capacity = c.Single(nullable: false),
})
.PrimaryKey(t => t.Id)
.ForeignKey("dbo.ElectronicProduct", t => t.Id)
.Index(t => t.Id);
我们使用TPH部分那段代码来插入测试数据,然后看一下查询生成的SQL。
先来查一下子类对象试试:
1
var productGet = context.Set<PaperProduct>().Where(r=>r.Id == 2).ToList();
生成的SQL看起来不错,就是一个INNER JOIN:
1
2
3
4
5
6
7
8
9
SELECT
'0X0X' AS [C1],
[Extent1].[Id] AS [Id],
[Extent2].[Name] AS [Name],
[Extent2].[Description] AS [Description],
[Extent1].[PageNum] AS [PageNum]
FROM [dbo].[PaperProduct] AS [Extent1]
INNER JOIN [dbo].[Product] AS [Extent2] ON [Extent1].[Id] = [Extent2].[Id]
WHERE 2 = [Extent1].[Id]
再来一个基类对象试试:
1
var productGet = context.Set<Product>().Where(r=>r.Id == 1).ToList();
这次悲剧了:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
SELECT
CASE WHEN (( NOT (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL))) AND ( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL)))) THEN '0X' WHEN (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL) AND ( NOT (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)))) THEN '0X0X' WHEN (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)) THEN '0X0X0X' ELSE '0X1X' END AS [C1],
[Extent1].[Id] AS [Id],
[Extent1].[Name] AS [Name],
[Extent1].[Description] AS [Description],
CASE WHEN (( NOT (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL))) AND ( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL)))) THEN CAST(NULL AS float) WHEN (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL) AND ( NOT (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)))) THEN [Project3].[LifeTime] WHEN (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)) THEN [Project3].[LifeTime] END AS [C2],
CASE WHEN (( NOT (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL))) AND ( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL)))) THEN CAST(NULL AS real) WHEN (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL) AND ( NOT (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)))) THEN CAST(NULL AS real) WHEN (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)) THEN [Project3].[Capacity] END AS [C3],
CASE WHEN (( NOT (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL))) AND ( NOT (([Project1].[C1] = 1) AND ([Project1].[C1] IS NOT NULL)))) THEN CAST(NULL AS int) WHEN (([Project3].[C1] = 1) AND ([Project3].[C1] IS NOT NULL) AND ( NOT (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)))) THEN CAST(NULL AS int) WHEN (([Project3].[C2] = 1) AND ([Project3].[C2] IS NOT NULL)) THEN CAST(NULL AS int) ELSE [Project1].[PageNum] END AS [C4]
FROM [dbo].[Product] AS [Extent1]
LEFT OUTER JOIN (SELECT
[Extent2].[Id] AS [Id],
[Extent2].[PageNum] AS [PageNum],
cast(1 as bit) AS [C1]
FROM [dbo].[PaperProduct] AS [Extent2] ) AS [Project1] ON [Extent1].[Id] = [Project1].[Id]
LEFT OUTER JOIN (SELECT
[Extent3].[Id] AS [Id],
[Extent3].[LifeTime] AS [LifeTime],
cast(1 as bit) AS [C1],
[Project2].[Capacity] AS [Capacity],
CASE WHEN (([Project2].[C1] = 1) AND ([Project2].[C1] IS NOT NULL)) THEN cast(1 as bit) WHEN ( NOT (([Project2].[C1] = 1) AND ([Project2].[C1] IS NOT NULL))) THEN cast(0 as bit) END AS [C2]
FROM [dbo].[ElectronicProduct] AS [Extent3]
LEFT OUTER JOIN (SELECT
[Extent4].[Id] AS [Id],
[Extent4].[Capacity] AS [Capacity],
cast(1 as bit) AS [C1]
FROM [dbo].[CD] AS [Extent4] ) AS [Project2] ON [Extent3].[Id] = [Project2].[Id] ) AS [Project3] ON [Extent1].[Id] = [Project3].[Id]
WHERE 1 = [Extent1].[Id]
试了几种写法,都不能改变把所有表都JOIN一遍的结果。看来是EF的问题。其实想想也对,Product类作为基类可以去引用子类的对象,生成这样的SQL使我们有机会把得到Product对象转换成子类对象。但我认为应该提供一种方法明确只获取基类对象(不用做任何JOIN)。是我不知道呢?还是EF就是没提供这样的方法呢?
对于TPH和TPT两种方式,前者会浪费一些存储空间,后者因为查询时JOIN损耗一些时间。个人认为对于子类和父类差别不太大的情况,可以选用TPH,这样不会浪费太多空间同时也能有很好的查询速度。而对于子类和父类差别较大的情况,TPT就是一个更好的选择。
将一个实体映射到多个表
在数据库设计中这常被称作垂直分割。还是通过例子来看具体实现。我们给产品类增加2个新属性:
1
2
3
4
5
6
7
8
9
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
//new property
public float Price { get; set; }
public float Weight { get; set; }
}
我们希望将新属性存储在另一张数据表中,可以按如下方式配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
Map(m =>
{
m.Properties(t => new { t.Id, t.Name, t.Description });
m.ToTable("Product");
})
.Map(m =>
{
m.Properties(t => new { t.Id, t.Price, t.Weight });
m.ToTable("ProductDetail");
});
HasKey(p => p.Id);
}
}
代码一目了然,分开指定属性和相应的表即可。生成的迁移代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
CreateTable(
"sample.Product",
c => new
{
Id = c.Int(nullable: false, identity: true),
Name = c.String(),
Description = c.String(maxLength: 200),
})
.PrimaryKey(t => t.Id);
CreateTable(
"sample.ProductDetail",
c => new
{
Id = c.Int(nullable: false),
Price = c.Single(nullable: false),
Weight = c.Single(nullable: false),
})
.PrimaryKey(t => t.Id)
.ForeignKey("sample.Product", t => t.Id)
.Index(t => t.Id);
是不是很眼熟,对!和之前配置1 - 1映射生成的迁移代码一模一样。当然生成的查询语句也是一样的。
将两个实体映射到一张表
我们把上一个例子中给Product增加的属性独立出来:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class Product
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public virtual ProductDetail ProductDetail { get; set; }
}
public class ProductDetail
{
public int Id { get; set; }
public float Price { get; set; }
public float Weight { get; set; }
public virtual Product Product { get; set; }
}
现在我们有2个实体类,接下来的配置将把它们映射到一张表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class ProductDetailMap : EntityTypeConfiguration<ProductDetail>
{
public ProductDetailMap()
{
HasKey(pd=>pd.Id).HasRequired(pd => pd.Product).WithRequiredPrincipal(p=>p.ProductDetail);
ToTable("Product");
}
}
public class ProductMap : EntityTypeConfiguration<Product>
{
public ProductMap()
{
HasKey(p => p.Id);
ToTable("Product");
}
}
生成的迁移代码可以看出,两个实体将被保存到一张表:
1
2
3
4
5
6
7
8
9
10
11
CreateTable(
"dbo.Product",
c => new
{
Id = c.Int(nullable: false, identity: true),
Name = c.String(),
Description = c.String(maxLength: 200),
Price = c.Single(nullable: false),
Weight = c.Single(nullable: false),
})
.PrimaryKey(t => t.Id);
映射部分就到这里了。休息下吧。
中场休息
借中场休息时间鄙视一下那些转载不保留原链接的网站,尤其像numCTO这种。
变更跟踪
变更跟踪指的是对缓存于EF Context中的实体的状态的跟踪与改变。所以了解变更跟踪先看了解一下实体在EF Context中的几种状态。下面是国外某网站看到的一幅很不错的图,直接拿过来用了。
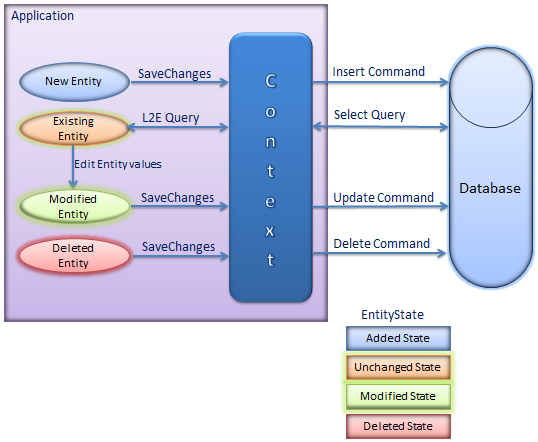
图3. EF Context中实体状态 来源
支持变更跟踪最关键的一点是实体必须有主键(如前文介绍通过Fluent API的HasKey<TKey>方法指定主键)。这样实体才能被EF Context这个缓存容器进行维护,并与数据库中相应的条目实现一一对应来支持增删改查。
变更跟踪是默认启用的,可以通过配置DbContext来关闭这个功能,如下代码:
1
context.Configuration.AutoDetectChangesEnabled = false;
注意:
一般来说不建议关闭变更跟踪,除非是只读(只读情况下用AsNoTracking获取实体并自己做缓存应该更好)。
在关闭变更跟踪的情况下,可以通过如下方法手动调用一次变更检测(或者用下文将介绍的手动状态改变),这样后续的SavaChanges操作才能正确完成。
1
context.ChangeTracker.DetectChanges();另外要注意的一点是,变更跟踪只能在一个上下文内有效。即如果有两个DbContext的实例,两个DbContext各自作用域内的变更跟踪是独立的。
除了使用自动变更跟踪,在对性能要求极端的情况下,也可以手动控制实体的状态(另一种情况是实体本不在当前Context中,要加入当前Context控制下必须手动完成)。
与实体变更控制最密切的就是DBEntityEntry类,这个类的对象正是通过前文介绍的DbContext的Entry<T>方法获得的。DBEntityEntry最重要的属性就是获取实体状态的State属性。
1
2
3
var entry = dbCtx.Entry(student);
Console.WriteLine("Entity State: {0}", entry.State );
context.Entry(student).State = EntityState.Deleted;
上面几行代码展示了查询与修改EF Context中实体状态的方法。
最后这段综合的代码示例演示了在关闭变更跟踪的情况下,手动修改实体状态实现更新。
1
2
3
4
5
6
context.Configuration.AutoDetectChangesEnabled = false;
var student = context.Set<Student>().FirstOrDefault(s => s.StudentName == "张三");
student.StudentName = "王五";
var stuEntry = context.Entry(student);
stuEntry.State = EntityState.Modified;
context.SaveChanges();
AsNoTracking
对于只读操作,强烈建议使用AsNoTracking进行数据获取,这样省去了访问EF Context的时间,会大大降低数据获取的时间。
1
var student = context.Set<Student>().AsNoTracking().FirstOrDefault(s => s.StudentName == "王五");
由于没有受EF Context管理,对于这样获取到的数据,更新的话需要先Attach然后手动修改状态并SaveChanges。
1
2
3
4
5
student.StudentName = "张三";
context.Set<Student>().Attach(student);
var stuEntry = context.Entry(student);
stuEntry.State = EntityState.Modified;
context.SaveChanges();
数据加载
EF中和数据加载关系最密切的方法是IQueryable中名为Load的方法。Load方法执行数据查询并把获取的数据放到EF Context中。Load()和我们常用的ToList()很像,只是它不创建列表只是把数据缓存到EF Context中。
1
2
var productGet = context.Set<Product>().Where(r=>r.Id == 1).ToList();
context.Set<Product>().Where(r=>r.Id == 1).Load();
第一行代码我们把数据加载到EF Context中并创建一个列表并返回,第二个方法我们只是把数据加载到EF Context中。默认情况下我们很少会直接用到Load方法,一般ToList或First这样的方法就帮我们完成加载数据操作了。
延迟加载
EF默认使用延迟加载获取导航属性关联的数据。还是以之前用过的产品和发票为例。通过这个下面代码和注释很容易理解这个特性。
1
2
3
4
//此时不会加载Invoice属性关联的对象
var productGet = context.Set<Product>().First(r=>r.Id == 1);
//直到用到Invoice时,才会新起一个查询获取Invoice
var date = productGet.Invoice.CreateDate;
作为默认配置的延迟加载,需要满足以下几个条件:
-
context.Configuration.ProxyCreationEnabled = true;
-
context.Configuration.LazyLoadingEnabled = true;
-
导航属性被标记为virtual
这三个条见缺一不可。
如果不满足条件,延迟加载则不会启用,这时候我们必须使用手动加载的方式来获取关联数据,否则程序在访问到导航属性又没法进行延迟加载时就会报空引用异常。
手动加载就是通过DbReferenceEntry的Load方法来实现。我们把设置context.Configuration.LazyLoadingEnabled = false;(全局禁用延迟加载)以便在没有延迟加载的环境进行测试。
把导航属性virtual去掉可以禁用单个实体的延迟加载。
1
2
3
4
5
//此时不会加载Invoice属性关联的对象
var productGet = context.Set<Product>().First(r=>r.Id == 1);
//手动加载Invoice
context.Entry(productGet).Reference(p => p.Invoice).Load();
var date = productGet.Invoice.CreateDate;
与自动延迟加载一样,手动加载也是两条独立的SQL分别获取数据。手动加载集合属性也类似,就是把Reference方法换成Collection方法。以ProductPhoto为例:
1
2
3
4
5
//此时不会加载Invoice属性关联的对象
var productGet = context.Set<Product>().First(r=>r.Id == 1);
//手动加载Photos集合
context.Entry(productGet).Collection(p => p.Photos).Load();
var count = productGet.Photos.Count;
预加载
延迟加载包括手动加载这些方式中,获取关联数据都需要两条独立的SQL。如果我们确实同时需要一个对象及其关联数据,可以使用预加载以使它们通过一条SQL获取。在之前测试关联的代码中,我们已多次使用到预加载。
1
var product = context.Set<Product>().Include(p=>p.Invoice).FirstOrDefault();
这是之前用于测试的一条语句。我们同时再加产品及其发票,生成的SQL中使用了JOIN由两个表获取数据。
预加载就是使用Include方法并传入需要同时获取的关联属性。我们也可以使用字符串传入属性的名称,如:
1
var product = context.Set<Product>().Include("Invoice").FirstOrDefault();
但这样肯定没有使用lambda更有利于避免输入错误。
预加载也支持同时加载二级属性,比如我们给Invoice增加一个开票人属性,这是一个Employee对象。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
public class Invoice
{
public int Id { get; set; }
public string InvoiceNo { get; set; }
public DateTime CreateDate { get; set; }
public virtual Employee Drawer { get; set; }
}
public class Employee
{
public int Id { get; set; }
public string Name { get; set; }
public string EmpNo { get; set; }
}
如下代码,我们可以在查询Product同时加载Invoice和Employee。
1
var product = context.Set<Product>().Include(p=>p.Invoice.Drawer).FirstOrDefault();
同样字符串参数也是支持的:
1
var product = context.Set<Product>().Include("Invoice.Drawer").FirstOrDefault();
此时生成的SQL会含有2次JOIN,代码太长就不列出了。
并发
本着实用的原则(其实主要原因是博主的理论知识也只是自己心里明白,做不到给大家讲明白的程度),这部分就不讲太多关于数据库隔离级别以及不同隔离级别并发时出现的结果等等。
我们使用最简单的Product类进行测试,先写入一条数据:
1
2
3
var product = new Product() { Name = "投影仪", Description = "高分辨率" };
context.Set<Product>().Add(product);
context.SaveChanges();
然后我们编写一个并发测试类来模拟2个用户同时编辑同一个Product的情况:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
public class ConcurrencyTest : IDisposable
{
private readonly DbContext _user1Context;
private readonly DbContext _user2Context;
public ConcurrencyTest()
{
_user1Context = new CodeFirstForBlogContext();
_user2Context = new CodeFirstForBlogContext();
}
public void EditProductConcurrency()
{
User1Edit();
User2Edit();
User2Save();
User1Save();
}
private void User1Edit()
{
var product = _user1Context.Set<Product>().First();
product.Name = product.Name +" edited by user1 at " + DateTime.Now.ToString("MM-dd HH:mm:ss");
}
private void User1Save()
{
_user1Context.SaveChanges();
}
private void User2Edit()
{
var product = _user2Context.Set<Product>().First();
product.Name = product.Name + " edited by user2 at " + DateTime.Now.ToString("MM-dd HH:mm:ss");
}
private void User2Save()
{
_user2Context.SaveChanges();
}
public void Dispose()
{
Dispose(true);
GC.SuppressFinalize(this);
}
protected virtual void Dispose(bool disposing)
{
if (disposing == true)
{
_user1Context.Dispose();
_user2Context.Dispose();
}
}
~ConcurrencyTest()
{
Dispose(false);
}
}
我们之前看到的那些Fluent API配置都没有启用并发支持,我们在没有并发支持的情况下看看这段代码的执行情况:
1
2
3
4
using (ConcurrencyTest test = new ConcurrencyTest())
{
test.EditProductConcurrency();
}
运行,我们可以看到在User2Save执行后被写入的数据,完全被User1Save所写入的数据覆盖了。也就是说User2的修改丢失了。
怎样避免呢,这就需要启用并发支持。EF只支持乐观并发,以上面情况为例也就是说当出现上面情况时EF会抛出异常(DbUpdateConcurrencyException),使User1无法提交,从而保护User2的修改不被覆盖。
怎么启用并发乐观支持呢?
我们给Product添加一个属性标识数据版本,属性名随意起,类型必须是byte[]。
1
public byte[] RowStamp { get; set; }
在Fluent API中需要这样配置以指定RowStamp作为并发标识:
1
Property(p => p.RowStamp).IsRowVersion();
重新执行迁移,然后在运行之前的并发测试方法,此时User1Save方法调用时就会报异常,如图:
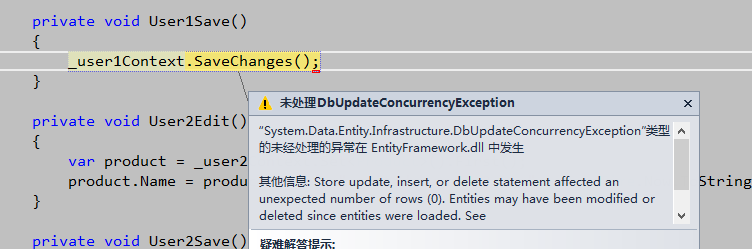
图3. 乐观并发开启时同时编辑导致的异常
怎样处理这中情况呢?有很多种策略。我们先修改一下User1Save,在其中捕获一下DbUpdateConcurrencyException,我们的处理实在这个异常的catch中完成的。
1
2
3
4
5
6
7
8
9
10
11
private void User1Save()
{
try
{
_user1Context.SaveChanges();
}
catch (DbUpdateConcurrencyException concurrencyEx)
{
//处理异常
}
}
策略1:使用数据库数据
异常处理部分代码如下:
1
2
3
4
5
catch (DbUpdateConcurrencyException concurrencyEx)
{
concurrencyEx.Entries.Single().Reload();
_user1Context.SaveChanges();
}
Reload表示由数据库中重新加载数据并覆盖当前保存失败的对象。这样User2的修改会被保存下来,User1的修改丢失。如同不在catch中做任何处理的效果。
策略2:使用客户端数据
异常处理部分代码如下:
1
2
3
4
5
6
catch (DbUpdateConcurrencyException concurrencyEx)
{
var entry = concurrencyEx.Entries.Single();
entry.OriginalValues.SetValues(entry.GetDatabaseValues());
_user1Context.SaveChanges();
}
使用数据库获取的值来填充保存失败的对象的OriginalValues属性(原始值),这样这个保存失败对象(User1的修改)再次提交时,数据库就不会因为原始值(OriginalValues)与数据库里现有值不同而产生异常了。最终结果就是User1的修改被保存,User2的修改被覆盖。这种结果和不启用乐观并发是一样的。
策略3:由用户决定合并结果
异常处理部分代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
catch (DbUpdateConcurrencyException concurrencyEx)
{
var entry = concurrencyEx.Entries.Single();
var databaseValues = entry.GetDatabaseValues();
var currentEntity = (Product)entry.CurrentValues.ToObject();
var databaseEntity = (Product)entry.GetDatabaseValues().ToObject();
// 我们将数据库的现有值作为默认的合并结果。合并过程中可以在这基础上修改。
var resolvedEntity = (Product)databaseValues.Clone().ToObject();
// 在这个函数中,用户实现合并方法决定最终写入数据库的值
UserResolveConcurrency(currentEntity, databaseEntity, resolvedEntity);
// 同样要把数据库的值写入OriginalValues,以保证不在此触发并发异常
// 把合并值作为CurrentValues,其将被提交到数据库
entry.OriginalValues.SetValues(databaseValues);
entry.CurrentValues.SetValues(resolvedEntity);
_user1Context.SaveChanges();
}
道理很简单,我们就是分别取出现有值和数据库值,留给用户去决定合并结果并提交回数据库。通过代码中注释可以很容易理解。
其中调用的合并函数如下:
1
2
3
4
5
6
7
private void UserResolveConcurrency(Product currentEntity, Product databaseEntity, Product resolvedEntity)
{
//由用户决定 怎样合并currentEntity和databaseEntity得到resolvedEntity
Debug.WriteLine(string.Format("current(user1):Name-{0}",currentEntity.Name));
Debug.WriteLine(string.Format("database(user2):Name-{0}", databaseEntity.Name));
resolvedEntity.Name = resolvedEntity.Name + " Merged by user1";
}
当然这个函数是随便实现的,大家应该根据实际业务场景仔细设计这个函数的实现。
根据这个函数的实现,程序执行后,最终Product的Name被更新为:投影仪 edited by user2 at 08-07 21:12:18 Merged by user1
除了对整行启用乐观并发支持外,还可以针对单个列启用乐观并发支持。如我们可以使用下面的代码把Product的Name属性配置为受乐观并发管理。
1
Property(p => p.Name).IsConcurrencyToken();这样只有当Name出现并发修改时,才会抛出异常,异常的处理方式与之前介绍的相同。
异步
C#5.0开始增加了async和await关键字,配合.NET Framework 4.5大大简化了异步方法的实现和调用。EF也顺应趋势在6.0起开始支持异步操作。
EF中异步操作分为2部分异步获取数据及异步提交数据。
异步提交数据只有一种途径,就是DbContext中的SaveChangesAsync方法。关于异步方法怎么调用本文不细说了,那是另一个大主题。园子也有很多相关文章。
关于异步推荐一本书《C#并发编程经典实例》。这本书还没有翻译版的时候我就找英文电子版读过一遍,受益匪浅。
关于异步获取数据根据场景不同有很多种选择,列举几个方法在下面:
-
FindAsync
-
LoadAsync
-
FirstAsync
-
FirstOrDefaultAsync
-
ToListAsync
可能还有其他不一一列举了。
一般现在项目都使用各种结构大致类似的IRepository/ConcreteRepository接口/类包装EF,我们只需要根据同步方法添加异步方法并调用上面这些EF中提供的异步方法,就可以很轻松的让我们存储层支持异步。
异步方法一个很大的特点就是传播性,基本上我们存储层的代码改成异步,上面所有调用代码也都要以异步实现。所以让项目支持异步还是一个需要从开始就规划的工作,后期改的话成本有点高。
迁移
我们使用系统中设计好的实体以及映射配置来创建数据库或将对实体的修改应用到已存在的数据库都需要用到EF的迁移支持。EF从4.3开始支持自动迁移。我们先来看下怎样启用这个功能:
启用迁移
启用迁移需要在VS的程序包管理控制台输入命令来完成,命令如下
Enable-Migrations –EnableAutomaticMigrations
注意:程序包管理控制台中选择的项目应该是DbContext所在的项目,否则这条PowerShell命令会执行出错。
命令成功执行后项目目录中会多出一个名为Migrations的文件夹,里面有个Configuration.cs文件。
1
2
3
4
5
6
7
8
9
10
11
12
internal sealed class Configuration : DbMigrationsConfiguration<SchoolContext>
{
public Configuration()
{
AutomaticMigrationsEnabled = true;
ContextKey = "EF6Sample.SchoolContext";
}
protected override void Seed(SchoolContext context)
{
}
}
这个类是支持迁移的关键,PowerShell中的EnableAutomaticMigrations参数会让Configuration类的构造函数添加AutomaticMigrationsEnabled=true这条语句。
ContextKey属性用来执行这个迁移关联的DbContext,这样多个DbContext共存迁移不会产生冲突。
Seed方法是在迁移过程数据库Schema成功应用以后执行的操作,可以利用这个方法添加一些初始化数据:
1
2
3
4
5
6
7
8
9
protected override void Seed(SchoolContext context)
{
context.Set<Student>().AddOrUpdate(
p => p.StudentName,
new Student { StudentName = "张三" },
new Student { StudentName = "李四" },
new Student { StudentName = "王五" }
);
}
自动迁移
开启迁移支持后,实现迁移,还需要配置下DbContext。需要在DbContext的构造函数中完成:
1
Database.SetInitializer(new MigrateDatabaseToLatestVersion<SchoolContext , Configuration>("SchoolDBConnectionStr"));
这样在项目运行时,迁移将自动完成。即如果数据库不存在,将自动创建数据库。如果数据库已存在但Schema不是最新,数据库也会被自动更新。
EF怎样选择使用的数据库
EF CodeFirst不像ADO.NET2.0那样必须使用链接字符串明确指定数据库的位置,也不像EDM需要一个冗长的可读性很低的链接字符串。还有用“盗”来的图说明EF CodeFirst数据库选择策略了,这图真可谓一目了然:
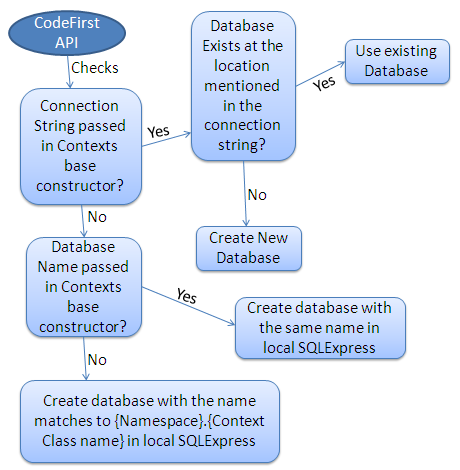
图4. EF CodeFirst数据库选择策略 来源
由图可知,在完全不指定链接字符串的情况下,EF CodeFirst也会自动选择一个数据库,当然我们大家项目的配置文件中中都会明确指定链接字符串不是吗?
手动迁移
如果不喜欢自动迁移,可以手工完成这个操作。手工迁移的好处后,可以随时退回到某个指定的迁移版本。迁移文件也可以进行版本管理有利于团队开发。
首先把Configuration构造函数中AutomaticMigrationsEnabled置为false,表示不使用自动迁移。
手动迁移的操作也是在程序包管理控制台使用PowerShell来完成,在每次更改实体或映射配置后,我们运行下面这个命令来生成一个迁移文件:
Add-Migration ChangeSet1
命令成功执行后会生成一个迁移文件,其内容就是EF在迁移时执行的操作。
1
2
3
4
5
6
7
8
9
10
11
12
public partial class ChangeSet1 : DbMigration
{
public override void Up()
{
AddColumn("dbo.Student", "Age", c => c.Int(nullable: false));
}
public override void Down()
{
DropColumn("dbo.Student", "Age");
}
}
成功生成迁移文件后,运行下面命令,EF就开始执行迁移操作,并把数据库更新到最新的迁移文件对应的版本。
Update-Database
这条命令有几个常用的参数
Update-Database -Verbose
可以查看迁移在数据库中执行的详细操作(SQL等)
Update-Database -TargetMigration ChangeSet1
这个参数可以指定目标迁移版本,对于需要退回到指定版本的情况很有用。
关于数据库初始化器
在之前的代码中,我们给Database.SetInitializer方法传递一个名为MigrateDatabaseToLatestVersion的初始化器,EF还有其他几种初始化其的选择:
CreateDatabaseIfNotExists:如果不存在数据库则新建。但如果数据库已存在,且模型变化会出现异常。
DropCreateDatabaseIfModelChanges:当模型变化时删除并重建数据库
DropCreateDatabaseAlways:每次实例化DbContext时都删除并重建数据库
自定义DB Initializer:实现IDatabaseInitializer,定义自己的初始化数据库逻辑
对于这几种只能说然并卵。对于开发环境MigrateDatabaseToLatestVersion足够好用了。对于生成环境数据库已经很稳定的情况,可以直接给Database.SetInitializer方法传null以禁用数据库初始化。
未涉及
本文未涉及的内容包括
-
映射存储过程/表值函数
-
执行原生SQL查询
-
枚举/空间数据类型
-
自定义实体验证
-
CodeFirst映射约定/配置映射约定
-
EF6版本DbContext.Database中的事务支持
-
EF6的日志支持
-
EF6基于代码的配置
不涉及这些的原因是是博主我几乎没用过写出来也误导人。
未来
据说EF的下一个版本中底层很多部分都是重写,不知道会不会对API有什么影响。当然我们都希望对使用习惯影响不大的情况下EF可以大大提高性能。
基于.NET跨平台的大趋势,EF7开始支持Linux平台中常用的PostgreSQL数据库。基于NoSQL的大趋势,EF7开始支持Azure Table Service和Redis这样的NoSQL存储工具。
一个很值得期待的方面是EF7开始支持Windows Universal App并官方支持SQLite数据,这样在Windows Universal App中使用EF访问SQLite数据库就不需要像现在这样蛋疼的先找一个WinRT C++/CX对SQLite C Api的封装,然后再找一个C#调用C++/CX的封装。总之在给开发者提供开发便利方面MS还是很有进取心的。
最后
最后分享一个网上看到的很好的EF教程,文中的几幅图片都是来自这个网站。
作为.NET方面数据访问的官方力量,EF还是很值得去学习的,仅以此文与大家共勉。
2015-08-02 补充1
这段补充主要是回答61楼网友的问题,正好也把映射部分一些遗漏的细节写上。
多对多映射中关联表添加自定义列
有些时候我们需要在关联表中添加一些自定义列,正如61楼网友的需求。这里我将以前文的例子来介绍这个需求如何实现。
在前文例子中我们通过Product和Tag演示了怎样配置多对多关联,现在我们需要给它们的关联表增加一个列,用来表示Tag的显示顺序。这种情况下需要手工创建一个关联实体,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
public class ProductTag
{
public int Id { get; set; }
public int ProductId { get; set; }
public int TagId { get; set; }
//给关联表增加的列,表示标签的顺序
public int Order { get; set; }
public virtual Product Product { get; set; }
public virtual Tag Tag { get; set; }
}
已有的Product和Tag类也需要修改来和这个ProductTag进行关联:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class Product
{
public int Id{ get; set; }
public string Name { get; set; }
public string Description { get; set; }
public virtual ICollection<ProductTag> ProductTags { get; set; }
}
public class Tag
{
public int Id { get; set; }
public string Text { get; set; }
public virtual ICollection<ProductTag> ProductTags { get; set; }
}
这种配置的重点在于ProductTag的映射:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class ProductTagMap:EntityTypeConfiguration<ProductTag>
{
public ProductTagMap()
{
ToTable("Product_Tag_Map");
HasKey(pt => pt.Id);
Property(pt => pt.Order);//这行可有可无,这里为了演示就加上了。
HasRequired(pt => pt.Product)
.WithMany(p => p.ProductTags)
.HasForeignKey(pt => pt.ProductId);
HasRequired(pt => pt.Tag)
.WithMany(t => t.ProductTags)
.HasForeignKey(pt => pt.TagId);
}
}
我们把多对多映射放在了关联实体映射中,Product和Tag就不需要做任何其他和多对多有关的映射了。
这样就实现了文初的目的。补充先到此,再有需要再做补充
https://www.cnblogs.com/lsxqw2004/archive/2015/08/07/4701979.html