Docker & Kubernetes : Pods and Service definitions
https://www.bogotobogo.com/DevOps/Docker/Docker_Kubernetes_Pods_Services_Yaml.php
Kubernetes 是pilot(航空器-驾驶员)helmsman(舵手)。
它抽象掉了硬件基础设施, 暴露真个数据中心作为一个单独巨大的计算资源。
Docker or rkt (pronounced “rock-it”)?
Kubernetes is Greek for pilot or helmsman (the person holding the ship’s steering wheel).
Kubernetes abstracts away the hardware infrastructure and exposes a whole datacenter as a single enormous computational resource.
Kubernetes Architecture

主控节点:
API服务器: 集群的网关, 提供rest的接口, 连接master各个组件, 以及worknode组件。 系统的心脏。
调度器: 观察未进行调度的POD, 并把它绑定到节点上。
etcd:所有集群状态存储在此数据库中。
控制管理器:其它集群级别的功能, 例如: 节点控制器,副本控制器,端点控制器。
Master(Cluster control plane)
The Kubernetes control plane is split into a set of components, which can all run on a single master node, or can be replicated in order to support high-availability clusters.The following 4 processes should be running on every master node.
- API Server: This is a cluster gateway. It is intended to be a relatively simple server mainly processes REST operations. It is responsible for establishing communication between Kubernetes Node and the Kubernetes master components.
kubectlis the command line utility that interacts with Kubernetes API. It is also working as a gatekeeper for authentication.
- Scheduler: It watches for unscheduled pods and binds them to nodes via the /binding pod subresource API. The scheduler obtains resource usage data for each worker node from "etcd" via the API server.
- Cluster state store (etcd): All persistent cluster state is stored in etcd. It is the single source of truth for all components of a cluster. Etcd stores the configuration data of the Kubernetes cluster, representing the state of the cluster at any given point in time.
- Controller-Manager: Most other cluster-level functions are currently performed by a separate process, called the "Controller Manager". It performs both lifecycle functions (garbage collections) and API business logic (such as scaling of pods controlled by a ReplicaSet). It provides self-healing, scaling, application lifecycle management, service discovery, routing, and service binding and provisioning.
Each controller tries to move the current cluster state closer to the desired state.
- kube controller manager: controller that watches the node, replication set, endpoints (services), and service accounts.
- cloud controller manager: Interacts with the underlying cloud provider to manage resources.
- Node controller
- Replication controller
- Endpoint controller
- Service accounts and token controller
工作节点:
kubelet:运行在节点上的代理, 管理节点和POD
kube-proxy: 运行在节点上的网络代理。
CRI : 容器运行时。
Worker Node
Every worker node should be running 3 processes: kubelet, kube-proxy, and container runtime as listed below:
- kubelet: An agent running on each node. It is the most important and most prominent controller in Kubernetes. kubelet interacts with a node and pods within the node. It is the primary implementer of the Pod and Node APIs that drive the container execution layer. It makes sure the containers are running and if any pod has issue, it tries to restart the pod.
- kube-proxy: A network agent running on each node. It exposes services to the outside world. It is responsible for maintaining network configuration and iptable rules. It creates a virtual IP which clients can access and which is transparently proxied to the pods in a Service.
- container runtime: Docker is the most prominent runtime. Others are rkt, cri-o, and containerd.
Also, check Kubernetes Design and Architecture for the details of each components of the picture.
Service Definition
Each Pod has its own IP address but Pods are ephemeral (destroyed frequently). When a Pod get restarted, it will have a new IP address (a new IP address on re-creation). So, it does not make any sense to use Pods IP addresses. However, the service has its own IP address and even when a Pod dies the service retains its IP address. Unlike the IP of a Pod, the IP address of a service is stable. In other words, the lifecycles of a service and Pod are not connected!
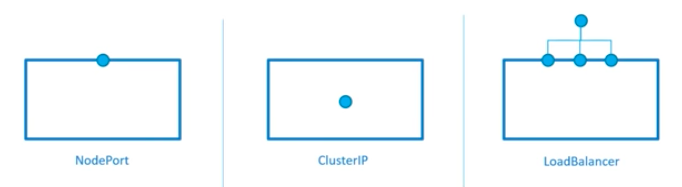
From Kubernetes - Services Explained
NodePort 暴露服务在每个节点的物理IP上。
ClusterIP: 默认类型, 暴露服务在集群内IP上。
LoadBalancer:通过云提供商的负载均衡器,暴露服务。
Ingress: 不是服务类型,是一种组合服务的路由器。
- NodePort: Exposes the service on each Node's public IP at a static port.
From outside.
- ClusterIP: This is the default service type and we don't have to specify a service type. It exposes the service on an internal-cluster IP.
From inside (reachable only from within the cluster)
- LoadBalancer: This service type exposes the service via cloud provider's LB. The services to which LB will route are created automatically.
From outside.
Note: However, when we want to expose multiple applications there are some issues and challenges. For each application:Also, there is no centralization of certs and logs.
- One LB resource (i.e. AWS)
- At lest one public IP
- DNS name (CNAME)
Ingress comes to the rescue.
- Headless Service: We can create headless service when we specify a Service with .spec.clusterIP set to None. This service type can be used when
So, in those cases, the Pod is not selected randomly (default load balancing behavior of a service). One example for using the Headless service type is a stateful application such as database. To talk directly to a specific Pod, a client makes a DNS lookup. By setting the clusterIP set to None, the service returns a Pod IP address instead of the Cluster IP address. Check Headless Service.
- A client wants to communicate with a specific Pod.
- Pods want to talk directly with a specific Pod.
- Ingress: Ingress, unlike the services listed above, is actually NOT a type of service but acts as a router or an entry point to our cluster.
Ingress allows simple host or URL based HTTP routing.
An ingress is a core concept of Kubernetes, but is always implemented by a third party proxy.
These implementation is known as ingress controller which is responsible for processing the Ingress Resource information.
Note that the Ingress is just a description of how routing should be performed. The actual logic has to be performed by an "Ingress Controller". So, creating Ingress resources in a Kubernetes cluster won't have any effect until an Ingress Controller is available.
EndPoints - Optional
每个POD都有对应的 POD ID + 端口
这个内容被关联到服务中, 就称为端点, 集群内通信使用, 用户不用关心。
Though we usually do not directly manipulate the EndPoint, it may bother us if we do not know what it is.
EndPoint is a defined object in API server itself. An Endpoint object is automatically created for us when we create a service. Actually, it's an optimization.
Here is a summary about what is an EndPoint:
- K8s creates an EndPoint object when we create a service.
- Its name is the same as the name of the service.
- Whenever a pod is recreated or updated, the EndPoint is changed and K8s uses this EndPoint to keep track of Pods: which Pods are the members of a service.
In Kubernetes many controllers want to know IP addresses of all pods associated with a service. Because we have many many pods in Kubernetes and it's expensive asking the API server to go and find the selector. Kubernetes group them together in an object called Endpoints so that instead of constantly deriving this information over and over again, it's cached for us inside this object.
So, when a service is created, an Endpoint is created with one-to-one mapping, generally with a service that has the same selector. The pod (that has selector) list of the Endpoint is dynamically kept up to date.
Service Types - ClusterIP, NodePort, LoadBalancer
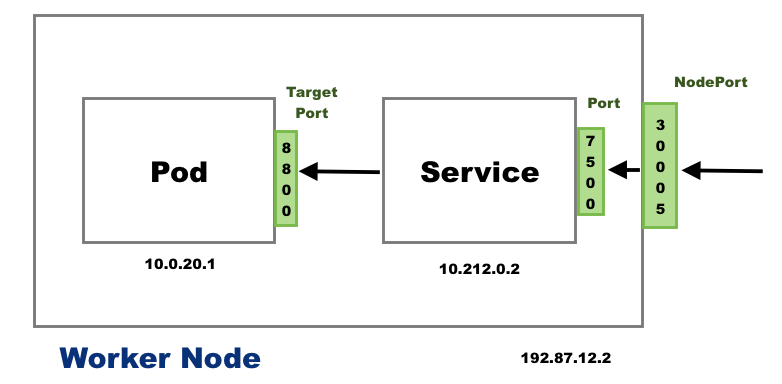
服务的三个端口
NodePort: 工作节点端口
TargetPort: POD端口
Port: 服务器端口
There are 3 ports involved with the service. They are named in service perspective and the ways of exposing our application.
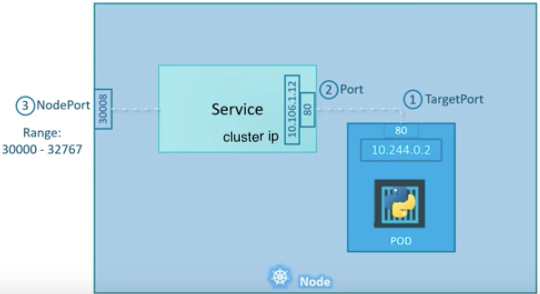
- TargetPort: a port on the Pod where an actual web server is running, port 80. This is called target port because that's the port to which the service forward the request to.
- Port: a port on the service itself. Service creates a virtual ip inside a cluster to enable communications between different services. We can only access this service while inside the cluster. If a targetPort is set in spec, it will route from the (service) port to the targetPort.
- NodePort: a port on the node itself. This is the port we used to access the web server externally. Our NodeIP is the external IP address of the node.
When a user sets the Service type field to NodePort, the Kubernetes master allocates a static port from a range, and each Node will proxy that port into our Service.
Note that, however, NodePorts are not designed to be directly used for production.
Please check Docker & Kubernetes : NodePort vs LoadBalancer vs Ingress
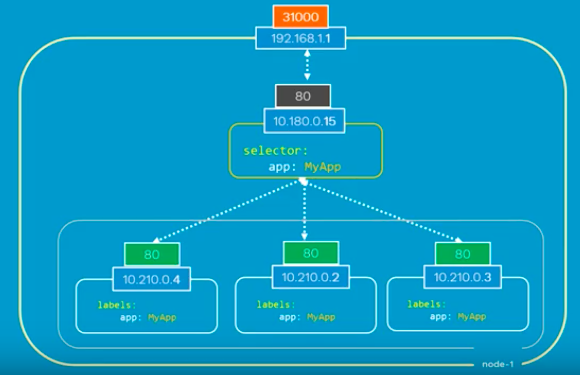
Multiple Pods in a host (node)
一个服务集成了多个POD, 本身就是一个小的负载均衡器。
What if there are multiple pods in a host (node)?
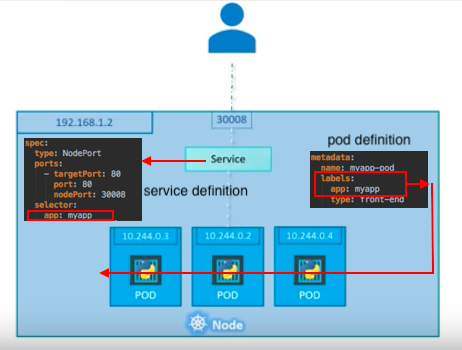
In that case, as shown in the picture above, all the pods will have the same labels with a key which is set to myapp as a selector during the creation of the service. So, when the service is created, it will look for pods with the matching label, myapp, and find three of them. The service then automatically selects all the three pods as endpoints and forwards requests coming from the user. The service, by default, acts as a built-in load balancer for us using a random algorithm to distribute the loads across our pods.
In this case, traffic distribution among the pods is up to the service:
Multiple(distributed) nodes - Load Balancer
外部负载均衡器, 将外部请求转发到空闲的Node节点, 然后进入service, 转发到POD
Here is another scenario that we have distributed pods across multiple nodes. This is probably one of the most common cases in a real production situation:
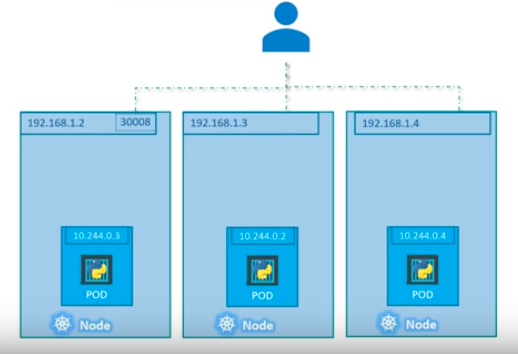
Thanks to Kubernetes, in this case again, we do not have to do anything regarding the configuration to make it work because Kubernetes creates service spans across all the nodes in the cluster and maps the target port to the same NodePort for all the nodes in the cluster. Because of that, we can access to our application via IP of any nodes on the same port which is 31000.
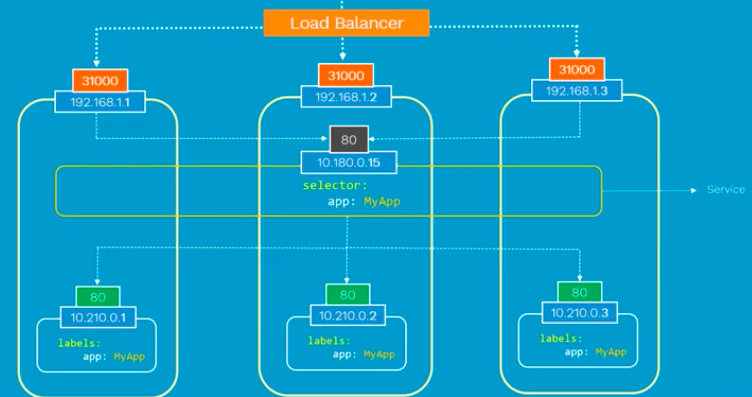
Note that this is on Layer 4 (Ingress is on Layer 7). Also note that the exact implementation of a LoadBalancer is dependent on the cloud provider. So, unlike the NodePort service type, not all cloud providers support the LoadBalancer service type.
