Apache Airflow
https://airflow.apache.org/
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Scalable
Elegant
https://github.com/apache/airflow/
Apache Airflow (or simply Airflow) is a platform to programmatically author, schedule, and monitor workflows.
When workflows are defined as code, they become more maintainable, versionable, testable, and collaborative.
Use Airflow to author workflows as directed acyclic graphs (DAGs) of tasks. The Airflow scheduler executes your tasks on an array of workers while following the specified dependencies. Rich command line utilities make performing complex surgeries on DAGs a snap. The rich user interface makes it easy to visualize pipelines running in production, monitor progress, and troubleshoot issues when needed.
架构
https://zhuanlan.zhihu.com/p/84332879
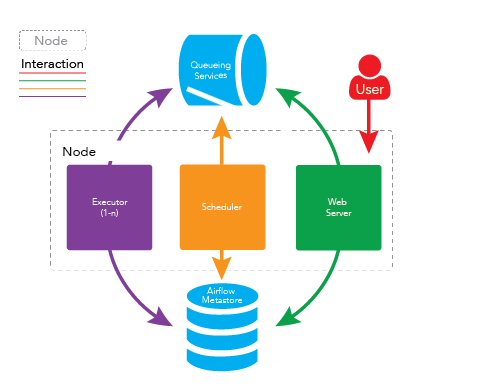
Airflow 的架构
在一个可扩展的生产环境中,Airflow 含有以下组件:
- 元数据库:这个数据库存储有关任务状态的信息。
- 调度器:Scheduler 是一种使用 DAG 定义结合元数据中的任务状态来决定哪些任务需要被执行以及任务执行优先级的过程。 调度器通常作为服务运行。
- 执行器:Executor 是一个消息队列进程,它被绑定到调度器中,用于确定实际执行每个任务计划的工作进程。 有不同类型的执行器,每个执行器都使用一个指定工作进程的类来执行任务。 例如,LocalExecutor 使用与调度器进程在同一台机器上运行的并行进程执行任务。 其他像 CeleryExecutor 的执行器使用存在于独立的工作机器集群中的工作进程执行任务。
- Workers:这些是实际执行任务逻辑的进程,由正在使用的执行器确定。
airflow xcom 数据传递
https://www.cnblogs.com/lshan/p/11721148.html
https://github.com/apache/airflow/blob/master/airflow/example_dags/example_xcom.py
from airflow import DAG from airflow.operators.python import PythonOperator from airflow.utils.dates import days_ago dag = DAG( 'example_xcom', schedule_interval="@once", start_date=days_ago(2), default_args={'owner': 'airflow'}, tags=['example'] ) value_1 = [1, 2, 3] value_2 = {'a': 'b'} def push(**kwargs): """Pushes an XCom without a specific target""" kwargs['ti'].xcom_push(key='value from pusher 1', value=value_1) def push_by_returning(**kwargs): """Pushes an XCom without a specific target, just by returning it""" return value_2 def puller(**kwargs): """Pull all previously pushed XComs and check if the pushed values match the pulled values.""" ti = kwargs['ti'] # get value_1 pulled_value_1 = ti.xcom_pull(key=None, task_ids='push') if pulled_value_1 != value_1: raise ValueError(f'The two values differ {pulled_value_1} and {value_1}') # get value_2 pulled_value_2 = ti.xcom_pull(task_ids='push_by_returning') if pulled_value_2 != value_2: raise ValueError(f'The two values differ {pulled_value_2} and {value_2}') # get both value_1 and value_2 pulled_value_1, pulled_value_2 = ti.xcom_pull(key=None, task_ids=['push', 'push_by_returning']) if pulled_value_1 != value_1: raise ValueError(f'The two values differ {pulled_value_1} and {value_1}') if pulled_value_2 != value_2: raise ValueError(f'The two values differ {pulled_value_2} and {value_2}') push1 = PythonOperator( task_id='push', dag=dag, python_callable=push, ) push2 = PythonOperator( task_id='push_by_returning', dag=dag, python_callable=push_by_returning, ) pull = PythonOperator( task_id='puller', dag=dag, python_callable=puller, ) pull << [push1, push2]
PythonOperator
https://github.com/apache/airflow/blob/master/airflow/example_dags/example_python_operator.py
import time from pprint import pprint from airflow import DAG from airflow.operators.python import PythonOperator, PythonVirtualenvOperator from airflow.utils.dates import days_ago args = { 'owner': 'airflow', } dag = DAG( dag_id='example_python_operator', default_args=args, schedule_interval=None, start_date=days_ago(2), tags=['example'] ) # [START howto_operator_python] def print_context(ds, **kwargs): """Print the Airflow context and ds variable from the context.""" pprint(kwargs) print(ds) return 'Whatever you return gets printed in the logs' run_this = PythonOperator( task_id='print_the_context', python_callable=print_context, dag=dag, ) # [END howto_operator_python] # [START howto_operator_python_kwargs] def my_sleeping_function(random_base): """This is a function that will run within the DAG execution""" time.sleep(random_base) # Generate 5 sleeping tasks, sleeping from 0.0 to 0.4 seconds respectively for i in range(5): task = PythonOperator( task_id='sleep_for_' + str(i), python_callable=my_sleeping_function, op_kwargs={'random_base': float(i) / 10}, dag=dag, ) run_this >> task
DEMO
https://github.com/fanqingsong/machine_learning_workflow_on_airflow
from csv import reader from sklearn.cluster import KMeans import joblib from airflow import DAG from airflow.operators.python_operator import PythonOperator import airflow.utils from datetime import datetime, timedelta default_args = { 'owner': 'airflow', 'start_date': airflow.utils.dates.days_ago(1), 'email': ['qsfan@qq.com'], 'email_on_failure': True, 'email_on_retry': True, 'retries': 3, 'retry_delay': timedelta(seconds=5), 'provide_context': True, } dag = DAG( dag_id='kmeans_with_workflow1', default_args=default_args, # schedule_interval="@once", # schedule_interval="00, *, *, *, *" # support cron format # schedule_interval=timedelta(minutes=1) # every minute ) # Load a CSV file def load_csv(filename): file = open(filename, "rt") lines = reader(file) dataset = list(lines) return dataset # Convert string column to float def str_column_to_float(dataset, column): for row in dataset: row[column] = float(row[column].strip()) # Convert string column to integer def str_column_to_int(dataset, column): class_values = [row[column] for row in dataset] unique = set(class_values) lookup = dict() for i, value in enumerate(unique): lookup[value] = i for row in dataset: row[column] = lookup[row[column]] return lookup def getRawIrisData(**context): # Load iris dataset filename = '/root/airflow/iris.csv' dataset = load_csv(filename) print('Loaded data file {0} with {1} rows and {2} columns'.format(filename, len(dataset), len(dataset[0]))) print(dataset[0]) # convert string columns to float for i in range(4): str_column_to_float(dataset, i) # convert class column to int lookup = str_column_to_int(dataset, 4) print(dataset[0]) print(lookup) return dataset # task for data get_raw_iris_data = PythonOperator( task_id='get_raw_iris_data', python_callable=getRawIrisData, dag=dag, retries=2, provide_context=True, ) def getTrainData(**context): dataset = context['task_instance'].xcom_pull(task_ids='get_raw_iris_data') trainData = [[one[0], one[1], one[2], one[3]] for one in dataset] print("Found {n_cereals} trainData".format(n_cereals=len(trainData))) return trainData # task for getting training data get_train_iris_data = PythonOperator( task_id='get_train_iris_data', python_callable=getTrainData, dag=dag, retries=2, provide_context=True, ) def getNumClusters(**context): return 3 # task for getting cluster number get_cluster_number = PythonOperator( task_id='get_cluster_number', python_callable=getNumClusters, dag=dag, retries=2, provide_context=True, ) def train(**context): trainData = context['task_instance'].xcom_pull(task_ids='get_train_iris_data') numClusters = context['task_instance'].xcom_pull(task_ids='get_cluster_number') print("numClusters=%d" % numClusters) model = KMeans(n_clusters=numClusters) model.fit(trainData) # save model for prediction joblib.dump(model, 'model.kmeans') return trainData # task for training train_model = PythonOperator( task_id='train_model', python_callable=train, dag=dag, retries=2, provide_context=True, ) def predict(**context): irisData = context['task_instance'].xcom_pull(task_ids='train_model') # test saved prediction model = joblib.load('model.kmeans') # cluster result labels = model.predict(irisData) print("cluster result") print(labels) # task for predicting predict_model = PythonOperator( task_id='predict_model', python_callable=predict, dag=dag, retries=2, provide_context=True, ) def machine_learning_workflow_pipeline(): get_raw_iris_data >> get_train_iris_data train_model << [get_cluster_number, get_train_iris_data] train_model >> predict_model machine_learning_workflow_pipeline() if __name__ == "__main__": dag.cli()