任务:需要获取的内容:廖雪峰的官方网站中的python部分的标题和内容,之后获取整个python教程的内容,而不仅仅是这一个页面:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000

-
对html源码进行分析:
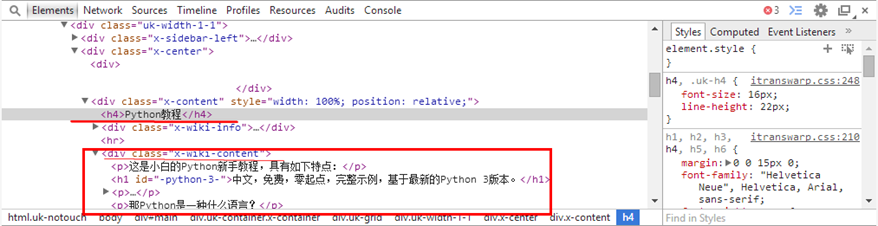
可以发现Python教程位于class="x-content"的Div下,且这样的div是独一无二的,所以可以通过这个线索获取文章的标题
文章的内容位于class="x-wiki-content"的Div下,同样可以通过这个线索获取文章的所有内容
-
获取文章的标题和内容:
获取网页的源码,需要使用ruquests模块
Import request
Htmlsource=requests.get('http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000')
-
获取标题:
- 通过正则表达式进行匹配:
title=re.findall('<h4>(.*?)</h4>',htmlsource.text,re.S)[0]
b)使用xpath获取内容:
匹配之前需要建立一个类似于树的东西:
Selector=etree.HTML(htmlsource.text)
selector.xpath('//div[@class="x-content"]/h4/text()')[0]
-
获取内容:
- 通过正则表达式进行匹配
content=re.findall('class="x-wiki-content">(.*?)</div>',htmlsource.text,re.S)[0]
这样获取的内容里面该div所有的内容,你可以通过re模块的sub方法将所有的标签换成空的字符,如:
re.sub('<(.+?)>','',content,count=0)
- 通过xpath获取内容
contentDiv= selector.xpath('//div[@class="x-wiki-content"]')
print contentDiv[0].xpath('string(.)')
- 通过第二步,可以实现对一个网页中的内容进行提取,那么接下来我们就要对该网页中左侧的链接进行提取,以便根据提取到的url获取python教程的所有内容
-
对网站左侧的html源码进行分析并获取urllist:

可以需要获取的内容所处的位置大致是ul-->li-->a,经过查询发现class="uk-nav uk-nav-side"ul有4,而我们需要获取的是第二个,所以Selector.xpath('//ul[@class="uk-nav uk-nav-side"]')[1]就是我们想要的ul
另外href显示的是相对路径,与真正的网络地址相比缺少了域名和http,因此获取这个href之后,需要我们进一步的处理
使用正则表达式是比较麻烦的,因此获取url可以使用更为简单的xpath
Urllist=[]
Linklist=Selector.xpath('//ul[@class="uk-nav uk-nav-side"]')[1]
for i in linklist:
urllist.append('http://www.liaoxuefeng.com' + i.xpath('a/@href')[0])
这样就获取到了想要的urllist了
-
根据这些url获取所有的title和content
第一种方法是遍历urllist:
根据url获取title和content,然后可以将其写入到一个文件中,速度非常慢,可能需要1分多钟
第二种方法是通过map()函数:
传入一个爬虫函数(参数是url),和一个url列表