1.前言
之前的章节已经将启动demo中能看见的内容都分析完了,Netty的一个整体样貌都在第8节线程模型最后给的图画出来了。这些内容解释了Netty为什么是一个异步事件驱动的程序,也解释了Netty的线程模型的高效,但是并没有涉及到的一个方面就是Handler的解析过程。通过前面的知识点我们都应该明白了Handler用于对获取的数据按照相关协议进行解析,Java的NIO都是通过buffer完成的读写的,这里关于Netty的另一个高效性却没有涉及,那就是内存管理,这个阶段发生在handler读取数据的阶段。
Netty使用了什么方式管理内存的?为什么需要内存管理?第一个问题是本节的主要内容,第二个问题在此给出答案。原因在于IO操作涉及到频繁的内存分配销毁,如果是在堆上分配内存空间,将会使得GC操作非常频繁,这对性能有极大的损耗,所以Netty使用了JDK1.5提供的堆外内存分配,程序可以直接操作不归JVM管辖的内存空间,但是需要自己控制内存的创建和销毁。通过堆外内存的方式,避免了频繁的GC,但是带来了另外一个问题堆外内存创建的效率十分的低,所以频繁创建堆外内存更加糟糕。基于上述原因,Netty最终设计了一个堆外内存池,申请了一大块内存空间,然后对这块内存空间提供管理接口,让应用层不需要关注内存操作,能够直接拿到相关数据。但是Netty并没有完全放弃在堆上开辟内存,提供了相应的接口。
要知道Netty是如何管理内存的,还需要搞明白几件事情。
final ByteBufAllocator allocator = config.getAllocator(); final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle(); byteBuf = allocHandle.allocate(allocator); allocHandle.lastBytesRead(doReadBytes(byteBuf));
这个是NioByteUnsafe的read方法中的一段代码,可以看出handler的一个read基本思路:获取ByteBufAllocator,再获取RecvByteBufAllocator.Handle,通过这两个类获取一个ByteBuf,最后将数据写入这个ByteBuf中。这个步骤就说明了一些读取数据的相关概念。再了解一下Nio的Allocator是DefaultChannelConfig的allocator字段,最终生成在ByteBufUtil的static方法中。其根据io.netty.allocator.type参数来决定使用哪种类型的,默认有UnpooledByteBufAllocator和PooledByteBufAllocator两种,即使用内存池或是不使用,Android平台默认unpooled,其它平台默认pooled。Nio默认的RecvByteBufAllocator则是AdaptiveRecvByteBufAllocator,这个设置在DefaultChannelConfig的构造方法里。了解了这些我们接下来分别看这三个类的体系结构。
2 ByteBufAllocator
该接口实例必须在线程安全的环境下使用。该接口定义的方法分为下面几种:
buffer():分配一个ByteBuf,是direct(直接内存缓存)还是heap(堆内存缓存)由具体实现决定。
ioBuffer():分配一个ByteBuf,最好是适合IO操作的direct内存缓存。
heapBuffer():分配一个堆内存缓存
directBuffer():分配一个direct直接内存缓存
compositeBuffer():分配一个composite缓存,是direct还是heap由具体实现决定
compositeHeapBuffer():分配一个composite的堆缓存
compositeDirectBuffer():分配一个composite的直接缓存
isDirectBufferPooled():是否是direct缓存池
calculateNewCapacity():计算ByteBuffer需要扩展时使用的容量
根据接口方法我们可以很清楚ByteBuf分为direct和heap两种类型,又因为分为pool和unpool,所以笛卡儿积就是4中类型了。composite类型的定义将在ByteBuf时讲解。
2.1 AbstractByteBufAllocator
抽象父类,定义了一些默认数据:1.默认缓存初始大小256,最大Integer.MAX_VALUE,components为16,threshold是1048576 * 4(4MB)。
抽象父类提供了包装ByteBuf类成可以检测内存泄漏的静态方法toLeakAwareBuffer。其还通过构造方法的参数preferDirect决定上面接口定义有歧义的方法是使用direct还是buffer,为true再满足平台条件就使用direct,否则就是heap。ioBuffer方法只需要满足平台支持,就会优先使用direct,和方法描述一致,平台不支持就会使用heap。compositeBuffer相关方法都是直接创建了CompositeByteBuf对象,通过toLeakAwareBuffer方法包装返回。calculateNewCapacity的逻辑是如果minNewCapacity等于threshold,就直接返回。大于就返回增加threshold的数值。小于从64开始*2,直到超过minNewCapacity。
最终抽象父类包装完了基本的方法,只剩下newHeapBuffer和newDirectBuffer方法交给子类来实现了。
2.2 PooledByteBufAllocator
该类构造参数preferDirect为false,所以其更倾向于使用heap内存,当然具体看是使用的哪个方法了。默认的pageSize是8192,maxOrder是11,chunkSize是8192<<11,tinyCacheSize是512,smallCacheSize是256,normalCacheSize是64,对这些参数有所疑惑是正常的,具体可以先看下Netty的内存管理文章:这里。简单看下就能明白这些参数的含义了。
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<byte[]> heapArena = cache.heapArena;
final ByteBuf buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
new UnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
final ByteBuf buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
上面是实现抽象父类未实现的内容。可以看到都是分为几步走:1.获取threadCache,线程本地缓存。2.获取对应的PoolArena,heap的是byte[]对象,direct的是ByteBuffer对象。3.存在就分配一个,不存在就创建一个。4.最后都通过toLeakAwareBuffer包装成内存泄漏检测的buffer。
threadCache就表面这个缓存是绑定了线程的,所以之前接口上就说明了必须保证使用时的线程安全。
2.3 UnpooledByteBufAllocator
未使用池技术的没有过多可讲解的内容,不是本章重点。
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
return PlatformDependent.hasUnsafe() ?
new InstrumentedUnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
final ByteBuf buf;
if (PlatformDependent.hasUnsafe()) {
buf = noCleaner ? new InstrumentedUnpooledUnsafeNoCleanerDirectByteBuf(this, initialCapacity, maxCapacity) :
new InstrumentedUnpooledUnsafeDirectByteBuf(this, initialCapacity, maxCapacity);
} else {
buf = new InstrumentedUnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return disableLeakDetector ? buf : toLeakAwareBuffer(buf);
}
都是直接返回的,不做特别的说明。
3 RecvByteBufAllocator
该接口就一个方法,生成一个Handler。
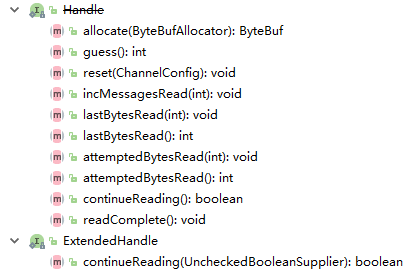
Handler已经被ExtendedHandler取代了,不过也是直接继承了Handler。allocate提供了分配方法,handler就是来管理如何分配。
allocate():分配一个ByteBuf,要足够大获取所有输入数据,也要足够小不要浪费太多空间。
guess():猜测allocate应该要分配多大的空间
reset():重置累积的计数,并建议在下一个读loop要读取多少字节或者消息。应该使用continueReading方法判断读操作是否结束
incMessagesRead():增加本次读loop的读取message的计数
lastBytesRead():设置最后一次读操作获取的字节
attemptedBytesRead():设置读操作需要尝试读取的字节数
continueReading():决定当前读loop是否继续
readComplete():读操作已完成。
3.1 AdaptiveRecvByteBufAllocator
该类也设置了一些默认参数,最小大小为64,最大为65536,初始化大小为1024,索引增长步长为4,减少为1。
static {
List<Integer> sizeTable = new ArrayList<Integer>();
for (int i = 16; i < 512; i += 16) {
sizeTable.add(i);
}
for (int i = 512; i > 0; i <<= 1) {
sizeTable.add(i);
}
SIZE_TABLE = new int[sizeTable.size()];
for (int i = 0; i < SIZE_TABLE.length; i ++) {
SIZE_TABLE[i] = sizeTable.get(i);
}
}
静态方法初始化了一个SIZE_TABLE字段,类型为int[]。可以从这段逻辑看出改字段存储了:16,32,48,64...496,512,1024,2048....2^31。这些元素。这些字段有什么含义呢?具体看使用了这个表的方法:
private static int getSizeTableIndex(final int size) {
for (int low = 0, high = SIZE_TABLE.length - 1;;) {
if (high < low) {
return low;
}
if (high == low) {
return high;
}
int mid = low + high >>> 1;
int a = SIZE_TABLE[mid];
int b = SIZE_TABLE[mid + 1];
if (size > b) {
low = mid + 1;
} else if (size < a) {
high = mid - 1;
} else if (size == a) {
return mid;
} else {
return mid + 1;
}
}
}
这个方法名就说明了其作用是获取表的下标索引,这大体上是个二分查找的思路。给了一个初始大小,如果该值比中间值右边还大,继续,low重新设置;比中间值小,也继续,high重新设置。如果等于中间值返回下标,如果介于中间值和中间值大一个的位置,返回中间值大一个的内容。
这么理解不好理解,再看上面的接口定义的allocate的方法,目标是不要浪费太多空间,也要满足能够读取所有的内容。有了这么个前提这个操作就好理解了,这是开发人员根据实际设计的一组空间分配的大小设置,根据size,来获取一个合适的分配大小。这个方法就是获取合适大小的表大小数组的下标。所以介于中间值和大于中间值的位置,就返回了大于中间值的位置,保证这两个内容,足够,浪费最小。至于为什么前面都是16累计,到了512就变成了*2累计,这个估计和实际情况相关而设计的。
3.2 HandleImpl
这个就是AdaptiveRecvByteBufAllocator提供的一个Handler了,回到最初给的代码,通过recvallocator的handler,处理allocator,最终获取读取的buffer。ExtendedHandle定义的11个方法,这里只实现了4个,其它的由父类MaxMessageHandle实现了。先看MaxMessageHandler类的相关内容。
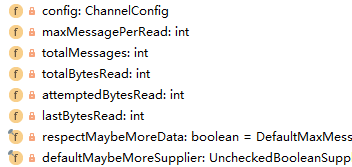
maxMessagePerRead:一次读取最多的数据量
totalMessages:总共的消息量
totalBytesRead:总共的字节量(前面也提到过,分为message和byte)
attemptedBytesRead:尝试读取的字节数
lastBytesRead:最后读取的字节数
大部分方法都是直接返回相关的字段,其它内容不值一提,需要结合实际使用进行分析。allocate方法,实际上调用了alloc的ioBuffer方法,即尽可能的使用direct模式。
HandleImpl实际也没有太多内容,最难理解的就是上面说的获取大小适宜的缓冲区的计算需要大小的步骤了。
小结一下:RecvByteBufAllocator的目的就一个,为了开辟合适大小的缓冲区。
4. ByteBuf
此概念是最重要又不重要的一个环节。ByteBuf抽象类实现了ReferenceCounted,这个是Netty设计的direct内存一个重点。上面谈到过heap模式存在频繁的GC,direct模式如果频繁开辟缓存和销毁,性能更低,所以采取了Pool的方式管理direct。而实际上使用池的技术也需要标记已使用的,和未使用的区域,使用完成之后也需要进行释放。Netty采取了一种GC策略,引用计数法。有一个类引用了该Buffer,+1,release的时候-1。为0的时候就都不使用了,这个时候该区域就可以进行释放。这个就是ReferenceCounted所做的事情,引用计数。

refCnt:当前计数,为0意味着收回
retain:引用+1,或者+指定数值
touch:调试使用,记录当前访问该对象的位置。ResourceLeakDetector可以提供相关信息。
release:引用-1,或者-指定数值
抽象父类ByteBuf的方法很多,这里不进行截图,简单介绍说明(太多了,多数看名称就能明白相关意思):
capacity():当前容量;传入数值,小于当前容量截断,大于扩容到这个值
maxCapacity():允许的最大容量
alloc():获取开辟这个缓存的alloc对象
order():设置解析字节码的字节顺序,换另一种说法可能更清楚(Big-endian和Little-endian),具体见wiki:这里。该方法被废弃,后面直接使用getShort和getShortLE进行区分。
unwarp():如果该类是包装类,返回未包装前的对象。
isDirect():是否是直接内存
isReadOnly():是否只读
asReadOnly():返回一个只读的ByteBuf版本
readerIndex():返回读取下标,带参数就是设置这个值
writerIndex():返回写下标,带参数就是设置
其它的一些方法有:判断可读可写状态,和相关字节数。清除内容,标记读位置,重置读位置,标记写和重置写。丢弃一些读取字节。然后就是基本的读取int,short等基本类型的方法,这里之前也说过多了一个LE方法。跳过一些字节。拷贝缓存,返回可读的字节片段,复制字节,内存地址等一系列方法。
ByteBuf的相关方法定义实际上和JAVA提供的ByteBuffer区别不是很大,保持了一致性。下面我们只介绍两种ByteBuf。
4.1 PooledUnsafeDirectByteBuf
这种buf可能就是我们想要研究的了,从最上层的抽象父类一层层往下看其相关操作。
1.AbstractByteBuf:
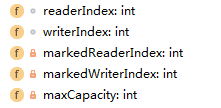
该抽象类解决了基本的方法:可读可写的相关判断。清除,标记读写位置,丢弃字节。其他的方法大体都交给子类实现了,父类只是确定了一下安全性,比如getInt是不是有2个可读字节之类的。
2.AbstractReferenceCountedByteBuf:
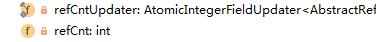
该抽象父类最大的作用就是完成了之前引用计数的问题,通过CAS操作更新。相关方法的实现。
3.PooledByteBuf:这个方法就是相关内存池的操作。
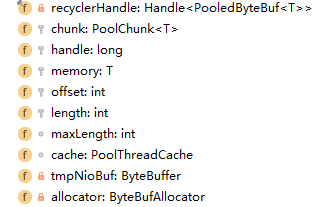
这个类就实现了一些基本的capacity、slice、duplicate、deallocate的相关方法,基本上是通过上图的参数实现的。
最后就是我们要说的PooledUnsafeDirectByteBuf类了,该类都是通过UnsafeByteBufUtil类来实现相关方法。实际上看过去这些方法都不复杂,因为复杂的部分被简单略过了,比如分配缓存的时候具体是如何操作的,那个是在Pool方法中,使用缓存的方法倒是不复杂,但是有两个内容也忽略了,一个是leakDetector另一个就是recycler了。这些都不进行介绍。
4.2 CompositeByteBuf
这个类是之前没有介绍清楚的,组合型ByteBuf,到底是什么含义呢?其实该类与Netty中的零拷贝有关。这个零拷贝和最初节所说的操作系统层次的零拷贝不是一个概念,Netty的零拷贝指的是用户态之间的内存拷贝。即减少从用户地址的一个位置拷贝到另一个地址的次数。比如说文件FileRegion,可以通过transferTo方法将文件缓冲直接交给Channel,而不用通过while循环获取数据,再传递。又比如一个消息由多个模块组成,比如请求头,请求体。通常要合并成一个Buffer,这个就产生了在用户态中进行拷贝数据了。这个解决方法也就是现在所说的CompositeByteBuf,组合ByteBuf。将组件添加到这个buffer中,再对操作层透明的传输这些数据。
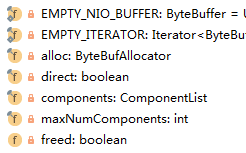
components是一个ArrayList,元素就是ByteBuf,maxNumComponents就是最大的组件个数,默认16个。
private int addComponent0(boolean increaseWriterIndex, int cIndex, ByteBuf buffer) {
assert buffer != null;
boolean wasAdded = false;
try {
checkComponentIndex(cIndex);
int readableBytes = buffer.readableBytes();
// No need to consolidate - just add a component to the list.
@SuppressWarnings("deprecation")
Component c = new Component(buffer.order(ByteOrder.BIG_ENDIAN).slice());
if (cIndex == components.size()) {
wasAdded = components.add(c);
if (cIndex == 0) {
c.endOffset = readableBytes;
} else {
Component prev = components.get(cIndex - 1);
c.offset = prev.endOffset;
c.endOffset = c.offset + readableBytes;
}
} else {
components.add(cIndex, c);
wasAdded = true;
if (readableBytes != 0) {
updateComponentOffsets(cIndex);
}
}
if (increaseWriterIndex) {
writerIndex(writerIndex() + buffer.readableBytes());
}
return cIndex;
} finally {
if (!wasAdded) {
buffer.release();
}
}
}
private Component findComponent(int offset) {
checkIndex(offset);
for (int low = 0, high = components.size(); low <= high;) {
int mid = low + high >>> 1;
Component c = components.get(mid);
if (offset >= c.endOffset) {
low = mid + 1;
} else if (offset < c.offset) {
high = mid - 1;
} else {
assert c.length != 0;
return c;
}
}
throw new Error("should not reach here");
}
可以看见添加组件,和定位哪个组件的方法,这样就简单的实现了将多个ByteBuf合并,对外提供透明接口,不用具体开辟新的空间,再拷贝相关数据了。
5 后记
本节题目虽然叫做内存管理,但是核心内容较少,涉及算法,比较繁琐。但大体介绍了一下Netty的内存设计思路,将了与之相关的类的实现。归纳如下:
1.Netty大致有4中内存方法,Heap Pool,Direct Pool, Heap unPool,Dircet unPool。
2.Pool和UnPool的大体区别
3.ByteBuf采取了引用计数的方式管理这块被分配了的内存
4.Netty零拷贝实现之一CompositeByteBuf,将多个ByteBuf组合起来,提供操作一个的接口。
最重要的Pool方式的实现没有说明,而且内存泄露检测,recycle等内容也没有说明。这些都需要自己去琢磨。再附上文中提到的一个其它博客对这块算法的介绍:这里,作为这章内容的缺失补充。再补充一下Netty零拷贝的相关知识:这里。
最后再给出一个别人使用Netty进行优化的例子:这里,结合前面的知识,这个应该能够看懂。另外,此系列基本就到此为止了,其它的应该不会再进行详细介绍,后面可能会补充一些具体使用的demo。