转载请注明源出处:http://www.cnblogs.com/lighten/p/7505355.html
1.前言
本章介绍无界的阻塞队列LinkedTransferQueue,JDK7才提供了这个类,所以这个类具备了一些一般队列不具有的特性。此队列也是基于链表的,对于所有给定的生产者都是先入先出的。注意,该队列的size方法和ConcurrentLinkedQueue一样不是常量时间。由于队列的实现,其需要遍历队列才能计算出队列的大小,这期间队列发生的改变,遍历的结果会不正确。bulk操作并不保证原子性,比如迭代器迭代的时候执行addAll()方法,迭代器可能只能看到部分新加的元素。
2.LinkedTransferQueue
2.1 TransferQueue接口
这个是JDK7才定义的一个节点,LinkedTransferQueue实现了这个接口,其新特性也就与之有关。通常阻塞队里中,生产者放入元素,消费者使用元素,这两个部分是分离的。这里的分离意思如下:厨师做好了菜放在柜台上,服务员端走,厨师是不需要管有没有人取走做的菜,服务员也不需要管厨师有没有做好菜,没做好菜阻塞就行了。上面就是个人所说的分离的意思。TransferQueue接口定义的相关内容就是厨师会知道做好的菜有没有被取走。

1.tryTransfer(E):将元素立刻给消费者。准确的说就是立刻给一个等待接收元素的线程,如果没有消费者就会返回false,而不将元素放入队列。
2.transfer(E):将元素给消费者,如果没有消费者就会等待。
3.tryTransfer(E,long,TimeUnit):将元素立刻给消费者,如果没有就等待指定时间。给失败返回false。
4.hasWaitingConsumer():返回当前是否有消费者在等待元素。
5.getWaitingConsumerCount():返回等待元素的消费者个数。
2.2 设计原理
Dual Queues是该队列的基础理论。此队列不进存放数据节点,也会存放请求节点。当一个线程试图放入一个数据节点,正好遇到一个请求数据的结点,会立刻匹配并移除该数据节点,对于请求节点入队列也是一样的。Blocking Dual Queues阻塞所有未匹配的线程,直到有匹配的线程出现。
一个先入先出的dual queue实现是无锁队列算法M&S的变体。其包含两个指向字段:head指向一个匹配的结点,然后依次指向未匹配的结点,如果不为空。tail指向最后一个节点,或者null,如果队列为空。例如下图是一个包含四个元素的队列结构:
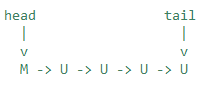
M&S算法易于扩展和保持(通过CAS)这些头部和尾指针。在dual队列中,节点需要自动维护匹配状态。所以这里需要一些必要的变量:对于数据模式,匹配需要将一个item字段通过CAS从非null的数据转成null,反之对于请求模式,需要从null变成data。一旦一个节点匹配了,其状态将不再改变。因此通常安排元素链表的前缀是0个或多个匹配节点,而后跟随0个或多个未匹配节点。如果不关心时间或空间的效率,通过从头指针开始遍历队列放入取出操作都是对的。CAS操作第一个未匹配节点匹配时的item,在下一个字段追加后一个节点。然而这是一个糟糕的想法,虽然其确实有好处,不需对head或tail进行原子更新。
LinkedTransferQueue采取了一种折中的方案,介于实时更新head/tail和不更新head/tail之间的方法。该方法对有时候需要额外的遍历去定位第一个或最后一个未匹配的结点和减少开销及队列结点的竞争更新这两个方面进行了权衡。例如,一个可能出现的队列快照如下图:

slack(head位置和第一个未匹配的结点的最大距离,尾结点类似)的最佳值是一个经验问题,发现在1~3之间在大部分平台是最佳的值。更大的值会增加内存命中开销和长遍历链表的风险,更小的值则会增加CAS的竞争开销。
具体实现:使用一个基础的threshold来更新,slack为2。所以在当前位置超过第一个或最后一个节点2个距离以上的时候就会更新head/tail。出入队列操作都是通过xfer方法完成的,只需要不同的参数来表示操作。
其它的内容通过代码详细介绍。
2.3 数据结构

上图是一个基本的数据结构:
MP表示是否是多核处理器;
FRONT_SPINS当一个节点目前是队列的第一个等待者,在多核处理器上自旋的次数2n。
CHAINED_SPINS当一个节点先于另一个明显自旋的结点阻塞时自旋的次数。

上图是Node节点的基本结构,next就是下一个节点了,isData表示是请求还是数据节点,另外两个字段就是对应不同模式要存储的值了。Node的基本操作如下:
casNext:CAS更新当前结点next的字段
casItem:CAS更新当前结点的item字段
forgetNext:CAS设置当前结点的next字段为自身
forgetContents:CAS设置item字段为自身,waiter为null
isMatched:是否是匹配了的结点
isUnmatchedRequest:是否是未匹配的请求节点
cannotPrecede:当该节点是未匹配节点却与当前的结点类型不符的时候,返回true。意思就是当前都是请求节点,数据节点应该立刻被消耗,未匹配的结点应该是同一种节点。
tryMatchData:数据节点尝试匹配
2.4 基本操作
存入一个元素:该队列的put、offer和offer(E,timeout,unit)方法所调用的都是同一个方法。


不允许放入的数据为空,放入操作的模式是ASYNC。从头指针处开始死循环,当前结点p没有被匹配,数据节点不能匹配直接跳出循环,不进行匹配,后面会进入how!=NOW的判断,创建新节点,尝试追加到队列尾。如果可以匹配就替换P节点的值,失败意味着被其它线程抢先了,继续循环,成功了意味着这两个匹配成功,可能需要更新头结点。q=p且p!=h的循环意味着已经跳过了一个元素,n又取了q.next,p又是当前被匹配了的结点,这就意味着前面有2个match的结点:head和p。达到slack为2的条件,更新头结点,并遗弃之前的head。不需要更新头结点的时候直接跳出循环。匹配完成之后就是唤醒p结点的waiter(如果p是请求节点的话)返回item。

队列尾追加节点操作如上图,从尾结点开始,
如果当前结点p为null,头结点也是null,初始化队列,设置头结点,返回s追加节点。
如果该节点不能放入队列,返回null。
如果p.next不为空,意味着当前结点不是尾结点,重新找到尾结点,继续循环。
如果p节点在设置的时候被插队了,继续找其下一个循环
如果成功了,p!=t,且tail也不等于t。意味着有尾结点后面又追加了2个节点,slack>=2更新尾结点。返回p节点。

取出都是消费者data为null,poll的模式是NOW,有时间限制就是TIMED,take方法使用的是SYNC。回到xfer方法,我们可以知道:其先找到第一个未匹配的元素进行匹配,匹配了不管什么模式都是直接返回,没匹配就要根据模式来了,先是how!=NOW才会有额外操作,所以poll取出就是NOW,取不到那就是没准备好,直接返回就可以了。其它三种模式没匹配到都会尝试追加该节点,没追加上肯定是模式不匹配,意味着可以匹配的,重新循环。如果不是ASYNC模式,那就是带有时间或异步的模式,需要等待。
以上就是整个类的设计思路了,分成四种模式:NOW就是立刻返回不追加元素到末尾,ASYNC就是同步需要添加元素到队列尾,TIMED用于有时间限制的操作,SYNC用于无时间限制无限等待的操作。awaitMatch方法不再进行介绍,就是等到指定时间。size方法和getWaitingConsumerCount方法都是遍历链表,超过Integer.MAX_VALUE就返回这个值,区别就是该链表是处于什么模式而已。其它的方法不再描述,上面是基本的操作。
3.使用例子
@Test
public void testTransfer() {
LinkedTransferQueue<Integer> queue = new LinkedTransferQueue<>();
new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(500); // 再改成1500
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
System.out.println(Thread.currentThread().getName()+"-"+queue.take());
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
},"consumer").start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"-"+queue.tryTransfer(1));
try {
System.out.println(Thread.currentThread().getName()+"-等待2被消耗:"+queue.tryTransfer(2, 1, TimeUnit.SECONDS));
queue.transfer(3);
System.out.println(Thread.currentThread().getName()+"-"+"等到3被消费:true");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
},"prodcuer").start();
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}

更改1500毫秒之后:
