转载请注明源出处:http://www.cnblogs.com/lighten/p/6946683.html
1.简介
JDK1.6之后,java.util包下多了一个类ServiceLoader,其实现了Iterable接口(可以直接进行for-each loop)。这个类的主要作用是提供了一种服务发现机制,并没有什么深奥的内容。实现过程也十分简单,下面通过一个例子来详细讲解一下如何使用和其实现过程。本文基于jdk1.8。
2.例子
ServiceLoader的使用是要在根目录有一个文件夹META-INF/services/,其主要是对这个目录进行扫描,文件名是你需要提供服务的类(接口)全称(即包名.类名)。类中的内容,一行就是改接口的一个具体的实现类。包结构如下:
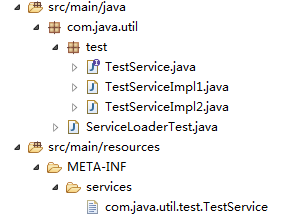
服务的定义和实现具体如下:
public interface TestService {
public String sayHello();
}
public class TestServiceImpl1 implements TestService {
@Override
public String sayHello() {
return "hello, test1";
}
}
public class TestServiceImpl2 implements TestService {
@Override
public String sayHello() {
return "hello, test2";
}
}
配置文件就是实现类的类全称:
com.java.util.test.TestServiceImpl1 com.java.util.test.TestServiceImpl2
配置完成后就是最主要的使用方法了:
public class ServiceLoaderTest {
public static void main(String[] args) {
ServiceLoader<TestService> loader = ServiceLoader.load(TestService.class);
for(TestService service : loader) {
System.out.println(service.sayHello());
}
}
}
运行一下结果如下:
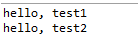
使用起来也很简单,就是通过静态方法load进行加载,然后通过for-each循环遍历,使用这个实现类。
3.源码解读
ServiceLoader解析服务并不是加载就立刻解析的,其采取的是懒加载的方式,也就是第一次使用这个loader对象的时候才进行解析。
1.先看属性:
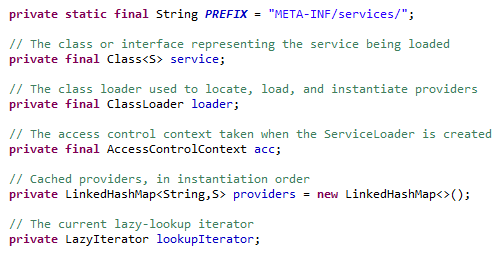
这里就定义了读取的文件名,service是需要加载的类,loader是类加载器,默认使用当前加载器,providers是服务提供者,lookupIterator就是懒加载的具体实现了。
2.再看loader方法:
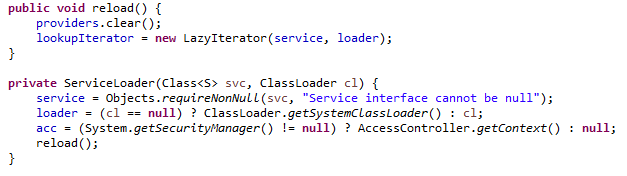
loader方法就是初始化了一些属性,清空了providers。
3.关键的iterator()方法,这个是Iterable接口需要实现的一个方法:

其遍历,是先通过providers来遍历,因为解析完成后这里应该是有值的,如果没值,就通过lookupIterator去遍历,这里也就看出并不是loader就开始读取然后解析,而是在遍历的时候,没找到解析的值,再通过设置的懒加载遍历器,去解析遍历。
4.核心的LazyIterator,其实现了Iterator接口,next和hasNext实际上调用的是其另两个方法,nextService与hasNextService

上面代码很简单,就是读取META-INF/services文件夹下,所加载类的类全称名的文件,通过parse方法解析。
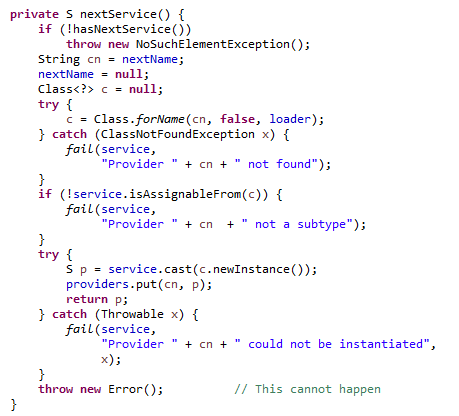
nextService方法也很简单,就是通过实现类的类全称,通过Class.forName进行加载。然后判断该实现类是不是加载类的子类,service.isAssignableFrom,再通过service.cast()方法进行转换成所加载的类。
5.parse解析文件步骤:
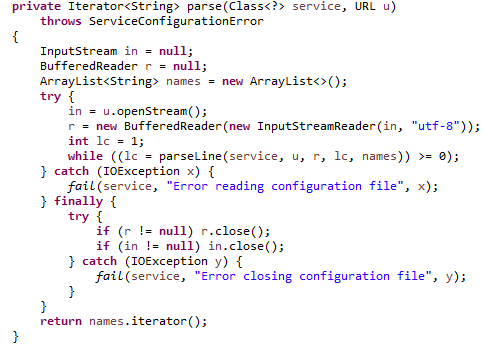
用utf-8的格式读取,然后调用parseLine方法,一行行读取到name这个迭代器中。
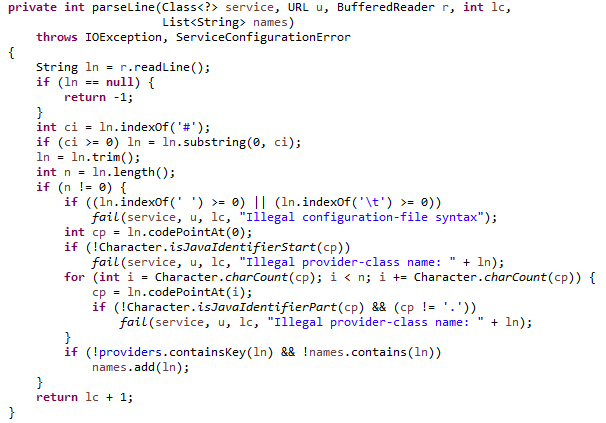
读取一行,截取#注释前面的内容,通过trim方法去掉两端空格。若还有值,则判断是否有空格或制表符,有即不符合规则,查看是不是Java标识的开头。都满足规则,如果providers中没有且未解析过相同的,就放入迭代器中。
至此,这个解析过程就明了了,就是读取指定文件夹的指定文件,文件中存的类全称,通过Class.forName,拿到字节码,再通过class.newInstance方法获得实例,将其cast成所要加载的类。