1.前言
对于做实时计算的朋友来说,资源设置都是一个比较麻烦的问题。实时计算不同于离线计算,它的任务都是并行的,启动就会一直占用集群资源,如果资源设置的过多会造成极大的浪费,设置的过少任务会不断发生failover。这里说的资源主要指的就是内存资源,所以本文对Flink的内存设置提供一些思路,尤其是对于容器环境,内存的设置极为重要,否则会被频繁的kill。
本文将分别介绍1.9版本之前和之后的两类设置方法,这是由于这个版本之后Flink的内存模型发生了极大的变化。
本文是基于个人的一个使用经验,部分代码,和其他文章而成,里面可能存在错误,望指正。
2.Flink <= 1.9
2.1 例子
这里用Flink1.8为例,计算内存的代码位于 org.apache.flink.runtime.clusterframework.ContaineredTaskManagerParameters类的create方法。
按照计算步骤,以taskmanager.heap.size=6g为例子,其他参数保持不动,最终得到的参数如下:
-Xms4148m -Xmx4148m -XX:MaxDirectMemorySize=1996m
两块内存加起来是6144m = 6g jvm的设置符合参数。
Flink Dashboard上面显示的是:
JVM Heap Size:3.95 GB Flink Managed Memory:2.74 GB
JVM (Heap/Non-Heap) Commit: Heap:3.95 GB Non-Heap:141 MB Total:4.09 GB
Outside JVM:Capacity:457 MB
NetWork: count: xxxxx
2.2 计算过程
设容器内存总大小是x
详细看create方法:
1. cutoff:容器超过3g, 简单可以记成 0.25x
flink为了防止内存溢出,计算的时候先切了一块内存下来不参与后续计算,这块就是cutoff
计算公式:
cutoff = Math.max(containerized.heap-cutoff-min, taskmanager.heap.size * containerized.heap-cutoff-ratio)
默认值是600和0.25,所以6g的时候=Math.max(600, 6144*0.25) = 1536m
剩余大小 0.75x6g = 4608m
2. networkBufMB:简单记成 0.75*0.1x,最大1g
网络buffer使用内存分成新旧版,这里只关注新版,涉及参数:
taskmanager.memory.segment-size:32kb
taskmanager.network.memory.fraction:0.1
taskmanager.network.memory.min:64mb
taskmanager.network.memory.max:1g
计算公式:
Math.min(taskmanager.network.memory.max,Math.max(taskmanager.network.memory.min, taskmanager.network.memory.fraction * (x - cutoff))
这里的结果就是:Math.min(1g, Math.max(64mb, 0.1 * 4608m) = 460.8m
3. heapSizeMB:0.75 * 0.9x
taskmanager.memory.off-heap默认为false,主要指的是Flink Managed Memory使用Heap还是Non-heap,默认使用Heap,如果开启使用Non-heap将再减少一部分资源。
计算公式:x - cutoff - networkBufMB
这里就是:4147.2 (注意:这个就是-xmx 4148m)
4. offHeapSizeMB: x - heapSizeMB
就是1996m (注意:这个就是XX:MaxDirectMemorySize: 1996m)
后续:上面只是一个jvm的参数预估设置,实际设置还与运行中环境有关,TaskManagerServices.fromConfiguration
会计算一个 freeHeapMemoryWithDefrag,计算之前会手动触发gc,然后用Jvm最大内存 - 总内存 + 空闲内存。
这个值可以认为是一个空运行的flink任务剩余的堆内存了。
后面将计算Flink管理的内存,这个指的是Flink Managed Memory Segment: taskmanager.memory.fraction默认是0.7,
被Flink管理的内存就是:freeHeapMemoryWithDefrag * 0.7
2.3 内存划分
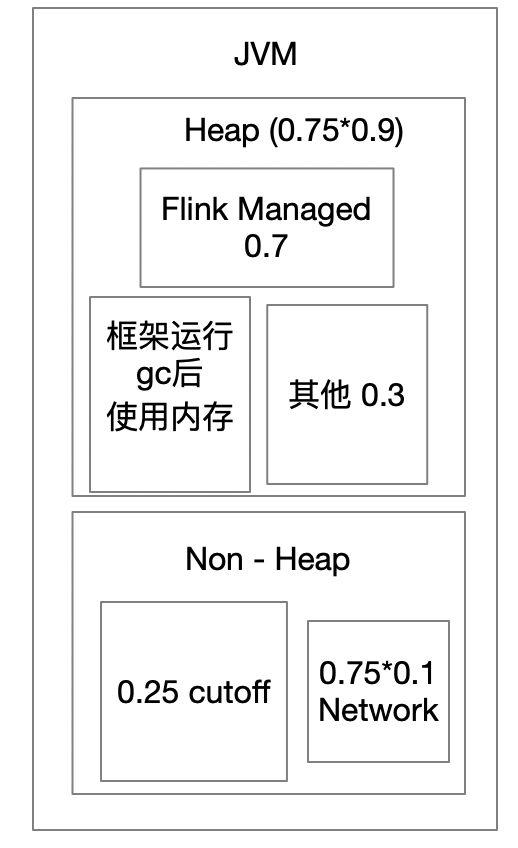
所以虽然6g内存计算出来后,heap是4148,但是在dashbord中显示不足4148, 为3.95G=4044.8, Flink managed内存小于 0.75*0.9*0.7 = 2903.04 , dashboard上显示2.74g = 2805.76m
框架运行需要:4148 - 4044.8 = 103.2m,3.95 * 0.7 = 2.765 > 2.74。没有相等,其他的内存使用暂时没有探究了。
Flink Managed内存一般用于批处理作业,流处理作业可以调整 taskmanager.memory.fraction,使得这部分内存用于用户代码。
Non - heap空间一般用于 JVM 的栈空间、方法区等堆外开销外,还包括网络 buffer、batch 缓存、RocksDB
3. Flink >= 1.10
Flink 1.10对整个内存做了个大改版,需要参考官方文档进行升级:https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/ops/memory/mem_migration.html
3.1 例子
这里设置单个taskmanager为14g,taskmanager.memory.managed.fraction为0.5,将会得到以下内容:
-Xmx5721030656 = 5456MB = 5.328g
-=1207959552 = 1152MB = 1.125g
-XX:MaxMetaspaceSize=100663296 = 96MB
可以发现,上面的加起来等于6704MB,远远不足14g,和1.8版本有很大的不同。
再看dashboard:
JVM Heap Size:5.19 GB Flink Managed Memory:6.45 GB
JVM (Heap/Non-Heap) : Heap:5.19 GB Non-Heap:1.33 GB Total:6.52 GB
Outside JVM:Capacity:1.01GB
NetWork: count: xxxxx
可以计算得到6.45+6.52+1.01 = 13.98 等于14
3.2 计算过程
taskmanager.memory.process.size 设置的是容器的内存大小,等于之前的 taskmanager.heap.size
计算过程在org.apache.flink.runtime.clusterframework.TaskExecutorProcessUtils中processSpecFromConfig方法,TaskExecutorProcessSpec类展示了1.10版本整个内存的组成。
计算方法分成3种:
1.指定了taskmanager.memory.task.heap.size和taskmanager.memory.managed.size 见方法:deriveProcessSpecWithExplicitTaskAndManagedMemory
2.指定了taskmanager.memory.flink.size 见方法:deriveProcessSpecWithTotalFlinkMemory
3.指定了taskmanager.memory.process.size(容器环境一般指定这个,决定全局容量)
totalProcessMemorySize = 设置的值 14g, jvmMetaspaceSize = taskmanager.memory.jvm-metaspace.size,默认96m, 这个对应参数-XX:MaxMetaspaceSize=100663296。
jvmOverheadSize:
taskmanager.memory.jvm-overhead.min 192m
taskmanager.memory.jvm-overhead.max 1g
taskmanager.memory.jvm-overhead.fraction 0.1
公式 14g * 0.1 = 1.4g 必须在[192m, 1g]之间,所以jvmOverheadSize的大小是1g
totalFlinkMemorySize = 14g - 1g - 96m = 13216m
frameworkHeapMemorySize:taskmanager.memory.framework.heap.size 默认128m
frameworkOffHeapMemorySize:taskmanager.memory.framework.off-heap.size 默认128m
taskOffHeapMemorySize:taskmanager.memory.task.off-heap.size 默认0
确定好上面这些参数后,就是最重要的三个指标的计算了:taskHeapMemorySize,networkMemorySize,managedMemorySize
计算分成确定了:taskmanager.memory.task.heap.size还是没确定。
1)确定了taskmanager.memory.task.heap.size
taskHeapMemorySize = 设置值
managedMemorySize = 设置了使用设置值,否则使用 0.4 * totalFlinkMemorySize
如果 taskHeapMemorySize + taskOffHeapMemorySize + frameworkHeapMemorySize + frameworkOffHeapMemorySize + managedMemorySize > totalFlinkMemorySize异常
networkMemorySize 等于剩余的大小,之后还会check这块内存是否充足,可以自己查看对应代码
2)未设置heap大小
先确定 managedMemorySize = 设置了使用设置值,否则使用 0.4 * totalFlinkMemorySize,这里就是 0.5 * 13216m = 6608 = 6.45g (这里就是dashboard的显示内容)
再确定network buffer大小,这个也是有两种情况,不细说。 [64mb, 1g] 0.1 * totalFlinkMemorySize = 1321.6, 所以是1g
最后剩余的就是taskHeapMemorySize,不能为负数,这里等于 13216 - 6608 - 1024 - 128 - 128 = 5328 = 5.2g (这里约等于dashboard的显示heap大小)
最后jvm的参数的计算过程:
jvmHeapSize = frameworkHeapSize + taskHeapSize = 5328 + 128 = 5456
jvmDirectSize = frameworkOffHeapMemorySize + taskOffHeapSize + networkMemSize = 128 + 1024 = 1152
jvmMetaspaceSize = 96m
3.3 内存划分
https://ci.apache.org/projects/flink/flink-docs-release-1.10/ops/memory/mem_detail.html

从计算过程,结合上图可以看出Flink 1.10中的一个内存划分了。
总内存 = Flink 内存 + JVM Metaspace (96m)+ JVM Overhead (计算为0.1 * 全局大小,结果必须在[192m, 1g]之间)
Flink内存被划分成6部分:框架运行需要的Heap和Non Heap,默认都是128m
任务需要的Heap和Non Heap(默认0), Heap是通过计算其他5部分内存,Flink内存剩余得到
网络缓冲 (0.1 * Flink内存,结果必须在[64mb, 1g]之间)
Flink管理内存:0.4 * Flink内存

4. 总结
Flink 1.10之前对内存的划分比较简单,主要就是Heap + Non-Heap,之后对内存做了更细致的切分。
Flink 1.8可以调整taskmanager.memory.fraction 减少Heap中的管理的内存,增大用户代码的内存使用,调整containerized.heap-cutoff-ratio,控制Non-heap空间,这个影响rocksdb。
Flink 1.10可以调整taskmanager.memory.managed.fraction 控制managed内存,这个影响rocksdb,也会影响taskHeap大小,需要衡量。
也可以看到Flink内存模型的变化managed内存位置也发生了变化,作用也有了些许变化。
JVM 主要划分 Heap 和 Non-Heap,Non-Heap又划分为Direct和Native等。
1.8的Non-Heap都是通过XX:MaxDirectMemorySize设置的
1.10的Network buffer在Direct里面,另一部分是Native(包括Managed Memory),主要用于rocksdb,如果使用的是Heap状态后台,可以设置小点,也用于Batch。