堆
堆就是一种利用完全二叉树来维护数据的一种数据结构,而当我们实际使用时使用数组来存储时,树中节点与数组中的值相对应,也就是可以灵活运用完全二叉树的性质通过数组下标来维护堆。
想看Stl模板的堆请直达底部
为什么要选择堆?
堆的功能就是保持堆顶的元素最大/最小,本质上是一种排序算法,为什么不用Sort呢?它构建时间一般是复杂度是(O(n)),而维护的时间复杂度是(O(log_2N)),如果你用Sort进行排序,时间复杂度是(O(Nlog_2N)),两者对比,明显堆的时间复杂度优于Sort。
但是特殊情况特殊考虑,针对不同题目仍需要使用不同的做法
前置技能点:完全二叉树
何为完全二叉树?
如果一棵深度为K二叉树,1至k-1层的结点都是满的,即满足2i-1,只有最下面的一层的结点数小于2i-1,并且最下面一层的结点都集中在该层最左边的若干位置,则此二叉树称为完全二叉树。
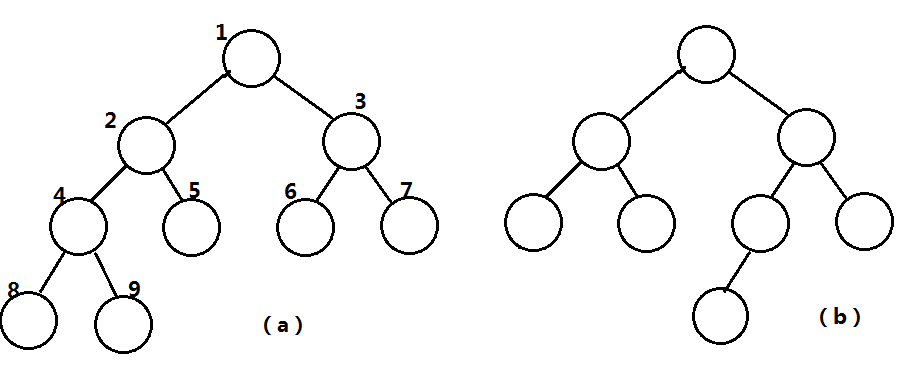
简单来说就是假设一颗树的深度为h,除了最后一层每个节点都有两个子节点,最后一层的结点必须从左向右连续出现。
什么是从从左向右连续出现?如图,a就是完全二叉树,而b不是完全二叉树
此外,如果将完全二叉树按照从上至下,从左至右的次序对节点进行编号,则编号为i的节点有以下性质。
-
若 (ileqlfloor n/2 floor)[1],即 (2ileq n) ,则编号为i的节点为分支节点[2],否则为叶子节点[3]。
-
若n为奇数,则树中每个分支节点即有左子节点,又有右子节点;
若n为偶数,则编号最大的分支节点(编号为n/2)只有左子节点,没有右子节点
-
若编号为i的节点有左子节点,则左子节点的编号为 (2i) ;若编号为i的节点有右子节点,则右子节点编号为 (2i+1) 。
-
除树根节点外,若一个节点的编号为 (i) ,则他的父节点编号为 (lfloor i/2 floor)
以上两条性质不理解的可以看一下上面的a图
堆的定义
因为堆是对完全二叉树的一种灵活运用,所以堆的定义很大程度上就是完全二叉树的定义的线性化,只不过堆还需要维护序列数字之间的大小关系
堆的定义:设有n个元素的一个序列,(A_1,A_2,A_3ldots),只有当序列中的数字满足以下其中一种关系时,称为堆。
(A_ileq{{A_{2i} atop A_{2i+1}}) 或 (A_igeq{{A_{2i} atop A_{2i+1}})
前面的这个就叫小根堆,后面这个就叫大根堆
堆中序列的数值关系
由完全二叉树的第三和第四条性质我们可以知道,双亲和左右子节点的编号就是 (i) ,(2i) 与 (2i+1) 的关系,所以判断一个序列是不是堆,可以通过该节点与其左右节点的大小分析。
堆的特性:堆顶元素最大或者最小
将大根堆转化为数组储存后,值的对应就如下图
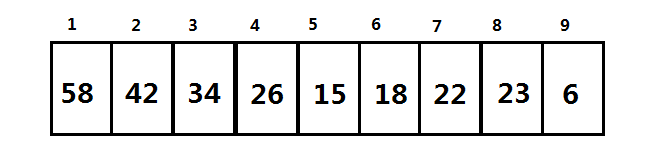
很明显,在上图中,数组的第一个元素是全堆元素中的最大值
那么如何进行堆的维护呢?
堆的运行与维护
堆只有两个操作:插入和取出
1.假设维护一个大根堆,进行一个插入操作
-
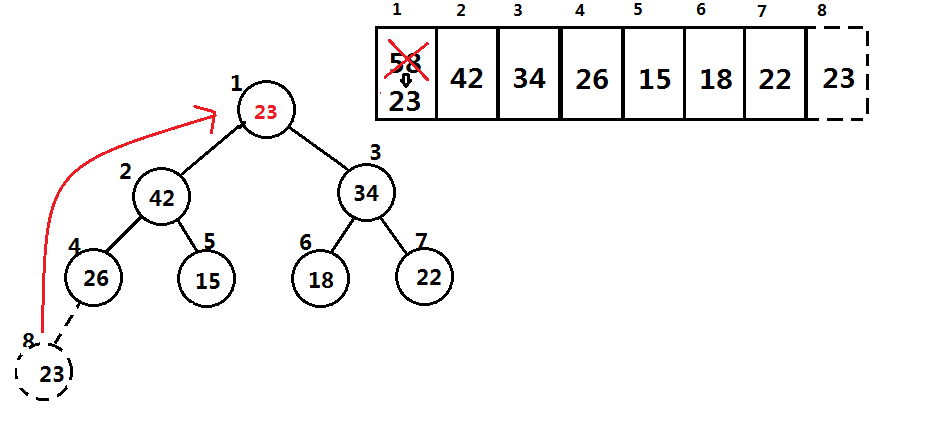
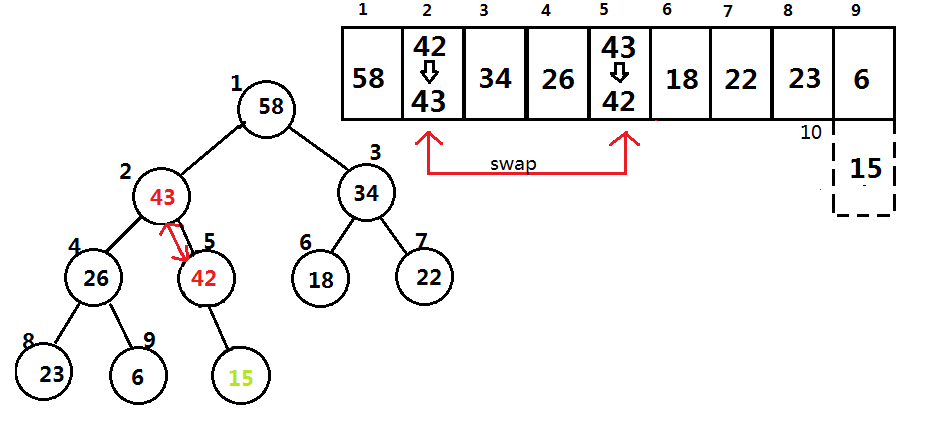
假设插入一个数据为43,新的数据编号为10,先进行堆长度+1,然后根据堆的性质,我们要维护该节点的父节点大于子节点.
-
如何寻找这个新的节点的父节点?
完全二叉树的第四性质,当编号为 (i) 时,其父节点编号为 (lfloor i/2 floor)
-
我们将其父节点的值与子节点的值进行比较,如果子节点大于父节点就交换,一直执行到 (i=0) ,即找不到父节点,如图
2.假设维护一个大根堆,进行取出操作
-
堆的取出一般只取出堆的堆顶元素,其他的元素取出并没有什么意义,那么如何将去除后的序列从新维护成一个堆?我们需要从堆顶开始恢复堆的特性。
-
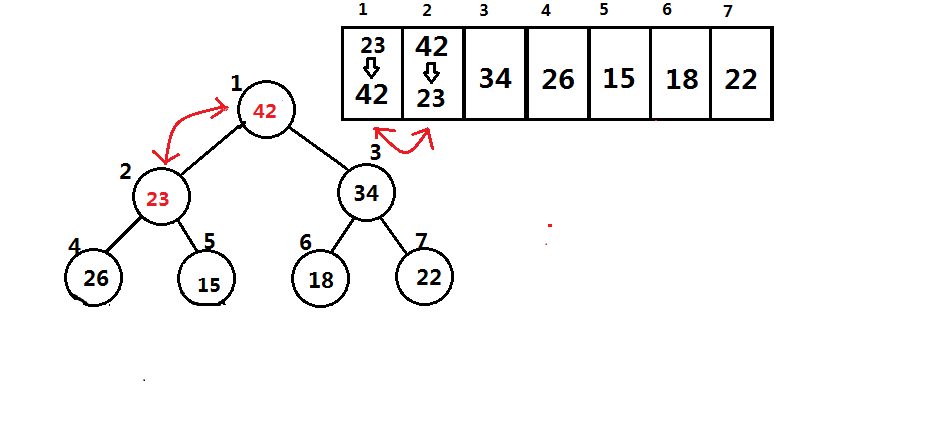
首先查询堆顶的值后,将堆尾的最后一个元素取出覆盖堆顶,然后整个堆的长度-1。
-
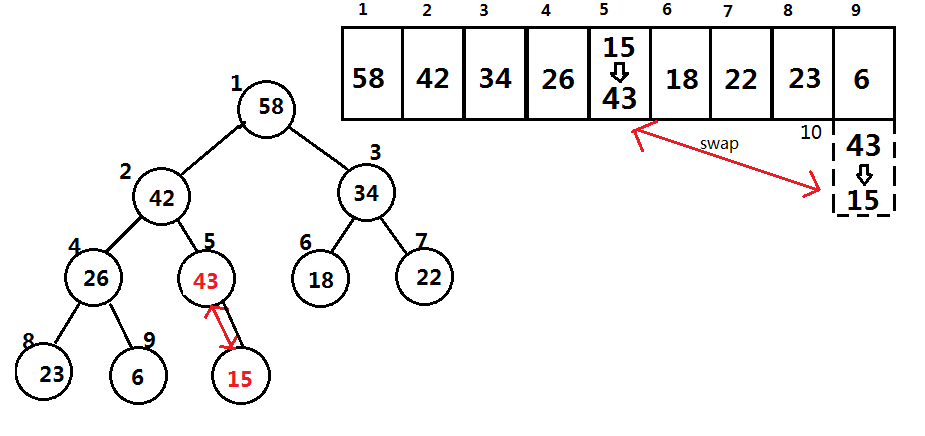
接下来我们需要恢复堆的特性,将堆顶节点的两个子节点与堆顶节点值进行比较,哪个值最大,就将那个值与堆顶进行互换
如何寻找该节点的子节点?
完全二叉树的第三性质,若编号为i的节点有左子节点,则左子节点的编号为 (2i) ;若编号为i的节点有右子节点,则右子节点编号为 (2i+1) 。
-
然后对那个被改变值的节点进行如上操作,之后重复进行这个操作,直到改到一个节点的两个子节点的值都比该节点的值小或,该节点没有子节点则停止操作。如图
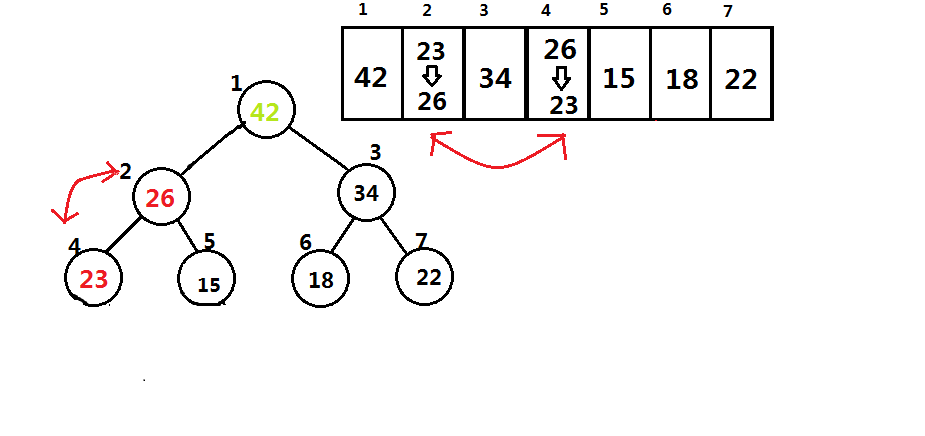
而小根堆的维护方式与大根堆大体相同,只是维护的数据关系不同,只要将大于全部改成小于进行操作即可维护小根堆
堆的模板代码
废话不多说,直接上代码
//这是大根堆的操作模板,小根堆只要将大于号全部改成小于即可 void put(int d) //该函数是插入函数,heap[1]为堆顶 { int now, mid; heap[++Lenth] = d; now = Lenth; while(now > 1) //找不到即停止 { mid = now / 2; if(heap[now] <= heap[mid]) break;//如果当前节点值小于他的父节点,则不进行操作 swap(heap[now], heap[next]); //互换 now = next; //接着下一个节点进行修改 } } int get() //该函数是取出函数 { int now=1, mid, res= heap[1]; heap[1] = heap[Lenth--]; //使队尾元素覆盖堆顶元素 while(now * 2 <= Length) //没有子节点停止 { mid = now * 2; if (mid < Length && heap[mid + 1] < heap[mid]) mid++; //指针还在堆内并且如果当前节点的右子节点比左子节点小,指针+1指向右子节点,否则指向左子节点 if (heap[now] >= heap[mid]) break; //两个子节点都没有父节点大,可以跳出 swap(heap[now], heap[next]); //互换 now = mid; //继续找 } return res; }堆的应用
-
例题:最小函数值 Luogu传送门
大概题意就是求所有给定的二次函数的最小值,然后互相比较下求最小的m个,大暴力显得十分的麻烦,这里我们就可以使用堆这个高级数据结构。
- 我们先构造一个小根堆,计算出所有函数在x为1时的函数值,将这些函数值全部放入堆中,维护一下堆,此时堆顶的函数值是最小的。
- 然后因为要求最小的m个函数值,我们每次计算是都取出堆顶的函数,计算它 $ ++x$ 的函数值,然后从堆顶向下维护,保证堆顶的函数值依然是最小的,重复这个步骤,直到计算出m个最小的函数值,即可停止。
上代码!
#include <stdio.h> #include <algorithm> struct INFO{ int y,x,a,b,c; }; struct INFO info[500005]; void put(int mid){ int now; while(mid>1){ now=mid/2; if(info[mid].y>=info[now].y) break; std::swap(info[now],info[mid]); mid=now; } } void pop(int num){ int mid=1,now; while(mid<=num/2){ now=mid*2; if(now+1<=num && info[now].y>=info[now+1].y) now++; if(info[mid].y<=info[now].y) break; std::swap(info[now],info[mid]); mid=now; } } //put与pop函数可以参照上面堆的模板理解,这题并不需要弹出堆顶 int main(int argc, char const *argv[]){ int n,m;scanf("%d%d",&n,&m); for (register int i = 1; i <= n; ++i){ int a,b,c; scanf("%d%d%d",&info[i].a,&info[i].b,&info[i].c); info[i].x=1; info[i].y=info[i].a+info[i].b+info[i].c;//计算当x=1时的初始函数值 put(i); //放入堆中 } for (register int i = 1; i <= m; ++i){ printf("%d ",info[1].y); info[1].x++; int Va=info[1].a,Vb=info[1].b,Vc=info[1].c,Vx=info[1].x; info[1].y=Va*Vx*Vx+Vb*Vx+Vc; //计算函数值 pop(n); //维护一下堆,不需要弹出,只要保证堆顶最小 } return 0; }
当然有许多的人觉得手打堆模板操作起来过于复杂,难记,当然STL库中也提供了一种序列,优先序列。
感谢您的阅读。
点赞+支持是阁下对我最大的鼓励