测试环境准备
本文主要围绕的对象是mariadb 高级语法, 索引优化, 基础sql语句调优.
下面那就开始搭建本次测试的大环境. 首先下载mariadb开发环境, 并F5 run起来. 具体参照下面文章的具体套路.
C中级 MariaDB Connector/C API 编程教程
数据库环境搭建好了, 我们需要导入一个mysql 中一个测试的sakila数据库进行实验. 通过下面步骤进行demo db搭建.
sakila下载 http://dev.mysql.com/doc/index-other.html
下载成功后, 开始解压, 会得到3个文件只会用到其中两个sql创建脚本, 通过source按照schema -> data 顺序开始导入数据.
mysql -uroot -p source H:/mariadb学习总结/mariadb优化/sakila-db/sakila-schema.sql source H:/mariadb学习总结/mariadb优化/sakila-db/sakila-data.sql
上面路径请自行替换. 最终得到sakila数据库环境如下一共23表. 这里扯一点, sql脚本有时候需要';', 有时候不需要. 是什么原因呢.
一种解释是, 不需要 ';' 的是mariadb系统中内置命令, 单独命令. 需要分号的是执行语句. 为了通用推荐都加上分号.
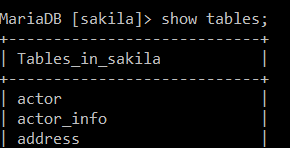
到这里基本数据环境搭建好了. 然后还需要搭建一个慢查询的环境, 用于监测费时的sql操作. 在这里先入为主展现一下最终的搭建环境
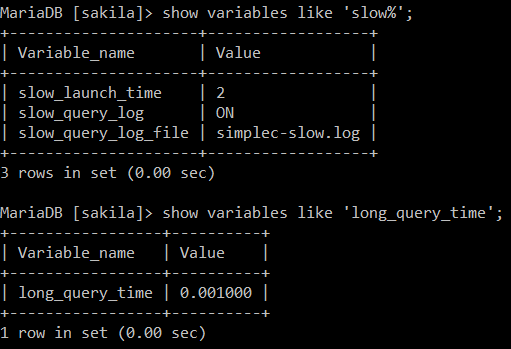
这里主要围绕mariadb 三个全局变量,
slow_query_log (是否开启慢查询),
slow_query_log_file (慢查询指定输出日志文件路径)
long_query_time (慢查询阀值, 单位秒, 只有超过这个时间的查询语句才会被记录到上面的日志文件中).
set global long_query_time = 0.001; set global slow_query_log = on;
对于需要指定的慢查询输出文件路基, 直接采用默认指定路径.
然后完毕当前会话窗口, 再重新打开会话窗口. 就开启了慢查询了. 上面是为了测试方便, 设置慢查询时间阀值为1毫秒.
(对于慢查询是什么, 可以详细查找资料. 慢查询本质其实是把运行慢的sql语句记录保存下来, 方便集中分析调优).
对于慢查询分析, 我们采用默认提供 mysqldumpslow.pl perl脚本进行分析. 需要下载安装perl解释器ActivePerl.
perl解释器下载 https://www.perl.org/get.html
扯一点, 程序员经常需要在本机快速查找文件. 推荐用 Everything 这个工具 !!!
下载安装成功后, 我们简单测试使用一下.从慢查询日志 simplec-slow.log 中查找出前3条慢查询语句, 如下展示.

一切正常, 通过上面能够清晰查找出来那些语句执行的很耗时间.
对于 mysqldumpslow.pl 其它命令 参照 http://www.cnblogs.com/yuqiandoudou/p/4663749.html
扯一点, 对于慢查询公司中有的采用这样套路, 进行可持续好的循环.
1. 每天都会生成慢查询日志, 并通过定时脚本切分
2. 将昨天慢查询日志前100条, 整理成清晰好阅读的文件.
3. 通过邮件发送给每个后端开发的相关人员.
4. 后端老大或核心人员会着手进行优化
到这里基础环境搭建部分, 就扯淡完了. 关于其它更好的回顾方式, 聪明的同学可以自行搜索相关优化高级视频进行学习实践.
本文部分例子参照 : http://www.imooc.com/learn/194 ... mysql性能优化视频
索引优化套路
首先肯定从 explain语句开始 https://mariadb.com/kb/en/mariadb/explain/
先看下面 explain select max(payment_date) from payment;

显示查询 type = ALL 表示查询性能最差. 读取了所有行, 表进行全表扫描。这是坏的 !这一切发生时,优化器找不到任何可用的索引访问行。
那我们优化一下 为其建立一个索引
drop index if exists idx_payment_paydate on payment; create index idx_payment_paydate on payment(payment_date); explain select max(payment_date) from payment;
得到最终结果如下
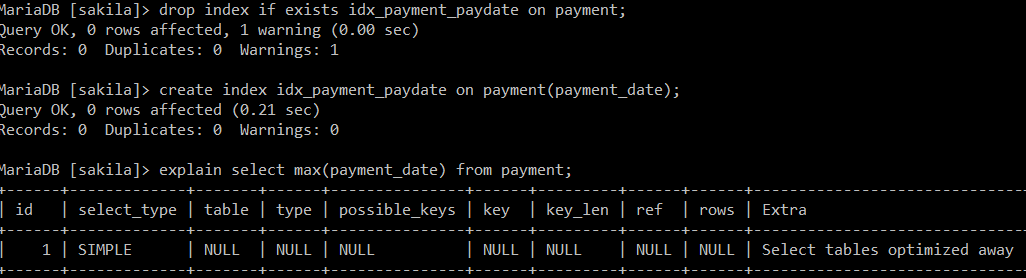
后面发现因为建立了索引, 查询之后立即得到结果, 这个因为建立了索引, 头和尾就是最大最小, 所以没有查询都得到结果了.
这就是建立索引快速查询的好处. 后面开始说索引优化的套路了. percona-toolkit => 数据库优化的神器.
percona-toolkit https://www.percona.com/downloads/percona-toolkit/
percona-toolkit工具包的安装和使用 http://www.cnblogs.com/zping/p/5678652.html
主要会使用到如下内嵌的perl 脚本(其它操作, 自行脑补, 异常管用) .
1. pt-index-usage -> pt-index-usage [OPTION...] [FILE...]
从log文件中读取插叙语句,并用explain分析他们是如何利用索引。完成分析之后会生成一份关于索引没有被查询使用过的报告。
pt-index-usage [慢查询文件路径] --host=localhost --user=root --password=[密码]
上面可以去掉冗余索引问题.
2. pt-query-digest -> pt-query-digest [OPTIONS] [FILES] [DSN]
使用上面工具分析慢查询分析,

详细的可以参照如下资料
pt-query-digest查询日志分析工具 http://blog.csdn.net/seteor/article/details/24017913
以上就是关于mariadb 索引分析(究极分析)总有效, 最方便的方式. 欢迎尝试, 屡试不爽!
高级语法温故
下面到能看见代码的环节了, sql高级语法无外乎, 触发器, 存储过程, 游标! 为什么要用这些, 因为说不定你就遇到了奇葩的jb需求呢.
1. 触发器 trigger
触发器可以通过下面方式记录需要涉及的操作步骤.
监视谁 : 表名
监视动作 : insert / update / delete
触发时间 : after 操作之后 / before 操作之前
触发事件 : insert / update / delete
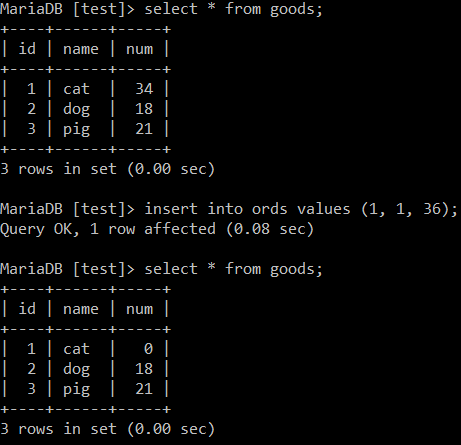
我们通过具体例子分析, 加入现在有个商品表 goods , 和一个订单表 ords . 当订单表完成后, 需要去掉响应商品表中库存.
先构建数据测试环境
use test; drop table if exists test.goods; create table test.goods ( id int not null comment "唯一主键", name varchar(20) not null comment "商品名称", num int not null comment "商品数量", primary key(id) ); insert into goods values (1, 'cat', 34), (2, 'dog', 18), (3, 'pig', 21); drop table if exists test.ords; create table test.ords ( id int not null comment "唯一主键", gid int not null comment "商品id", num int not null comment "购买数量", primary key(id) );
好那我们开始测试, 编写符合上面需求的触发器.
drop trigger if exists tri_ords_insert_before_goods; delimiter $ create trigger tri_ords_insert_before_goods before insert on ords for each row begin declare rnum int; select num into rnum from goods where id = new.gid; if new.num > rnum then set new.num = rnum; end if; update goods set num = num - new.num where id = new.gid; end $ delimiter ;
需要说一下, 外头 for each row begin .. end 是必须套路(行语法级别, 每行都会执行). 这些语法多查查文献都清楚了, 做个试验.
到这里触发器基本回顾完毕. 实际上触发器还是用的. 大家可以从 use sakila; show triggersG 看看更加具体案例.
2. 存储过程 procedure
存储过程可以理解为上层语言中函数. 块语句能够传入数据, 也能返回结果. 同样用一个高斯和来介绍存储过程使用例子.
输出书n, 输出 s = 1 + 2 + .. n的和. 重在体会mariadb sql存储过程的语法直观感受.
-- 来个高斯和 drop procedure if exists proc_gauss; delimiter $ create procedure proc_gauss(in n int, out s int) begin declare i int default n; set s = 0; while i > 0 do set s = s + i; set i = i - 1; end while; select concat("gauss(", n, ") = ", s) gauss; end $ delimiter ;
测试结果如下 :
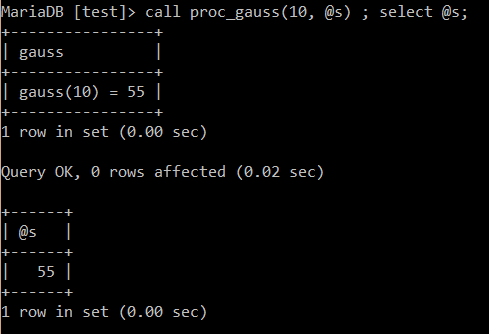
扯一点, 对于存储过程, in 是输出参数, 不会影响外头传入的值. out传入的时候为null, 但会输出. inout就是输入加输出.
set 支持 = 和 := 赋值, declare 声明变量必须要在存储过程开始部位.
3. 游标使用 cursor
对于cursor 游标, 也是有套路的. 总结的笔记是
-- cursor 游标 游标的标志 -- 1条sql, 对应N条资源, 取出资源的接口/句柄, 就是游标 -- 沿着游标, 可以一次取出1行 -- declare 声明; declare 游标名, cursor for select_statement -- open 打开; open 游标名 -- fetch 取值; fetch 游标名 into var1, var2[...] -- close 关闭; close 游标名
这样至少熟悉了游标有那些关键字和操作步骤, 后面同样通过实战例子分析. 但是最需要的还是自我练习. 因为这类脚本多是实践中诞生的, 对动手能力依赖很强.
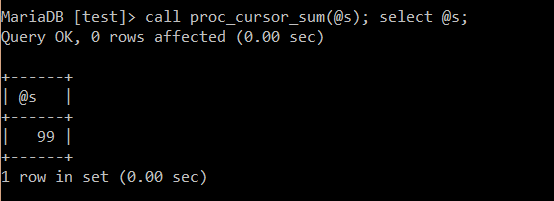
需求 : 我们需要得到某个查询总集中, 按照一定权限占比得到结果. 例如第一条数据权限值是1, 第二条数据权限值为2
以goods表为例, 求出 sum = 求和 num(i) * i. 一般这种需求可以放在应用层处理, 如果只借助sql. 那需要游标来处理.
-- 游标权限处理, 数据库层返回权限和 drop procedure if exists proc_cursor_sum; delimiter $ create procedure proc_cursor_sum(out s int) begin declare r_num int; declare i int default 1; declare lop int default 1; -- 声明游标 declare getnums cursor for select num from goods; -- 声明handler 必须在游标声明之后, 当游标数据读取完毕会触发下面set declare continue handler for not found set lop = 0; set s = 0; -- 打开游标 open getnums; -- 操作游标, 读取第一行数据 fetch getnums into r_num; while lop = 1 do set s = s + r_num * i; set i = i + 1; -- 读取下一个行数据 fetch getnums into r_num; end while; -- 关闭游标 close getnums; end $ delimiter ;
最终操作结果正常
到这里关于mariadb sql常用高级语法编写例子都有了. 是不是发现, 脚本语言还是很容易掌握的, 只需要会查询手册.
常用脚本优化
到这里会介绍几种查询脚本级别的优化方案.
1. 聚集索引的先后顺序. 参照下面例子
use sakila; select * from payment where staff_id = 1 and customer_id = 345; explain select * from payment where staff_id = 1 and customer_id = 345;
首先看 索引分析结果
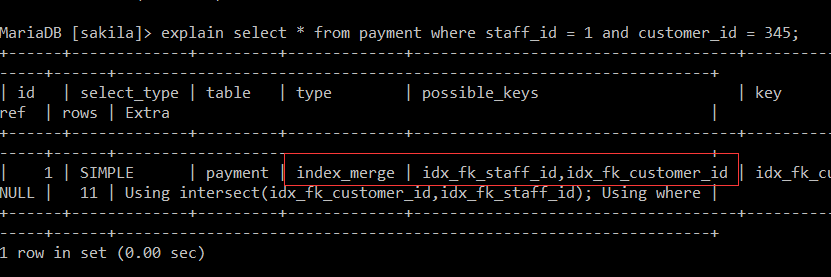
这里先用 staff_id 相关索引, 后用 customer_id 相关索引. 这里有个技巧, 将区分细的放在前面, 减少查询的次数. 那么假如建立聚集索引, 就可以把区分度
高索引放在第一个位置上. 如何区分两个索引顺序可以参照下面sql语句
select count(distinct staff_id) "staff_id_cnt", count(distinct customer_id) "customer_id_cnt" from payment;
2. 对于inner join 子语句数据量越小越好.
xxx inner join ( sql ) on xxx 语句中, 自语句sql 数据量越小查找速度越快, 假如外部where 可以尝试移动到其中.
或者最大化的将外层的 where 或者 group by 迁移到子语句的sql部分中.
3. limit 分页优化
首先直接看下面对比, 查询第(500, 500] 区间内数据.
select film_id, description from film order by film_id limit 500, 5; explain select film_id, description from film order by film_id limit 500, 5;

从中可以看出rows, 查询了505行. 我们优化一下.
select film_id, description from film where film_id >500 and film_id <=505 order by film_id limit 5; explain select film_id, description from film where film_id >500 and film_id <=505 order by film_id limit 5;

这里查询性能的提升是显著的. 完成的功能是一模一样, 这些优化都是有套路的轻松可以快速提升性能. 实在不行了再从硬件层考虑. 因为软件层的优化更加低廉.
4. 设计上优化, 通过unsigned int 代替 time string, bigint 代替 ip string
思路是在mysql只保存时间戳和ip戳, 后面在代码层, 构建转换接口. 例如c 中自己写,
时间串和时间戳转换函数. 可以参照 C基础 时间业务实战代码 . 对于 ip串和ip戳互相转换也简单.
使用系统提供的函数inet_aton和inet_ntoa. 这样就将数据库层运算操作移动到业务层进行运算.
再或者分表查询(垂直分表)等. 分表查询关注点在于 hash分流. 还有读写分析, 一般同主从复制配置.一台服务器写,一台服务器读.
5. 业务上优化, 例如对于大量的排序操作
原先优化是从mysql层剥离处理, 放在业务层处理. 一般让后端服务器自己排序, 再发送数据给客户端.
更加彻底的是, 后端服务器得到数据库服务器数据, 不进行排序. 直接抛给前端单机, 让其消耗客户机进行特殊排序.
其实思路很简单, 将大量重复计算业务抛给客户机去运行. 客户端才是一个系统性能瓶颈.
一个能够快速突破的客户端程序员, 一定是理解过服务器.
然后后记展望
错误是难免的, 欢迎补充☺.
贝多芬的悲伤 http://music.163.com/#/song?id=314773
