第1章 python数据类型
1.1 字符串
1.1.1 去掉重复的字符#strip
name='*egon**'
print(name.strip('*')) 一般用于判断用户输入时需要加操作
print(name.lstrip('*'))
print(name.rstrip('*'))
1.1.2 #startswith,endswith
name='alex_SB'
print(name.endswith('SB'))
print(name.startswith('alex'))
1.1.3 #replace
name='alex say :i have one tesla,my name is alex'
print(name.replace('alex','SB',1))
1.1.4 #format的三种玩法
res='{} {} {}'.format('egon',18,'male')
print(res)
res='{1} {0} {1}'.format('egon',18,'male')
print(res)
res='{name} {age} {sex}'.format(sex='male',name='egon',age=18)
print(res)
1.1.5 寻找元素的位置用find()
name='egon say hello'
print(name.rfind('o',1,3))
print(name.find('o',1,3)) #顾头不顾尾,找不到则返回-1不会报错,找到了则显示索引
# print(name.index('e',2,4)) #同上,但是找不到会报错
1.1.6 查看字符出现的次数,可以指定统计范围
print(name.count('e',1,3)) #顾头不顾尾,如果不指定范围则查找所有
name='root:x:0:0::/root:/bin/bash'
1.1.7 分隔符切片 可以指定以什么为分隔符切几下
print(name.split(":"))
name='C:/a/b/c/d.txt'
print(name.split('/',2))#分2下 为三段
1.1.8 tag.join()
>>> tag=':'
>>> print(tag.join(['egon','say','hello','world'])) #可迭代对象必须都是字符串
egon:say:hello:world
name='egon'
print(name.center(30,'-'))#egon居中两边用- 填充
-------------egon-------------
print(name.ljust(30,'*'))#egon靠左右边用*填充达到30个字符
egon**************************
print(name.rjust(30,'*'))#egon靠右左边用*补齐30个字符
**************************egon
print(name.zfill(50)) #egon左边用0填充
0000000000000000000000000000000000000000000000egon
expandtabs
name='egon hello'
print(name)
print(name.expandtabs(1))
#lower,upper
name='egon'
print(name.lower())
print(name.upper())
#captalize,swapcase,title
print(name.capitalize()) #首字母大写
print(name.swapcase()) #大小写翻转
msg='egon say hi'
print(msg.title()) #每个单词的首字母大写
#is数字系列
#在python3中
num1=b'4' #bytes
num2=u'4' #unicode,python3中无需加u就是unicode
num3='四' #中文数字
num4='Ⅳ' #罗马数字
#isdigt:bytes,unicode
print(num1.isdigit()) #True
print(num2.isdigit()) #True
print(num3.isdigit()) #False
print(num4.isdigit()) #False
#isdecimal:uncicode
#bytes类型无isdecimal方法
print(num2.isdecimal()) #True
print(num3.isdecimal()) #False
print(num4.isdecimal()) #False
#isnumberic:unicode,中文数字,罗马数字
#bytes类型无isnumberic方法
print(num2.isnumeric()) #True
print(num3.isnumeric()) #True
print(num4.isnumeric()) #True
#三者不能判断浮点数
num5='4.3'
print(num5.isdigit())
print(num5.isdecimal())
print(num5.isnumeric())
'''
总结:
最常用的是isdigit,可以判断bytes和unicode类型,这也是最常见的数字应用场景
如果要判断中文数字或罗马数字,则需要用到isnumeric
'''
print('===================================>')
name='egon123'
print(name.isalnum()) #字符串由字母和数字组成
print(name.isalpha()) #字符串只由字母组成
print(name.isidentifier())
print(name.islower())
print(name.isupper())
print(name.isspace())#字符串只包含空格
print(name.istitle())
1.2 列表
1.2.1 定义列表的两种方式
>>> my_girl_friends=['alex','wupeiqi','yuanhao',4,10,30]
>>> #my_girl_friends=list(['alex','wupeiqi','yuanhao',4,10,30])
>>> print(type(my_girl_friends))
<class 'list'>
1.2.2 切片
>>> print(my_girl_friends[1:3])
['wupeiqi', 'yuanhao']
1.2.3 追加
>>> my_girl_friends.append('oldboy')
>>> my_girl_friends
['alex', 'wupeiqi', 'yuanhao', 4, 10, 30, 'oldboy']
1.2.4 删除默认删除最后一个,指定下标指定删除
>>> my_girl_friends.pop()
'oldboy'
>>> my_girl_friends.pop()
30
>>> my_girl_friends.pop(0)
'alex'
>>> my_girl_friends
['wupeiqi', 'yuanhao', 4, 10]
1.2.5 指定元素删除 remove
>>> my_girl_friends.remove('yuanhao')
>>> my_girl_friends
['wupeiqi', 4, 10]
1.2.6 列表与字符串、字典都支持成员关系运算 in 或者 not in
>>> print('wupeiqi' in my_girl_friends)
True
>>> msg = 'my name is lieying'
>>> print('lieying' in msg)
True
1.2.7 取列表的索引跟值
1.2.8 指定位置插入insert (掌握)
>>> my_girl_friends=['alex','wupeiqi','yuanhao',4,10,30]
>>> my_girl_friends.insert(1,'sb')
>>> my_girl_friends
['alex', 'sb', 'wupeiqi', 'yuanhao', 4, 10, 30]
1.2.9 清空整个列表 (以下方法为了解内容)
>>> my_girl_friends.clear()
>>> my_girl_friends
[]
1.2.10 浅复制
>>> l=my_girl_friends.copy()
>>> l
['alex', 'wupeiqi', 'yuanhao', 4, 10, 30]
计算一个元素在列表出现几次count
>>> my_girl_friends
['alex', 'wupeiqi', 'alex', 'yuanhao', 4, 10, 30]
>>> my_girl_friends.count('alex')
2
1.2.11 追加
>>> my_girl_friends.append('oldboy')
>>> my_girl_friends.append('oldboy1')
>>> my_girl_friends.append('oldboy2')
>>> my_girl_friends
['alex', 'wupeiqi', 'alex', 'yuanhao', 4, 10, 30, 'oldboy', 'oldboy1', 'oldboy2']
1.2.12 扩展 合并列表
>>> my_girl_friends.extend(['oldgirl','oldgirl2','oldgirl3'])
>>> my_girl_friends
['alex', 'wupeiqi', 'alex', 'yuanhao', 4, 10, 30, 'oldboy', 'oldboy1', 'oldboy2', 'oldgirl', 'oldgirl2', 'oldgirl3']
>>> print(my_girl_friends.index('alex'))
1.2.13 翻转 reverse 顺序翻转
>>> my_girl_friends.reverse ()
>>> my_girl_friends
['oldgirl3', 'oldgirl2', 'oldgirl', 'oldboy2', 'oldboy1', 'oldboy', 30, 10, 4, 'yuanhao', 'alex', 'wupeiqi', 'alex']
1.2.14 Sort 排序
>>> l = [3,-1,5,2]
>>> l
[3, -1, 5, 2]
>>> l.sort()
>>> l
[-1, 2, 3, 5]
1.2.15 倒序
>>> l.sort(reverse=True)
>>> l
[5, 3, 2, -1]
1.2.16 队列 先进先出
>>> list1=[]
>>> list1.append('lieying')
>>> list1.append('lieying1')
>>> list1.append('lieying2')
>>> list1.append('lieying3')
>>> list1.pop(0)
'lieying'
>>> list1.pop(0)
'lieying1'
>>> list1.pop(0)
'lieying2'
>>> list1.pop(0)
'lieying3'
1.2.17 堆栈先进后出
>>> list2=[]
>>> list2.append('oldboy')
>>> list2.append('oldboy1')
>>> list2.append('oldboy2')
>>> list2.append('oldboy3')
>>> list2.pop()
'oldboy3'
>>> list2.pop()
'oldboy2'
>>> list2.pop()
'oldboy1'
1.3 元组
作用:存多个值,对比列表来说,元组不可变,主要用来读
定义:对比列表类型,把[]换成()
可用作字典的key 属于不可变类型
age =(1,2,3,4) 等同于age=tuple((1,2,3,4))
常用操作:
索引
切片
循环
长度
包含in
1.4 字典
1.4.1 定义字典
#字典的key必须是不可变类型,也成为可hash类型
不可变类型可以为 字符串 整形 元组
info={(1,2):'a'}
print(info[(1,2)])
info={'name':'egon','age':18,'sex':'male'}
#info=dict({'name':'egon','age':18,'sex':'male'})
1.4.2 取key值
>>> info={'name':'egon','age':18,'sex':'male'}
>>> for key in info.keys():
print(key)
sex
age
name
1.4.3取value值 通过字典名[key值]
print(info['age'])
>>> for key in info.values():
print(key)
male
18
Egon
1.4.4 取字典的key:value
>>> for key in info:
print(key,info[key])
sex male
age 18
name egon
法二
>>> for key,values in info.items():
print(key,values)
sex male
age 18
name egon
>>>
1.4.5字典常用的方法(优先掌握)
常规删除
>>> info.pop ('name')
'egon'
避免删除没有的key时报错的方法
>>> info.pop ('adfsdf',None)
#就算没有这个key 也不会报错
否则
>>> info.pop ('adfsdf')
Traceback (most recent call last):
File "<pyshell#5>", line 1, in <module>
info.pop ('adfsdf')
KeyError: 'adfsdf'
1.4.6 避免查询没有的key时报错的方法 用get方法
>>> print(info['name1'])
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
print(info['name1'])
KeyError: 'name1'
>>> info
{'sex': 'male', 'age': 18}
>>> print(info.get('name1'))
None
>>> print(info.get('name1','not key'))
not key
>>>
1.4.7 字典的其他用法
>>> info={'name':'egon','age':18,'sex':'male'}
>>> info.pop () #次方法要求知道key值 与列表的删除最后一个不同
Traceback (most recent call last):
File "<pyshell#14>", line 1, in <module>
info.pop ()
TypeError: pop expected at least 1 arguments, got 0
>>> info.popitem () #随机删除一对键值对
('sex', 'male')
>>> info.popitem ()
('age', 18)
>>> info
{'name': 'egon'}
取字典的额value
1.4.8 清空字典
>>> info={'name':'egon','age':18,'sex':'male'}
>>> info.clear()
>>> info
{}
用一个列表制作一个字典 前提是列表里的元素都为不可变类型
>>> dic=info.fromkeys(['name','age','sex'],11111111)
>>> dic
{'sex': 11111111, 'age': 11111111, 'name': 11111111}
>>> dic=info.fromkeys(['name','age','sex'],None)
>>> dic
{'sex': None, 'age': None, 'name': None}
用关键字参数制作字典
>>> dic=dict(a=1,b=2,c=3)
>>> dic
{'c': 3, 'b': 2, 'a': 1}
制作字典
>>> print(dict([('name', 'egon'), ('age', 18), ('sex', 'male')]))
{'sex': 'male', 'age': 18, 'name': 'egon'}
>>> print(dict([['name', 'egon'], ['age', 18], ['sex', 'male']]))
{'sex': 'male', 'age': 18, 'name': 'egon'}
1.4.9 更新update
>>> info={'name':'egon','age':18,'sex':'male'}
>>> print(info)
{'sex': 'male', 'age': 18, 'name': 'egon'}
>>> dic={'a':1,'b':2,'name':'SHUAI'}
>>> info.update(dic)
>>> info
{'sex': 'male', 'age': 18, 'b': 2, 'a': 1, 'name': 'SHUAI'}
d={}
print(d)
d['name']='egon'
d['age']=18
d['sex']='male'
d['hobby']=[]
d['hobby'].append('play basketball')
d['hobby'].append('play football')
print(d)
1.4.10 Setdefault
d={}
print(d)
d['name']='egon'
d['age']=18
d['sex']='male'
d['hobby']=[]
对于值是一个列表 可以通过以下方式为列表追加元素
d.setdefault('hobby',[]).append('play1')
d.setdefault('hobby',[]).append('play2')
d.setdefault('hobby',[]).append('play3')
print(d)
练习
1 有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。(2分)
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
list1=[11,22,33,44,55,66,77,88,99,90]
dic1={'key1':[],'key2':[]}
# for n in list1:
# if n>66:
# dic1.setdefault('key1',[]).append(n)
# else:
# dic1.setdefault('key2',[]).append(n)
# print(dic1)
for i in list1:
if i>66:
dic1['key1'].append(i)
else:
dic1['key2'].append(i)
print(dic1)
2 统计s='hello alex alex say hello sb sb'中每个单词的个数
结果如:{'hello': 2, 'alex': 2, 'say': 1, 'sb': 2}
s='hello alex alex say hello sb sb'
l=s.split()
dic={}
for item in l:
if item in dic:
dic[item]+=1
else:
dic[item]=1
print(dic)
1.5 集合
集合是一个无序的,不重复的数据组合,他的主要作用如下:
去重,把一个列表变成集合自动去重
关系测试,测试两组数据之间的交集,并集,差集
list_1 = [1,4,5,7,3,6,7,9]
list_1 = set(list_1)
list_2 = set([2,6,0,66,0,22,4])
print(list_1,list_2)
#交集
print(list_1 & list_2)
print(list_1.intersection(list_2))
#并集union
print(list_1 | list_2)
print(list_1.union(list_2))
#差集#diffence
print(list_1 - list_2)
print(list_1.difference(list_2))
#子集
list_3 = {1,3,7}
print(list_3.issubset(list_1))
#父集
print(list_1.issuperset(list_3))
#对称差分集#对称差集
print(list_1 ^ list_2)
print(list_1.symmetric_difference(list_2))
list_4 = {5,6,8}
print(list_3.isdisjoint(list_4)) #两个集合有没有交集
list_1.add(999)
print(list_1)
list_1.update([12,34,23])
print(list_1)
list_1.remove(34)
print(list_1)
print(len(list_1))
print(3 in list_1)
1.6 文件操作
1.6.1 低效 避免用的方法
#f = open('yesterday','r',encoding='utf-8')
# for index,line in enumerate(f.readlines()):
# if index==9:
# print('--------分割线--------')
# continue
# print(line.strip())
#for i in range(5):
# print(f.readline())
1.6.2 #高效的循环方法
f = open('yesterday','r',encoding='utf-8')
count = 0
for line in f:
if count == 9:
print('--------分割线--------')
count +=1
continue
print(line)
count+=1
print(f.tell())#告诉现在在哪个位置
print(f.readline())
print(f.readline())
print(f.readline())
print(f.tell())
f.seek(10)#光标回到哪个位置
print(f.readline())
print(f.encoding)#打印文件的编码
# f = open('yesterday','w',encoding='utf-8')#文件句柄 写模式(新建)
# f = open('yesterday','r',encoding='utf-8')#文件句柄 读模式
# f = open('yesterday','a',encoding='utf-8')#文件句柄 追加模式
# f = open('yesterday','a+',encoding='utf-8')#文件句柄 追加写读
# f = open('yesterday','r+',encoding='utf-8')#文件句柄 读写模式 写只能追加(用的比较多)
# f = open('yesterday','w+',encoding='utf-8')#文件句柄 写读模式(用的比较少)
# f = open('yesterday','rb',)#文件句柄 二进制文件(视频)读模式
# print(f.readline())
f = open('yesterday2','wb',)#文件句柄 二进制写模式
f.write('hello binary
'.encode())转换成bytes类型 默认是utf-8
f.close()
1.6.3 进度条
import sys,time
for n in range(20):
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.1)
文件修改
Cat yesterday2
Yesterday when I was young
昨日当我年少轻狂
So many lovely songs were waiting to be sung
有那么多甜美的曲儿等我歌唱
So many wild pleasures lay in store for me
有那么多肆意的快乐等lieying享受
And so much pain my eyes refused to see
还有那么多痛苦 我的双眼却视而不见
import os
f = open('yesterday2','r',encoding='utf-8')
f_new=open('yesterday.bak','w',encoding='utf-8')
for line in f :
if '肆意的快乐等我享受' in line:
line = line.replace('肆意的快乐等我享受','肆意的快乐等lieying享受')
f_new.write(line)
f.close()
f_new.close()
os.remove('yesterday2')
os.rename('yesterday.bak','yesterday2')
1.6.4 打开文件的方式 用with 可以避免忘记关闭文件
with open('yesterday2','r',encoding=' utf-8') as f,with open('yesterday.bak','w',encoding='utf-8') as f_new:
pass
1.7 字符编码
1.7.1 Python执行的三个阶段
阶段一:启动python解释器
阶段二:python解释器此时就是一个文本编辑器,负责打开文件test.py,即从硬盘中读取test.py的内容到内存中
此时,python解释器会读取test.py的第一行内容,#coding:utf-8,来决定以什么编码格式来读入内存,这一行就是来设定python解释器这个软件的编码使用的编码格式这个编码,
可以用sys.getdefaultencoding()查看,如果不在python文件指定头信息#-*-coding:utf-8-*-,那就使用默认的
python2中默认使用ascii,python3中默认使用utf-8
阶段三:读取已经加载到内存的代码(unicode编码的二进制),然后执行,执行过程中可能会开辟新的内存空间,比如x="egon"
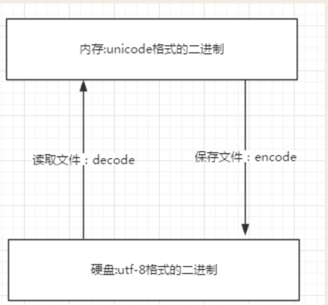
内存的编码使用unicode,不代表内存中全都是unicode编码的二进制,
在程序执行之前,内存中确实都是unicode编码的二进制,比如从文件中读取了一行x="egon",其中的x,等号,引号,地位都一样,都是普通字符而已,都是以unicode编码的二进制形式存放与内存中的
但是程序在执行过程中,会申请内存(与程序代码所存在的内存是俩个空间),可以存放任意编码格式的数据,比如x="egon",会被python解释器识别为字符串,会申请内存空间来存放"hello",然后让x指向该内存地址,此时新申请的该内存地址保存也是unicode编码的egon,如果代码换成x="egon".encode('utf-8'),那么新申请的内存空间里存放的就是utf-8编码的字符串egon了
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。
- 总结:
- 无论是何种编辑器,要防止文件出现乱码(请一定注意,存放一段代码的文件也仅仅只是一个普通文件而已,此处指的是文件没有执行前,我们打开文件时出现的乱码)
- 核心法则就是,文件以什么编码保存的,就以什么编码方式打开
1.7.2 打印到终端
对于print需要特别说明的是:
当程序执行时,比如
x='林'
print(x) #这一步是将x指向的那块新的内存空间(非代码所在的内存空间)中的内存,打印到终端,而终端仍然是运行于内存中的,所以这打印可以理解为从内存打印到内存,即内存->内存,unicode->unicode
对于unicode格式的数据来说,无论怎么打印,都不会乱码
python3中的字符串与python2中的u'字符串',都是unicode,所以无论如何打印都不会乱码
在windows终端(终端编码为gbk,文件编码为utf-8,乱码产生)
在linux终端(终端编码为utf-8,文件编码为gbk,乱码产生)
这就是同一段代码在不同终端打印效果不一样的原因