一、ES安装
(一)安装步骤
在安装ES相关软件前需要先安装JDK,Linux下安装JDK:https://www.cnblogs.com/liconglong/p/14559373.html,这里需要注意一下,JDK要安装到/etc目录下,因为ES不能使用root权限启动,所以如果安装到其他目录,则会导致不同的用户不能使用JDK的问题。
下载ES可以直接在ES官网下载即可:https://www.elastic.co/cn/downloads/elasticsearch
在linux中创建es的安装目录/home/es,以及es的日志、数据等目录,由于es不能使用root用户启动,因此还需要创建一个新的用户来启动。
mkdir -p /data/logs/es mkdir -p /data/es/{data,work,plugins,scripts} mkdir /home/es tar -zxvf elasticsearch-6.2.4.tar.gz useradd es
先说安装步骤,再说每一步解决的问题:
在root权限下执行:
1、为es用户授权执行权限:chown -R es:es elasticsearch-6.2.4,解决问题:1-3
2、修改es配置文件:vi config/elasticsearch.yml,修改network.host为0.0.0.0,解决问题:4
3、修改每个进程打开的文件数以及线程数:vi /etc/security/limits.conf,解决问题:5
* soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096
4、修改VM中map的最大数:vi /etc/sysctl.conf,在最后添加如下参数,并执行命令让配置实时生效(命令:/sbin/sysctl -p),解决问题:5
5、关闭防火墙,解决问题:7
systemctl stop firewalld #临时关闭
systemctl disable firewalld #永久关闭,即设置开机的时候不自动启动
(二)解决问题
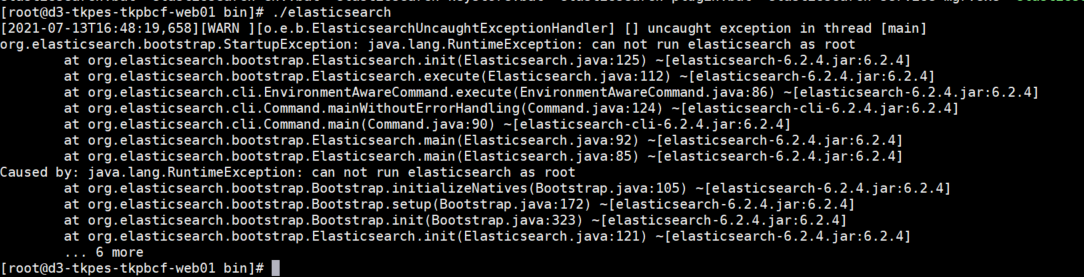
1、切换到es下的bin目录,执行:./elasticsearch,会出以下错误,这是说明root用户不能执行该命令,需要使用其他用户。(命令:su es)
2、切换用户后,ls查看用户下文件,发现没有任何内容,因此需要给es用户添加./elasticsearch的执行权限(切换到root权限后(sudo -i)执行命令:chown -R es:es elasticsearch-6.2.4),执行后重新使用ls查看es用户权限
![]()
3、重新执行./elasticsearch命令,就可以启动了
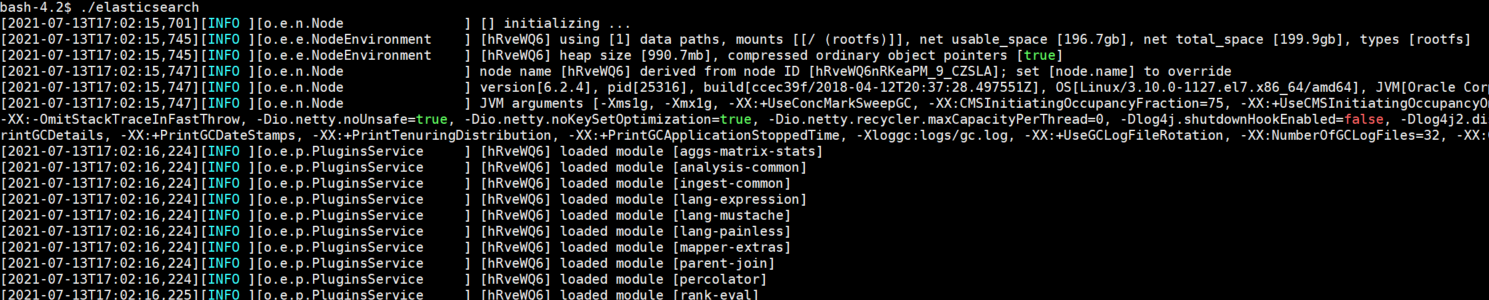
4、可以看到启动的端口为9200,然后使用IP+端口在浏览器中访问ES服务,发现不能访问,需要修改ES的配置文件(在ES目录的config文件夹中,修改命令:vi config/elasticsearch.yml),修改network.host为0.0.0.0,需要使用root权限修改

5、在es用户下重新执行启动ES命令( 命令:./elasticsearch),发现ES设置的最大文件数和最大线程都太低

6、修改每个进程打开的文件数(切换到root权限,执行命令:vi /etc/security/limits.conf)
在文件最后增加下面配置(*号代表所有用户)
* soft nofile 65536 * hard nofile 131072 * soft nproc 4096 * hard nproc 4096
修改 /etc/sysctl.conf,在最后添加如下参数,并执行命令让配置实时生效(命令:/sbin/sysctl -p)
vm.max_map_count=262144
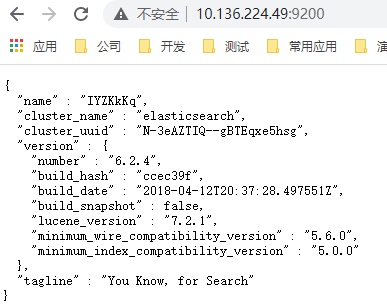
7、重新通过浏览器进行访问,还是不可以访问,这时需要关闭防火墙,关闭后,重新启动并访问,就可以进行访问了。
systemctl stop firewalld #临时关闭
systemctl disable firewalld #永久关闭,即设置开机的时候不自动启动
二、Head插件安装
ElasticSearch-Head是一个用来浏览、与ES进行交互的web插件。
ElasticSearch-Head可以用来做以下操作:
1、节点展示,显示节点拓扑,并允许执行索引和节点层面的操作。
2、进行查询
3、显示节点状态
4、支持Restful接口
安装步骤:
#下载nodejs,head插件运行依赖node wget https://nodejs.org/dist/v9.9.0/node-v9.9.0-linux-x64.tar.xz #解压 tar -xf node-v9.9.0-linux-x64.tar.xz #重命名 mv node-v9.9.0-linux-x64 /usr/local/node #配置文件 vim /etc/profile #将node的路径添加到path中 export PATH=$PATH:$JAVA_HOME/bin:/usr/local/node/bin #刷新配置 source /etc/profile #查询node版本,同时查看是否安装成功 node -v #下载head插件 wget https://github.com/mobz/elasticsearch-head/archive/master.zip #解压 unzip master.zip #使用淘宝的镜像库进行下载,速度很快 npm install -g cnpm --registry=https://registry.npm.taobao.org #进入head插件解压目录,执行安装命令 cnpm install
此时就可以使用ES-Head了,但是还有重要的一步,就是需要开启ES的CORS,否则在浏览器中虽然可以访问ES-Head界面,但是却不能访问ES,因为ES默认不允许跨域请求的。调整es的配置文件,在配置文件(config/elasticsearch.yml)的最后添加如下配置:
http.cors.enabled: true http.cors.allow-origin: "*"
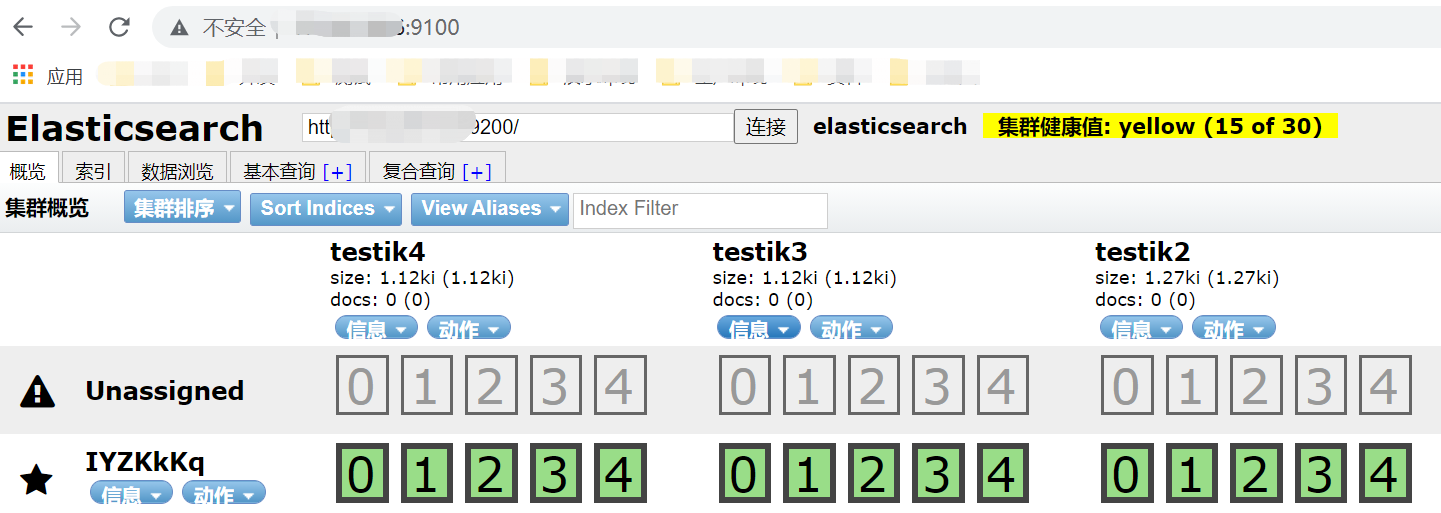
安装完成后,重新启动es,启动后,再启动ES-Head:npm start,然后在页面访问ES-Head,默认端口为9100
三、Logstash
(一)基本使用
Logstash是一个具有实时管道的开源数据手机引擎,其可以动态的收集不同来源的数据,并将数据归到不同的目的地,同时其也是一个管理事件和日志工具,可以用它来进行日志收集。
下载并解压
#注意版本和elasticsearch,kibana 必须保持一致,es,kibana都是6.2.4版本 wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz #解压 tar -zxvf logstash-6.2.4.tar.gz
然后可以在命令行进行启动验证,直接执行bin目录下的logstash脚本即可,该脚本用 -e 来指定要执行的配置文件,也可以直接跟命令,命令必须跟双引号,如果使用单引号会报错。
命令如下:
启动 基本的 intput output #stdin stdout 输入输出插件 ./logstash -e 'input{ stdin{} } output{ stdout{} }' # codec ./logstash -e 'input{ stdin{} } output{ stdout{ codec => json } }' #日志内容写入elasticsearch ./logstash -e 'input{ stdin{} } output{ elasticsearch{hosts => ["ip:9200"]} }' #日志内容写入elasticsearch,同时输出 #注意elasticsearch插件的语法格式:hosts 对应数组 ./logstash -e 'input{ stdin{} } output{ elasticsearch{hosts => ["ip:9200"]} stdout{} }'
如上所示,可以使用上面的命令进行操作,直接演示最后一个,命令的意思是将日志内容写入ES并在控制台进行输出。
在命令行输入后,命令行会等待输入,直接输入字符串后即可。
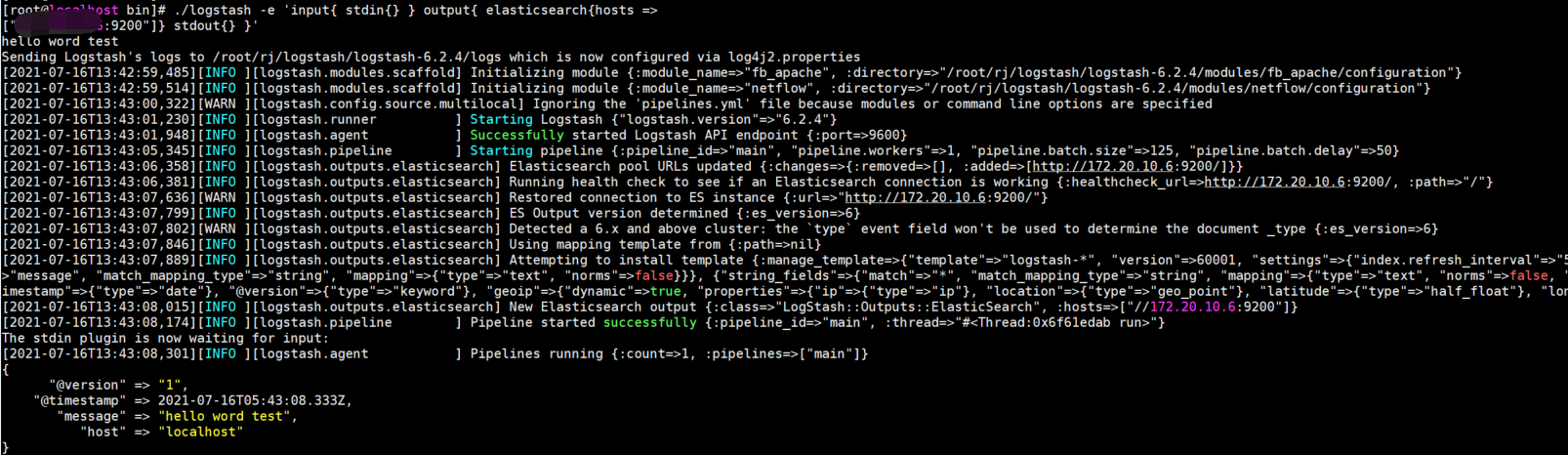
然后在ES-Head控制台查看数据,可以看到数据已经同步到ES。

对于文本的输出格式(codec)可以有:olain(读取原始数据)、dots(将内容简化为点进行输出)、rubydebug(将内容按照ruby格式输出,方便调试)、json、muitiline(处理多行数据内容)、line(处理带有换行符的内容)
(二)file日志收集
在logstash的config文件夹下创建配置文件filelog.conf(命令:touch logstash.conf),然后配置如下信息:
input { file{ path => "/var/log/messages" #收集messages文件日志 type => "system" start_position => "beginning" #记录上次收集的位置 } } output { elasticsearch { hosts => ["ip:9200"] #写入elasticsearch的地址 index => "system-%{+YYYY.MM.dd}" #定义索引的名称 } stdout { codec => rubydebug } }
这个配置就是收集系统的操作日志,然后启动logstash:./bin/logstash -f config/logstash.conf
然后查看ES-Head,就可以看到收集的file日志。
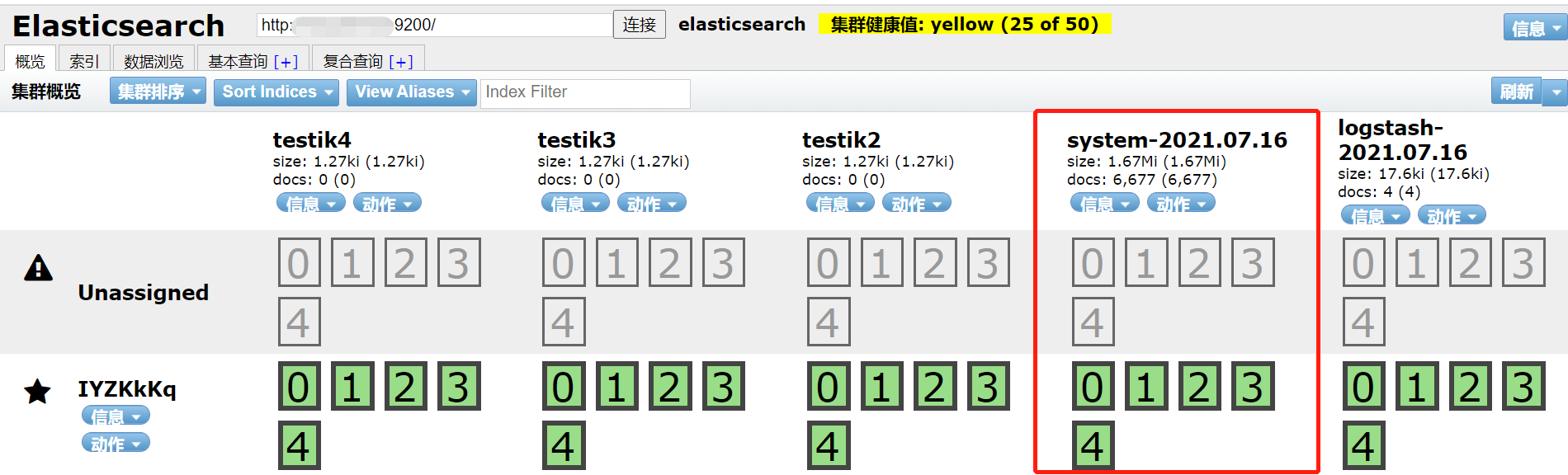
(三)java日志收集
创建一个javafile.conf的配置文件,配置内容如下:
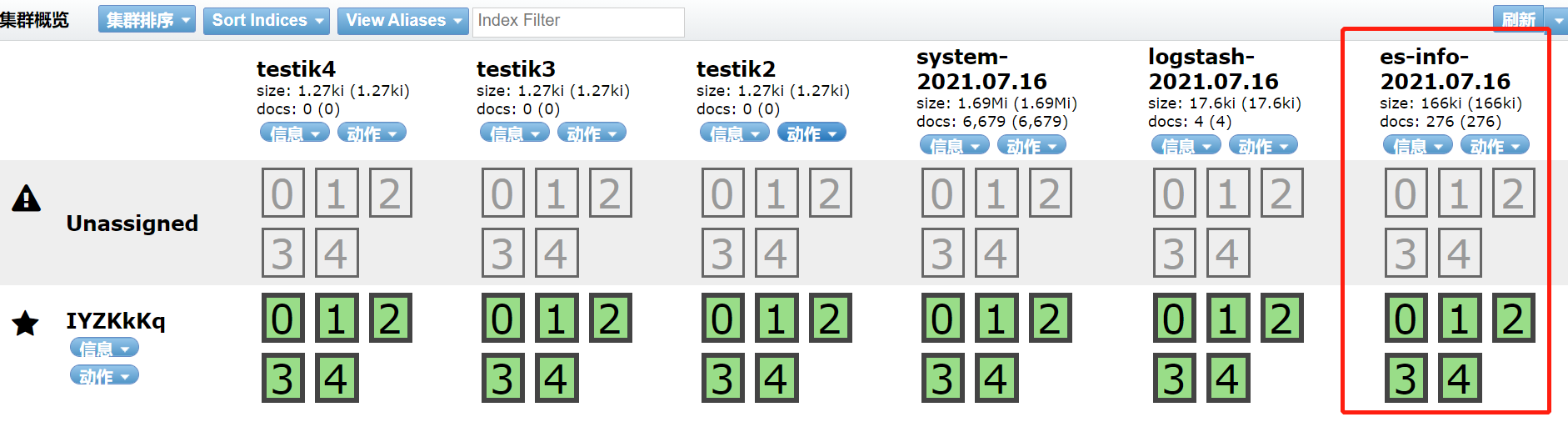
input { file{ path => "/var/log/messages" type => "system" start_position => "beginning" } #加一个file文件收集日志插件,收集elasticsearch日志、es就是java语言开发的。 file{ path => "/home/es/elasticsearch-6.2.4/logs/elasticsearch.log" type => "es-info" start_position => "beginning" } } output { if [type] == "system"{ elasticsearch { hosts => ["ip:9200"] index => "system-%{+YYYY.MM.dd}" } } #判断,导入到不同的索引库,否则会放入同一个索引库中 if [type] == "es-info"{ elasticsearch { hosts => ["ip:9200"] index => "es-info-%{+YYYY.MM.dd}" } } stdout { codec => rubydebug } }
这里还有一个问题,就是有的日志太长,一句话被输出为多行,那么被logstash收集会被拆分开收集,就不便于查看。这个问题可以用codec的正则表达式来合并多行日志。
file{ path => "/home/es/elasticsearch-6.2.4/logs/elasticsearch.log" type => "es-info" start_position => "beginning" #使用正则表达式,合并多行日志 codec => multiline { pattern => "^[" #发现中括号,就合并日志 negate => true what => "previous" } }
(四)项目日志
input { tcp { port => 9600 codec => json } } output { elasticsearch { hosts => ["ip:9200"] index => "kkb-log-%{+YYYY.MM.dd}" } stdout {codec => rubydebug } }
四、Kibana
(一)安装
Kibana的下载可以直接在官网下载,不过有时国内访问官网可能网络不好,也可以使用华为云或者阿里云下载。官网:https://www.elastic.co/cn/downloads/kibana,国内方便下载的汇总地址:https://www.newbe.pro/Mirrors/Mirrors-Kibana/
kibana的版本号要与ES的版本号保持一致。
wget https://mirrors.huaweicloud.com/kibana/6.2.4/kibana-6.2.4-linux-x86_64.tar.gz tar -zxvf kibana-6.2.4-linux-x86_64.tar.gz
配置环境(config/kibana.yml):
# 将默认配置改成如下: server.port: 5601 server.host: "" #修改成自己集群的端口号及IP elasticsearch.url: "http://ip:9200" kibana.index: ".kibana"
启动:./bin/kibana
(二)可视化试图
1、Management
第一次使用,选择Management,然后选择Index Patterns,搜索想要查询的index日志


2、Discover
然后可以在Discover中对该index进行搜索,可以选择是否自动刷新,搜索时间区间以及搜索内容

3、Dashboard
在Dashboard中可以选择试图的形式进行查看