一、Kafka简介
Kafka是一个快速的、可扩展的、高吞吐的、可容错的分布式发布订阅系统,与传统的消息中间件(ActiveMQ、RabbitMQ)相比,Kafka具有高吞吐量、内置分区、支持消息副本和高容错的特点,非常适合大规模消息处理应用程序。
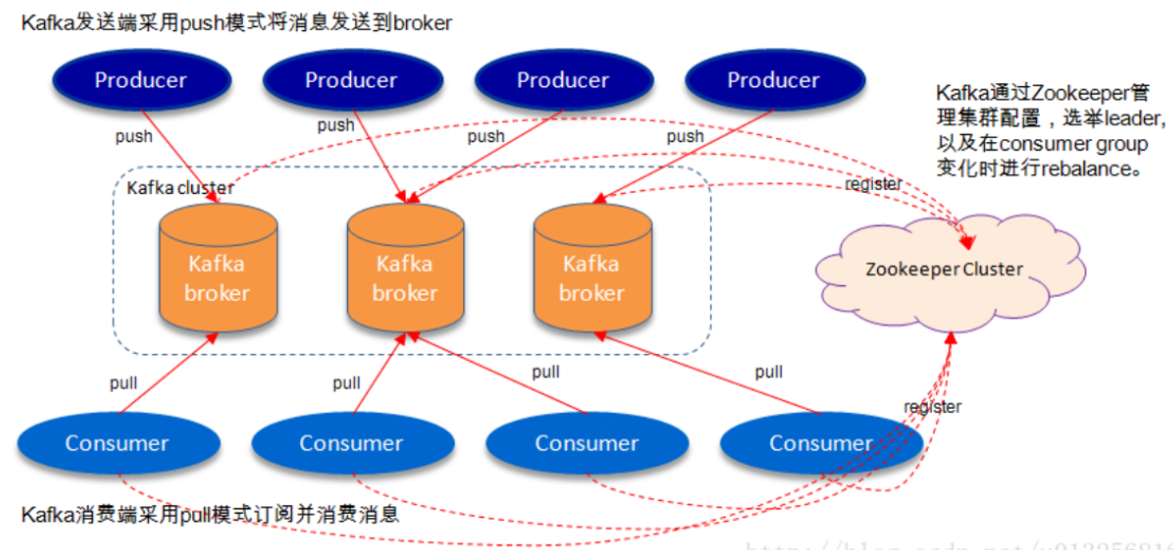
其系统架构如下所示
Kafka的应用场景很多,以下是几个比较常见的场景:
消息系统 Messaging
Web网站活动追踪 Website Activity Tracking
数据监控 Metrics
日志聚合 Log Aggregation
流处理 Stream Processing
事件源 Event Sourcing
提交日志 Commit Log
Kafka与其他MQ相比最大的特点就是吞吐率高,为了增加存储能力,Kafka将所有的消息都存放在了硬盘上,但是由于Kafka采用了如下方式,其仍然保证了高吞吐率:
顺序读写:Kafka将消息写入到了分区partition中,而分区中消息是顺序读写的,顺序读写的速度要远高于随机读写
零拷贝:生产者、消费者对于Kafka中消息的操作是采用零拷贝实现的。
批量发送:Kafka允许使用批量消息发送模式
消息压缩:Kafka支持对消息进行压缩
二、Kafka的基本术语
| 术语 | 说明 |
| Topic | 主题,用于划分消息类型,类似于分类标签,是个逻辑概念 |
| Partition | 分区,topic中的消息被分割为一个或多个partition,是一个物理概念,对应到系统上的是一个或者多个目录 |
| Segment | 段,将partition进一步细分为若干个段,每个segment文件的最大大小相等 |
| Broker | Kafka集群包含一个或多个服务器,每个服务器节点称为一个Broker,一个topic中设置partition的数量是broker的整数倍 |
| Producer | 生产者,即消息发送者,会将消息发送到相应的partition中 |
| Consumer Group | 消费组,一个partition中的消息只能被同一个消费组中的一个消费者进行消费;而一个消费组内的消费者只会消费一个或者几个特定的partition |
| Replication of partition | 分区副本,副本是一个分区的备份,是为了防止消息丢失而创建的分区备份 |
| Partition Leader | 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责读写的partition,即所有读写操作只能发生于Leader分区上 |
| Partition Follower | 所有Follower都要从Leader上同步消息,Follower与Leader始终保持消息同步;partition leader与partition follower之间是主备关系而非主从关系 |
| ISR | ISR:In-Sync Replicas,是指副本同步列表;AR:Assiged Replicas,指所有副本;OSR:Outof-Sync Replicas;AR=ISR+OSR |
| offset | 偏移量,每个消息都有一个当前Partition下唯一的64字节的offset,他是相当于当前分区第一条消息的偏移量 |
| offset commit | 当consumer从partition中消费了消息后,consumer会将其消费消息的offset提交给broker,表示当前partition已经消费到了该offset所标识的消息。 |
| Rebalance | 当消费者组中消费者数量发生变化或者topic中partition数量发生变化,partition的所有权会在消费者间转移,即partition会重新分配。 |
| __commit_offsets | 消费者提交的offset被封装为了一种特殊的消息被写入到一个由系统创建的、名称为__commit_offstes的特殊topic的partition中,该topic默认包含50个partition,这些offset的默认有效期为一天 |
| Broker Controller | Kafka集群的多个broker中,会有一个被选举为controller,负责管理集群中partition和副本replicas的状态。 |
| Zookeeper | 负责维护和协调Broker,负责Broker Controller的选举;这里要说明一下,Broker Controller是由Zookeeper选举出来的,而Partition Leader是由Broker Controller选举出来的。 |
| Group Coordinator | group coordinator是运行在broker上的线程,主要用于consumer group中各个成员的offset位移管理和Rebalance;Group Coordinator同时管理着当前broker的所有消费者组。当Consumer需要消费数据时,并不是直接中__comsumer_offset的partition中获取的,而是从当前broker的Coordinator的缓存中获取的。而缓存中的数据是在consumer消费完提交offset时,同时提交到coordinator的缓存以及__consumer_offset的partition中的。 |
三、Kafka的工作原理及过程
路由策略:
在通过API方式发布消息时,生产者是以Record为消息进行发布的,Record中包含Key和Value,其中value就是我们真正要使用的消息,而key是用于路由消息要存放的位置的。
消息要放入到哪个partition并不是随机的,而是按照以下路由策略进行处理的:
如果制定了partition,则直接写入指定的partition
如果没有指定partition但是指定了key,则通过key的hash值与partition数量进行取模,取模结果就是partition的索引
如果partition和key都未指定,则使用轮询算法选出一个partition
消息写入算法:
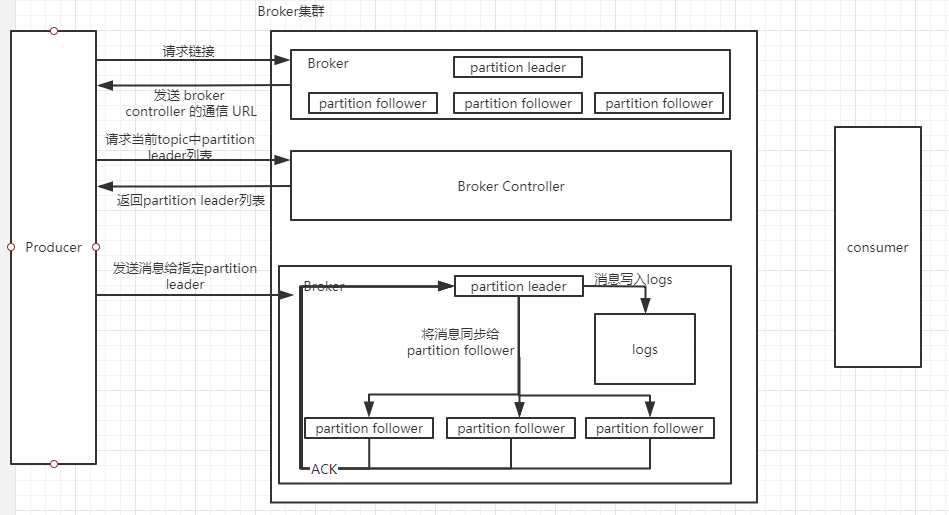
1、producer向broker集群提交连接请求,其所连接上的任意一个broker都会向其发送broker controller的通信URL,即broker controller主机配置文件中的listeners地址
2、当producer指定了要生产消息的topic后,其会向broker contriller发送请求,请求当前topic的所有partition leader
3、broker controller在接收到请求后,会从zk服务器中查找指定topic的所有partition leader返回给producer
4、producer在接收到partition leader列表后,会根据路由策略找到对应的partition leader,将消息发送该partition leader
5、leader将消息写入log,并通知ISR中的followers
6、ISR中的follower从leader中同步消息后向leader发送ACK消息
7、leader收到了所有ISR中的follower的ACK后,增加HW,表示消费者可以消费到该位置;如果leader在等待的follower的ACK超时了,发现还有follower没有发送ACK,则会将这些没有发送ACK的follower从ISR中剔除,然后再增加HW
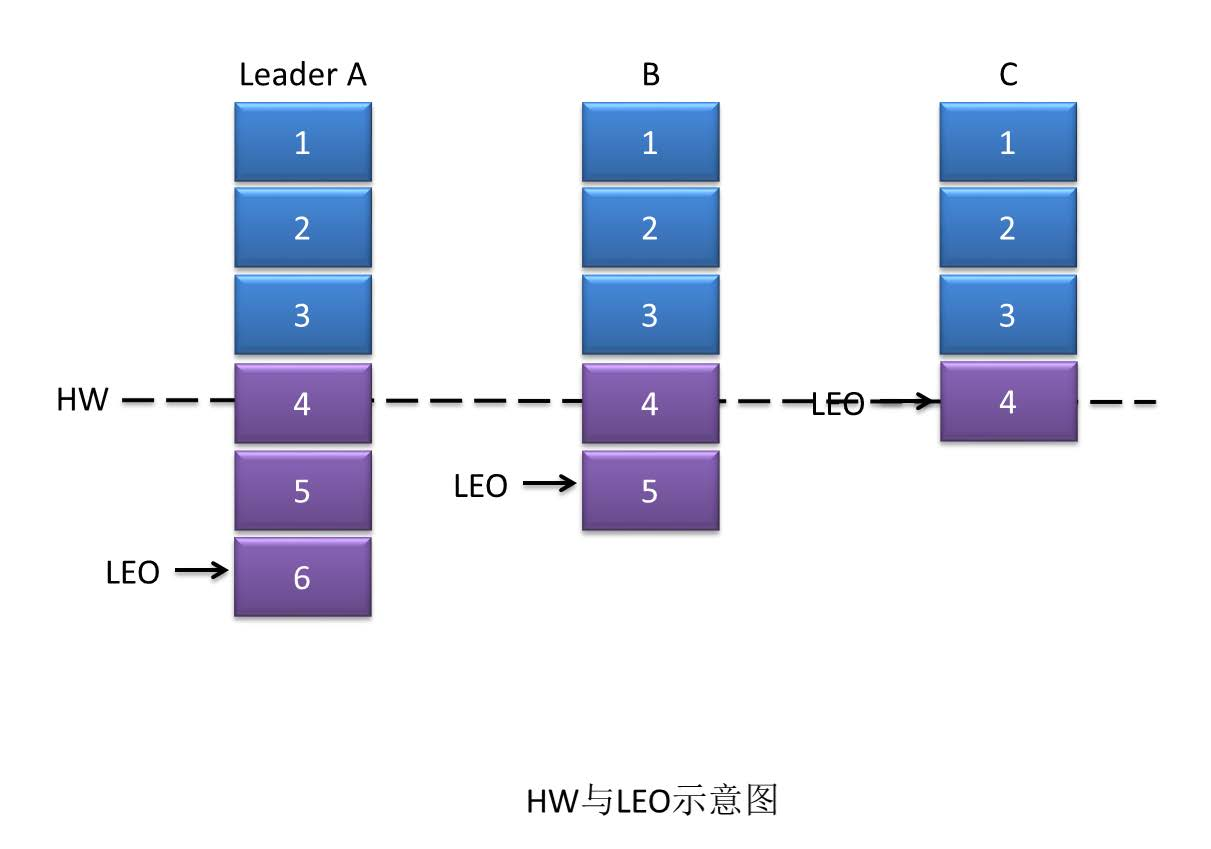
HW(高水位):
上面说到leader收到了所有ISR中的follower的ACK后,就会增加HW,这里的HW是高水位的意思,表示consumer可以消费到的最高partition偏移量。
HW保证了Kafka集群中消息的一致性,确切地说,是在broker集群正常运转的情况下,保证了partition的follower和leader之间数据的一致性。
LEO,Log End Offset,日志最后消息的偏移量,消息是被写入到Kafka的日志文件中的,这是当前最后一个写入的消息在partition中的偏移量。
对于新写入的消息,consumer是不能立刻消费的,leader会等待该消息被所有的ISR中的partition follower同步后才会更新HW,此时消息才能被consumer消费。
HW截断机制:
如果partition leader接收到了新的消息,ISR中其他follower正在同步过程中,还未同步完毕leader就挂了,此时就需要选举新的leader,若没有HW截断机制,将会导致partition中Leader与Follower数据不一致。
当原leader宕机恢复后,将其LEO回退到宕机时的HW,然后再与新的Leader进行数据同步,这种机制称为HW截断机制。
HW截断机制会引起数据丢失。
消息发送的可靠性机制:
生产者向Kafka发送消息时,可以选择可靠性级别,通过acks参数的值进行设置
0:异步发送,生产者向kafka发送消息而不需要kafka反馈成功ack,该方式效率最高,但是可靠性最低,可能会存在数据丢失的问题。
1:同步发送,默认值。生产者发送消息给kafka,broker的partition leader在收到消息后,会反馈ack,生产者收到后才会在发送消息,如果一直未收到kafka的ack,则生产者会认为消息发送失败,会重发消息。该种情况,仍然可能存在数据丢失的问题,因为如果partition leader收到消息并返回了ack,但是在同步partition follower时leader发生宕机,此时需要选举新的leader,即HW截断机制的发生。
-1:同步发送,其值等同于all,生产者发送消息给kafka,kafka收到消息后,要等到ISR列表中的所有副本都同步消息完成后,才向生产者发送ack。该模型的可靠性最高,很少出现数据丢失的情况,但是可能出现部分follower重复接收消息的情况(不是重复消息)。
消费者消费过程解析:

1、consumer向broker集群提交连接请求,其所连接上的任意broker都会向其发送broker controller的通信URL,即broker controller主机配置文件中的listeners。
2、当consumer指定了要消费的topic后,其会向broker controller发送poll请求
3、broker controller会为consumer分配一个或这几个partition leader,并将该partition的当前offset发送给consumer
4、consumer会按照broker controller分配的partition对其中的消息进行消费
5、当consumer消费完该条数据后,消费者会向broker发送一个消息已被消费的反馈,即该消息的offset。
6、当broker接收到consumer的offset后,会将其更新到__consumer_offset中
7、以上过程一直重复,直到消费者停止请求消息;消费者可以重置offset,从而可以灵活的消费存储在broker上的消息
Partititon Leader选举范围:
当leader挂了后,broker controller会从ISR中选一个follower成为新的leader,但是如果所有的follower都挂了怎么办?可以通过unclean.leader.election.enable的取值来设置leader的选举范围。
false:必须等待ISR列表中由副本活过来才进行新的选举,该策略可靠性有保证,但是可用性低
true:在ISR中没有副本存活的情况下,可以选择任何一个该topic的partition作为新的leader,该策略可用性高,但是可靠性没有保证,可能会引发大量的消息丢失。
重复消费问题即解决方案:
重复消费最常见的有两种情况:同一个consumer的重复消费和不同consumer的重复消费
同一个consumer的重复消费:
当consumer由于消费能力较低而引发消费超时时,则可能会引发重复消费。
解决方案:可以减少读取的消息个数,也可以演唱自动提交的时间,还可以将自动提交转变为手动提交。
不同consumer的重复消费:
当consumer消费了消息但还未提交offset时宕机,则这些已被消费过的消息会被重复消费。