一、零拷贝
零拷贝指的是从一个存储区域到了另一个存储区域的copy任务没有CPU参与,零拷贝通常用于网络文件传输,以减少CPU消耗和内存带宽占用,减少用户空间和CPU内核空间的拷贝过程,减少用户上下文与CPU内核上下文间的切换,提高系统效率。
用户空间指的是用户可操作的内存缓存区域,CPU内核空间是指仅CPU可以操作的寄存器缓存及内存缓存区域。
用户上下文指的是用户状态环境,CPU内核上下文指的是CPU内核环境状态。
零拷贝需要DMA控制器的协助,DMA,Direct Memory Access,直接内存存取,是CPU的组成部分,其可以在CPU内核不参与运算的情况下将数据从一个地址空间拷贝到另一个地址空间。
下面以将一个硬盘中的文件通过网络发送出去为例,来分析一下不同拷贝方式的实现细节。
1、传统的拷贝方式
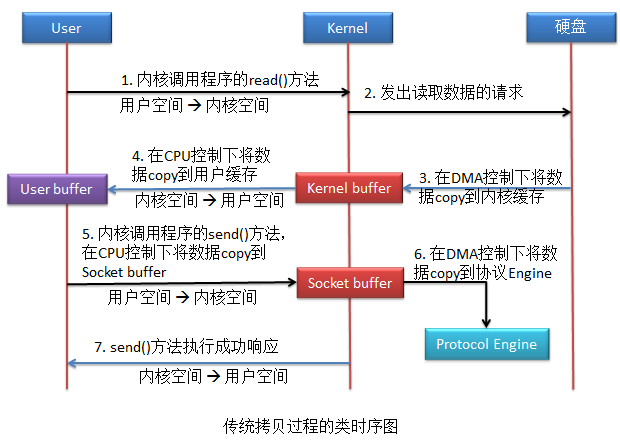
首先通过应用程序的read()方法将文件从硬盘中读取出来,然后再调用send()方法将文件发送出去。
该拷贝方式共惊醒了4次用户空间与内核空间的的上下文切换,以及4次数据拷贝,其中两次拷贝存在CPU参与。
这里有一个很明显的问题:应用程序的作用仅仅就是一个数据传输的中介,最后将kernel buffer中的数据传递到了socket buffer,显然是没有必要的,所以就引入了零拷贝。
2、零拷贝方式
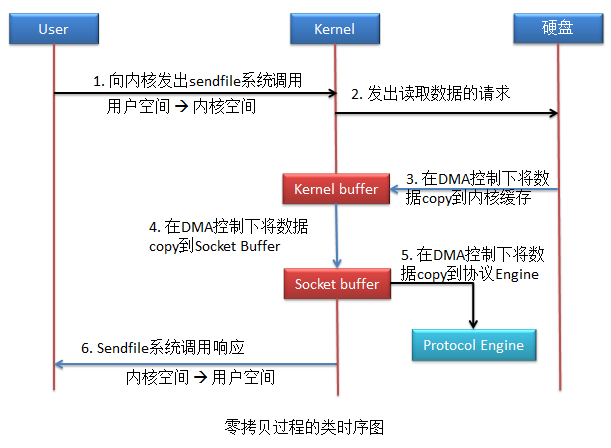
Linux系统(CentOS及以上版本)对于零拷贝是通过sendfile系统调用实现的。
这种拷贝方式共进行了2次用户空间与内核空间的上下文切换,以及3次数据拷贝,但整个拷贝过程都没有CPU的参与,这就是零拷贝。
这里也还有一个问题,kernel buffer到socket buffer的拷贝其实是不需要的,因为DMA控制器所控制的拷贝过程有一个要求,数据在源头的存放地址空间必须是连续的,kerbel buffer中的数据无法保障其连续性,所以需要将数据再拷贝到socket buffer,socket buffer可以保证了数据的连续性。
如果要避免从kernel buffer与socket buffer之间的拷贝,只要主机的DMA支持Gather Copy功能,就可以避免。
3、Gather Copy DMA零拷贝方式
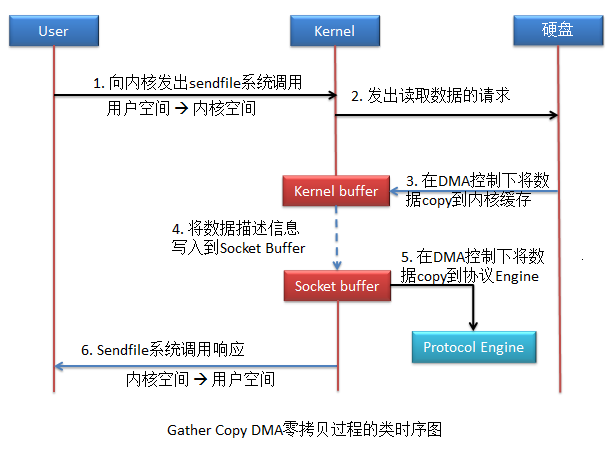
由于该拷贝方式是由DMA完成,与系统无关,所以只要保证系统支持sendfile系统调用功能即可。
该方式中没有数据拷贝到socket buffer,取而代之的是只是将kernel buffer中的数据描述信息写到socket buffer中,数据描述信息包含了两方面的信息:kernel buffer中数据的地址及偏移量。
该拷贝方式共进行了2次用户空间与内核空间的上下文切换,以及2次数据拷贝,并且整个拷贝过程中均没有CPU的参与。
虽然这种拷贝方式的系统侠侣提高了,但是与传统的拷贝方式对比,也存在不足,传统拷贝中use buffer中存在数据,因此应用程序能够对数据进行修改等操作;零拷贝中的user buffer中没有了数据,所以应用程序无法对数据进行操作。
Linux中的mmap零拷贝解决了该问题。
4、mmap零拷贝
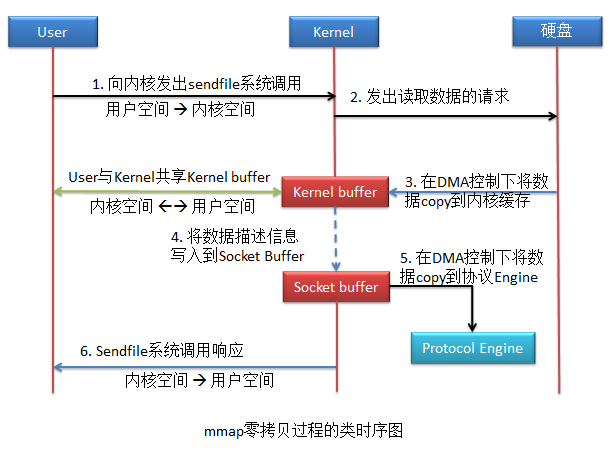
mmap零拷贝是对零拷贝的改进,当然,如果当前主机的DMA支持Gather Copy,mmap同样也可以实现Gather Copy DMA的零拷贝。
该方式与零拷贝的唯一区别是,应用程序与内核共享了Kernel buffer,由于是共享,所以应用程序也就可以操作该buffer了。当然,应用程序对于Kernel buffer的操作,就会引发用户空间与内核空间的相互转换。
该拷贝方式共进行了4次用户空间与内核空间的上下文切换,以及2次数据拷贝,并且整个拷贝过程均没有CPU参与。虽然较之前的零拷贝增加了两次上下文切换,但应用程序可以对数据进行修改了。
二、多路复用
以下两个图是多线程/多进程和多路复用的对比图:
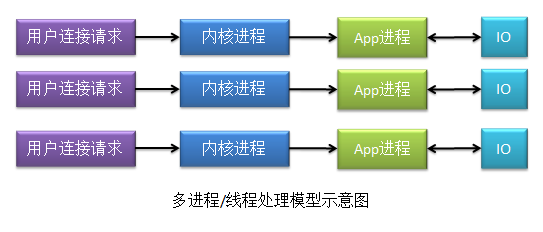

在多线程/多进程连接处理模型中,app进程只要被创建了,就会执行内核进程事务;在多路复用模型下,只有一个app进程来处理内核进程事务,且app进程一次只能处理一个内核进程事务,因此这种模型对于内核进程来说,存在对app进程的竞争。其需要通过多路复用器来获取各个内核进程的状态信息,多路复用器可以使用select、poll、epoll三种算法获取到内核进程的状态。
select:
select多路复用器是采用轮询的方式,一直在轮询所有的相关内核进程,查看他们的进程状态,若已经就绪,则马上将内核进程放入到就绪队列。否则,继续查看下一个内核进程状态。在处理内核进程事务之前,app进程首先会从内核空间中将用户连接请求相关数据复制到用户空间。
但是select算法的多路复用器有以下几个缺点:
(1)对所有内核进程采用轮询方式效率会很低,因为对于大多数情况下,内核进程都不属于就绪状态,只有少部分才会是就绪状态,所以这种轮询结果大多数都是无意义的。
(2)由于就绪队列底层是由数组实现,所以其所能处理的内核进程数量是有限制的,即其能够处理的最大并发连接数是有限的。
(3)从内核空间到用户空间的复制,系统开销大
poll:
poll多路复用器与select多路复用器几乎相同,不同的是,其就绪队列使用的是链表实现的,其对于可以处理的内核进程数理论上是没有限制的,即可以处理的最大连接数是没有限制的(其实这里会受限于当前系统中进程可以打开的最大文件描述数ulimit)。
epoll:
epoll是对select和poll的改进,即不再使用轮询的方式进行处理了,而是采用回调的方式对内核状态进行获取,一旦内核进程就绪,其就会回调epoll多路复用器,进入到多路复用器的就绪队列(由链表实现),所以epoll也被称为epoll事件驱动模型。
另外,应用程序所使用的数据,也不再从内核空间复制到用户空间了,而是使用mmap零拷贝的方式,大大降低了系统开销。
当内核进程就绪信息通知了epoll多路复用后,多路复用器马上就会对其进行处理,具体的处理方式分为LT模式和ET模式两类。
LT模式:
LT,Level Triggered,水平触发模式。即只要内核进程的就绪通知由于某种原因暂时没有 被 epoll 处理,则该内核进程就会定时将其就绪信息通知 epoll。直到 epoll 将其写入到就绪 队列,或由于某种原因该内核进程又不再就绪而不再通知。其支持两种通讯方式:BIO 与 NIO。
ET模式:
ET,Edge Triggered,边缘触发模式。其仅支持 NIO 的通讯方式。 当内核进程的就绪信息仅会通知一次 epoll,无论 epoll 是否处理该通知。明显该方式的 效率要高于 LT 模式,但其有可能会出现就绪通知被忽视的情况,即连接请求丢失的情况。
三、Nginx的并发处理机制
一般情况下并发处理机制有三种:多进程、多线程和异步机制。Nginx对于并发的处理同时采用了三种机制,当然,其异步机制使用的是异步非阻塞方式。
Nginx的进程分为两类,master进程与worker进程,每个master进程可以生成多个worker进程,所以其是多进程的。每个worker进程可以同事处理多个用户请求,每个用户请求会由一个线程来处理,所以其是多线程的。
worker进程采用的是epoll多路复用机制来对后端服务器进行处理的,当后端服务器返回结果后,后端服务器就会回调epoll多路复用器,由多路复用器对相应的worker进程进行通知,此时,worker进程就会挂起当前正在处理的事务,拿IO返回结果去响应客户端请求。响应完毕后,会再继续执行挂起的事务,这个过程就是异步非阻塞的。
四、全局模块下的调优
worker_processes 1; worker_cpu_affinity 01 10; worker_rlimit_nofile 65535;
1、worker_process
工作进程,用于指定Nginx的工作进程数量,其数值一般设置为CPU内核数量或者内核数量的整数倍。不过需要注意的是,该值不仅仅取决于CPU的内核数量,还与硬盘数量及负载均衡模式相关,在不确定时可以设置为auto。
2、worker_cpu_affinity
将worker进程与具体的内核进行绑定,但是如果worker_process设置为auto的话,worker_cpu_affinity无法进行设置。
改设置通过二进制进行,每个内核使用一个二进制位表示,0代表内核关闭,1代表内核开启,也就是说,有几个内核,就需要几个二进制位。
| 内核数量 | worker_processes工作进程数量 | worker_cpu_affinity取值 | 说明 |
| 2 | 2 | 01 10 | 每个进程各使用一个内核 |
| 2 | 4 | 01 10 01 10 | 每个进程交替使用各个内核 |
| 4 | 4 | 0001 0010 0100 1000 | 每个进程各使用一个内核 |
| 4 | 2 | 0101 1010 | 每个进程使用两个内核,对于需要CPU进行大量运算的应用,可以让每个进程使用多个CPU内核 |
3、work_rlimit_nofile
用于设置一个worker进程所能打开的最多文件数量,其默认值与当前Linux系统可以打开的最大文件描述符数量相同。
五、events模块调优
events { worker_connections 1024; accept_mutex on; accept_mutex_delay 500ms; multi_accept on; use epoll; }
1、worker_connections
每一个worker进程可以并发处理的最大连接数,该值不能超过worker_rlimit_nofile的值。
2、accept_mutex
on,默认值,表示当一个新连接到达时,那些没有处于工作状态的worker将以串行方式来处理;
off,表示当一个新连接到达时,所有的worker都会被唤醒,不过只有一个worker能获取新连接,其他的worker进入阻塞状态,这就是“惊群”现像。
3、accept_mutex_delay
设置队首worker会尝试获取互斥锁的时间间隔,默认值为500毫秒。
4、multi_accept
off,系统会逐个拿出新连接按照负载均衡策略,将其分配给当前处理连接个数最少的worker。
on,系统会实时的统计出各个worker当前正在处理的连接个数,然后会按照“缺编”最多的worker的“缺编”数量,一次性将这么多的新连接分配给该worker。
5、use epoll
设置worker与客户端连接的处理方式,Nginx会自动选择适合当前系统的最高效的方式,也可以使用use指令明确指定所要使用的连接处理方式,use的取值可以有:select | poll | epoll | rtsig | kqueue | /dev/poll
(1)select | poll | epoll
这是三种多路复用机制,select和poll工作原理几乎相同,而epoll的效率最高,是现在使用最多的一种多路复用机制。
(2)rtsig
realtime signal,实时信号,Linux2.2.19+的高效连接处理方式,但是在Linux2.6版本后,不再支持该方式。
(3)kqueue
应用在BSD系统上的epoll
(4)/dev/poll
UNIX系统上使用的poll
六、http模块调优
http { include mime.types; default_type application/octet-stream; charset utf-8; ...... sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; keepalive_requests 10000; client_body_timeout 10;
1、非调优属性
include:将当前目录(conf目录)中的指定文件(mime.types)包含进来
default_type:对于无扩展名的文件,默认其为application/octet-stream类型,即Nginx会将其作为一个八进制流文件来处理。
charset:设置请求与响应的字符编码
2、sendfile
设置为on,则开启Linux系统零拷贝机制,否则不开启零拷贝,当然,开启后是否起作用,要看所使用的系统版本,CentOS6及以上版本支持sendfile零拷贝。
3、tcp_nopush
on:以单独的数据包形式发送Nginx的响应头信息,而真正的响应体数据会再以数据包的形式发送,这个数据包中就不再包含响应头信息了。
off:默认值,响应头信息包含在每一个响应体数据包中。
4、tcp_nodelay
on:不设置数据发送缓存,即不推迟发送,适用于传输小数据,无需缓存
off:开启发送缓存,若传输的数据是图片等大数据量文件,则建议设置为off
5、keepalive_timeout
设置客户端与Nginx所建立的长连接的生命超时时间,时间到达,则连接将自动关闭
6、keepallive_requests
设置一个长连接最多可以发送的请求数,该值需要在真实环境下测试
7、client_body_timeout
设置客户端获取Nginx响应的超时时限,即一个请求从客户端发出到接收到Nginx响应的最长时间间隔,若超时,则认为本次请求失败。