CuratorFramework基本介绍
CuratorFramework是Netflix公司开源的一套Zookeeper客户端框架,它作为一款优秀的ZooKeeper客户端开源工具,主要提供了对客户端到服务的连接管理和连接重试机制,以及一些扩展功能,它解决了很多ZooKeeper客户端非常底层的细节开发工作。
主要的功能包括:连接重连、反复注册Watcher和NodeExistsException异常等,目前已经成为了Apache的顶级项目,是全世界范围内使用最广泛的ZooKeeper客户端之一,Patrick Hunt(ZooKeeper代码的核心提交者)以一句 “Guava is to Java what Curator is to ZooKeeper” (Curator对于ZooKeeper,可以说就像Guava工具集对于Java平台一样,作用巨大)对其进行了高度评价。
除此之外,Curator中还提供了ZooKeeper各种应用场景(Recipe,如共享锁服务、Master选举机制和分布式计数器等)的抽象封装。
CuratorFramework编程特点
除了封装一些开发人员不需要特别关注的底层细节之外,Curator还在ZooKeeper原生API的基础上进行了包装,提供了一套易用性和可读性更强的Fluent风格的客户端API框架。
CuratorFramework项目组件
- Recipes:Zookeeper典型应用场景的实现,这些实现是基于Curator Framework。
- Framework:Zookeeper API的高层封装,简化Zookeeper客户端编程,添加了例如Zookeeper连接管理、重试机制等。
- Utilities:为Zookeeper提供的各种实用程序。
- Client:Zookeeper client的封装,用于取代原生的Zookeeper客户端(ZooKeeper类),提供一些非常有用的客户端特性。
- Errors:Curator如何处理错误,连接问题,可恢复的例外等。
官方资源
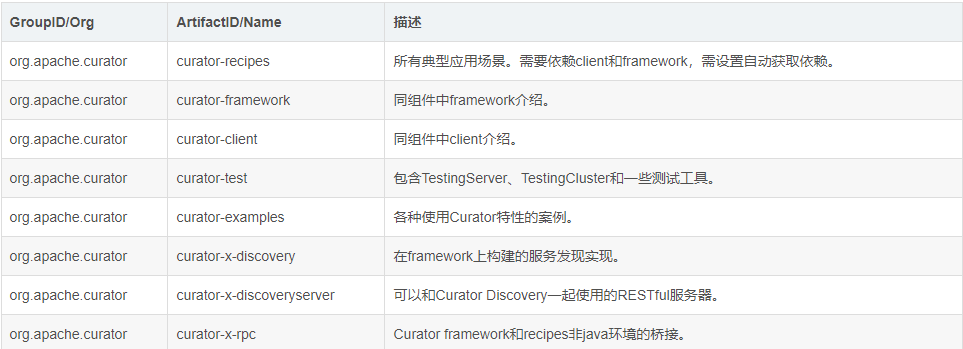
Maven依赖说明
由以下几个artifact的组成,但大多数情况下只用引入curator-recipes即可。
CuratorFramework简单使用
CuratorFramework的jar包在Maven仓库中心是可以找到 ,使用Maven,Gradle,Ant等可以很轻松简单的将Curator包含到项目当中。
很多用户会想要使用Curtor预编译的一些工具,所以Curator提供了curator-recipes,如果你仅仅想使用Zooeeper的简单包装,包括链接管理和重试机制,那么使用curator-framework就足够了。
Maven依赖配置
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
创建会话
使用CuratorFrameworkFactory这个工厂类的两个静态方法来创建一个客户端:
static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy);
static CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy);
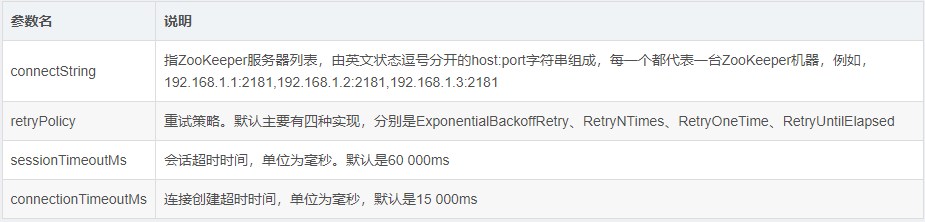
构造方法中的各参数
-
connectString:zk的server地址,多个server之间使用英文逗号分隔开
-
connectionTimeoutMs:连接超时时间,如上是30s,默认是15s
-
sessionTimeoutMs:会话超时时间,如上是50s,默认是60s
-
retryPolicy:失败重试策略
Session会话超时
该方法配置重连retryPolicy以及回话有效时间sessionTimeoutMs,重连就是当客户端与zookeeper 连接异常的时候,如网络波动,断开链接,支持重新连接,会话有效这个与节点的属性有关。那么zookeeper 有哪些节点属性。
重试策略
CuratorFramework通过一个接口RetryPolicy来让用户实现自定义的重试策略。在RetryPolicy来让用户实现自定义的重试策略。在RetryPolicy接口中定义了一个方法:
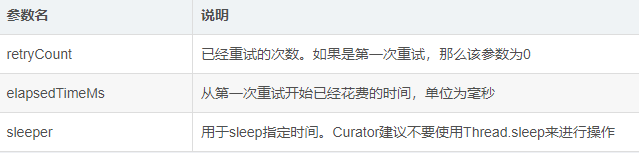
boolean allowRetry(int retryCount, long elapsedTimeMs, RetrySleeper sleeper)
RetryPolicy接口参数
默认提供了以下实现,分别为ExponentialBackoffRetry、BoundedExponentialBackoffRetry、RetryForever、RetryNTimes、RetryOneTime、RetryUntilElapsed。
通过调用CuratorFramework中的start()方法来启动会话。
获取Zookeeper连接会话
Curator链接实例(CuratorFramework)由CuratorFrameworkFactory获取,对于一个Zk集群,仅仅需要一个CuratorFramework实例:
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3);
CuratorFramework Client = CuratorFrameworkFactory.builder()
.connectString("ip:2181,ip2:2181,ip3:2181")
.sessionTimeoutMs(3000)
.connectionTimeoutMs(5000)
.retryPolicy(retryPolicy)
.build();
client.start();
client.blockUntilConnected();
这将会使用默认的值创建一个到ZK集群的链接,唯一需要特别指定单参数是重试机制,从例子上看,你需要使用:
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);
CuratorFramework client = CuratorFrameworkFactory.newClient(zookeeperConnectionString, retryPolicy);
client.start();
获得到的CuratorFramework实例在使用之前需要调用其start方法,在不许要使用的时候需要调用close方法。
在上面这个示例程序中,我们首先创建了一个名为ExponentialBackoffRetry的重试策略,该重试策略是Curator默认提供的几种重试策略之一,其构造方法如下:
ExponentialBackOffRetry(int baseSleepTimeMs, int maxRetries);
ExponentialBackOffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs);
ExponentialBackoffRetry构造方法参数:
构造器含有三个参数 ExponentialBackoffRetry(int baseSleepTimeMs, int maxRetries, int maxSleepMs)

-
baseSleepTimeMs:初始的sleep时间,用于计算之后的每次重试的sleep时间,计算公式:当前sleep时间=baseSleepTimeMs*Math.max(1, random.nextInt(1<<(retryCount+1)))
-
maxRetries:最大重试次数
-
maxSleepMs:最大sleep时间,如果上述的当前sleep计算出来比这个大,那么sleep用这个时间
org.apache.curator.RetryPolicy接口
-
start() 开始创建会话。
-
blockUntilConnected() 直到连接成功或超时。
ExponentialBackoffRetry的重试策略
给定一个初始sleep时间baseSleepTimeMs,在这个基础上结合重试次数,通过以下公式计算出当前需要sleep的时间:
当前sleep时间 = baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1)))
随着重试次数的增加,计算出的sleep时间会越来越大。如果该sleep时间在maxSleepMs的范围之内,那么就使用该sleep时间,否则使用maxSleepMs。另外,maxRetries参数控制了最大重试次数,以避免无限制的重试。
CuratorFrameworkFactory工厂在创建出一个客户端CuratorFramework实例之后,实质上并没有完成会话的创建,而是需要调用CuratorFramework的start()方法来完成会话的创建。
创建一个初始内容为空的节点
一旦你拥有了CuratorFramework实例,你可以直接调用Zookeeper,这类似ZK发布版本中提供的原生的ZooKeeper对象,
client.create().forPath(path);
创建一个包含内容的节点
client.create().forPath(path,"数据欸日".getBytes());
创建临时节点,并递归创建父节点
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path);
此处Curator和ZkClient一样封装了递归创建父节点的方法。在递归创建父节点时,父节点为持久节点。
client.create().forPath("/my/path", myData)
删除节点
删除一个子节点
client.delete().forPath(path);
删除节点并递归删除其子节点
client.delete().deletingChildrenIfNeeded().forPath(path);
指定版本进行删除
client.delete().withVersion(1).forPath(path);
//如果版本不存在,则删除异常,信息如下:
org.apache.zookeeper.KeeperException$BadVersionException: KeeperErrorCode = BadVersion for
强制保证删除一个节点
client.delete().guaranteed().forPath(path);
读取数据
读取节点数据内容API相当简单,Curator提供了传入一个Stat,使用节点当前的Stat替换到传入的Stat的方法,查询方法执行完成之后,Stat引用已经执行当前最新的节点Stat。
普通查询
client.getData().forPath(path);
包含状态查询
Stat stat = new Stat();
client.getData().storingStatIn(stat()).forPath(path);
更新数据
更新数据,如果未传入version参数,那么更新当前最新版本,如果传入version则更新指定version,如果version已经变更,则抛出异常。
普通更新
client.setData().forPath(path,"新内容".getBytes());
指定版本更新
client.setData().withVersion(1).forPath(path);
更新出错,版本不一致异常:
org.apache.zookeeper.KeeperException$BadVersionException: KeeperErrorCode = BadVersion for
异步接口
在使用以上针对节点的操作API时,我们会发现每个接口都有一个inBackground()方法可供调用。此接口就是Curator提供的异步调用入口。对应的异步处理接口为BackgroundCallback。此接口指提供了一个processResult的方法,用来处理回调结果。其中processResult的参数event中的getType()包含了各种事件类型,getResultCode()包含了各种响应码。
重点说一下inBackground的以下接口:
public T inBackground(BackgroundCallback callback, Executor executor);
//此接口就允许传入一个Executor实例,用一个专门线程池来处理返回结果之后的业务逻辑。
/**
* 异步创建节点
*
* 注意:如果自己指定了线程池,那么相应的操作就会在线程池中执行,如果没有指定,
* 那么就会使用Zookeeper的EventThread线程对事件进行串行处理
* */
client.create().withMode(CreateMode.EPHEMERAL).inBackground(new BackgroundCallback() {
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("当前线程:" + Thread.currentThread().getName() + ",code:"
+ event.getResultCode() + ",type:" + event.getType());
}
}, Executors.newFixedThreadPool(10)).forPath("/async-node01");
client.create().withMode(CreateMode.EPHEMERAL).inBackground(new BackgroundCallback() {
public void processResult(CuratorFramework client, CuratorEvent event) throws Exception {
System.out.println("当前线程:" + Thread.currentThread().getName() + ",code:"
+ event.getResultCode() + ",type:" + event.getType());
}
}).forPath("/async-node02");
创建含隔离命名空间的会话
使用Curator的好处是Curator帮助我们管理客户端到ZK的链接,并且在出现网络链接的问题的时候将会执行指定的重试机制。为了实现不同的ZooKeeper业务之间的隔离,往往会为每个业务分配一个独立的命名空间,即指定一个ZooKeeper根路径。
下面所示的代码片段中定义了某一个客户端的独立命名空间为/base,那么该客户端对ZooKeeper上数据节点的任何操作,都是基于该相对目录进行的:
CuratorFrameworkFactory.builder().connectString("domain1.book.zookeeper:2181")
.sessionTimeoutMs(5000).retryPolicy(retryPolicy).namespace("base").build();