目录
6.regexp (了解)可以使用正则表达式查询数据 (不推荐,效率不高)
part1:单表查询
SQL查询语句的完整语法: select .. from .. where .. group by .. having .. order by .. limit ..
1.where条件的使用
功能: 对表中的数据进行过滤筛选
1.判断的符号
= > >= < <= != <> 不等于
2.拼接关键字
and or not
3.查询范围区间 between
between 小值 and 大值 [小值,大值] 查询两者之间的这个范围所有数据
4.查询某个值在具体某个范围里 in
in(1,2,3,4)
5.模糊查询 like "%" "_" 通配符
like "%a" 匹配以a结尾的任意长度的字符串
like "a%" 匹配以a开头的任意长度的字符串
like "%a%" 匹配含有a字母的任意长度的字符串
like "_a" 个数一共是2个字符,必须以a结尾,前面字符随意
like "a__" 个数一共是3个字符,必须以a开头,后面字符随意
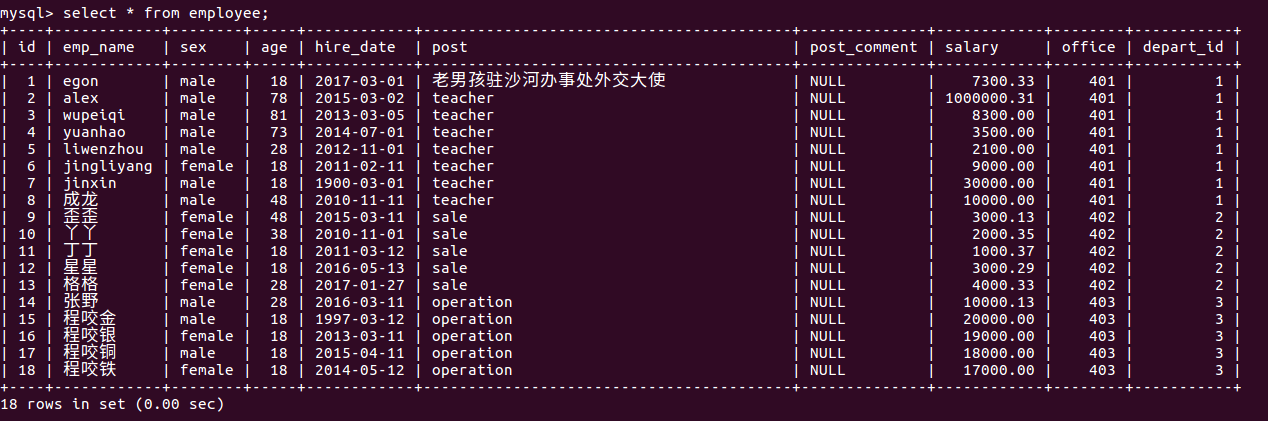
创建employee并插入数据
#创建表 create table employee( id int not null unique auto_increment, emp_name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); #三个部门:教学,销售,运营 insert into employee(emp_name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ;
# (1) 单条件的查询 # 查询部门是sale 的所有员工姓名 select emp_name from employee where post = "sale"; # (2) 多条件的查询 # 部门是teacher , 收入大于10000的所有数据 select * from employee where post="teacher" and salary > 10000; # (3) between .. and .. # 收入在1万~2万之间的所有员工姓名和收入 select emp_name,salary from employee where salary between 10000 and 20000; # 收入不在1万~2万之间的所有员工姓名和收入 select emp_name,salary from employee where salary not between 10000 and 20000; # (4) null 关键字 在查询时候,需要使用is进行判断 ,不能用= select * from employee where post_comment = null; select * from employee where post_comment = ''; select * from employee where post_comment is null; select * from employee where post_comment is not null; # (5) in 在 ... 之中 # 查询收入是 3000 ,4000,5000 ,8300所有原型的姓名和收入 select emp_name,salary from employee where salary in (3000,4000,5000,8300) # (推荐) select emp_name,salary from employee where salary = 3000 or salary=4000 or salary=5000 or salary=8300; # not .. in .. select emp_name,salary from employee where salary not in (3000,4000,5000,8300); # (6) 模糊查询 like "%" "_" # (1) 匹配员工姓名 以on结尾的. "%" 通配符 select emp_name from employee where emp_name like "%on"; # (2) "_"通配符 限定字符长度使用_ select emp_name from employee where emp_name like "a_e_"; # (7) concat (as 起别名) select concat("姓名:",emp_name,"工资:",salary) as ceshi from employee; # concat_ws(拼接的符号, 参数1,参数2,参数3 .. .. ) select concat_ws(" : " , emp_name , salary) as ceshi from employee; # 计算每个人的年薪 可以在mysql使用四则运算(+ - * / ) select concat_ws(" : " , emp_name, salary * 12) as ceshi200 from employee;
employee表详情如下所示
2.group 子句 分组分类
group by 字段 对当前字段进行分类 , by后面接什么字段,select 就搜什么字段
"""group by 字段 对当前字段进行分类 , by后面接什么字段,select 就搜什么字段""" select sex from employee group by sex; select post from employee group by post; # group_concat 按照分类的形式进行字段的拼接 select group_concat(emp_name) from employee group by post; # 聚合函数 # count 统计总数 *所有 select count(*) from employee; # max 统计最大值 select max(salary) from employee; # min 统计最小值 select min(salary) from employee; # avg 统计平均值 select avg(salary) from employee; # sum 统计总和 select sum(salary) from employee; # 1. 查询部门名以及各部门的平均薪资 聚合函数 + 分组 配合使用 select post,avg(salary) from employee group by post # 2. 查询部门名以及各部门的最高薪资 select post,max(salary) from employee group by post # 3. 查询部门名以及各部门的最低薪资 select post,min(salary) from employee group by post # 4. 查询公司内男员工和女员工的个数 select sex, count(*) from employee group by sex # 5. 查询部门名以及部门包含的所有员工名字 select post,group_concat(emp_name) from employee group by post # 可以group by 两个字段,搜索2个字段 select post , emp_name from employee group by post , emp_name
3.having 数据在分类分组之后,进行二次数据过滤,一般是配合group by 使用,分组之后过滤
# 找平均薪资大于10000以上的所有部门 select post,avg(salary) from employee group by post having avg(salary) > 10000 # 1.查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数 select post , group_concat(emp_name) , count(*) from employee group by post having count(*) < 2 ; # 2.查询各岗位平均薪资小于10000的岗位名、平均工资 select post,avg(salary) from employee group by post having avg(salary) < 10000; # 3.查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资 select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) < 20000;
4.order by 排序, 按照什么字段进行排序
asc 升序: 从小到大 (默认)
desc 降序: 从大到小
select * from employee order by age #(默认是asc升序) select * from employee order by age desc #(默认是desc 倒序) # 1. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序 select * from employee order by age , hire_date desc; # 2. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列 select post, avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) # 3. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列 select post, avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc
5.limit 限制查询条数 (数据分页)
limit m,n m代表从第几条数据进行查询,0代表第一条,n代表的查询几条
select * from employee limit 0,5 # 从第一条数据开始搜, 搜5条数据 select * from employee limit 5,5 # 从第六条数据开始搜, 搜5条数据 # 只搜索一条数据 select * from employee limit 1 # 只搜索3条数据 select * from employee limit 3 # 搜索这个表中最后一条数据 select * from employee order by id desc limit 1
6.regexp (了解)可以使用正则表达式查询数据 (不推荐,效率不高)
select * from employee where emp_name regexp ".*on$"; # .*? 这个?号 mysql 不识别 select * from employee where emp_name regexp "程"; select * from employee where emp_name regexp "程.*金";
part2:多表查询
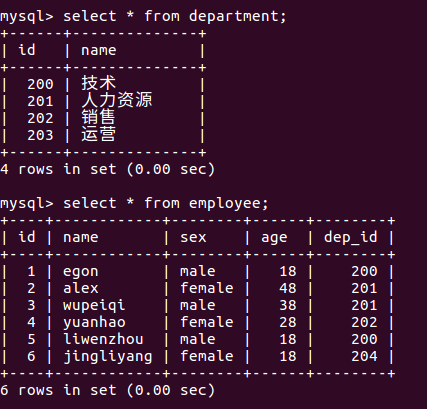
创建employee表和department表,并插入数据
#建表 create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into department values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into employee(name,sex,age,dep_id) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('liwenzhou','male',18,200), ('jingliyang','female',18,204) ;
dapartment表和employee表详情如图所示
1.内连接 inner join
内连接 : (inner join ) -> 两表或者多表满足条件的所有数据查询出来(两表之间的共有数据)
两表查询
select 字段 from 表1 inner join 表2 on 必要的关联条件
多表查询
select 字段 from 表1 inner join 表2 on 必要的关联条件1 inner join 表3 on 必要的关联条件2 ...
# 基本语法 inner join on + 条件 select * from employee inner join department on employee.dep_id = department.id; # 用as 起别名(推荐) select * from employee as e inner join department as d on e.dep_id = d.id; # as 可以省略 select * from employee e inner join department d on e.dep_id = d.id; # where 默认实现的就是内联查询的效果 select * from employee , department where employee.dep_id = department.id; select * from employee as e , department as d where e.dep_id = d.id;
2.外连接
1.左连接(左联查询 left join ) 以左表为主,右表为辅,完整查询左表所有数据,右表没有的补null
2.右连接(右联查询 right join ) 以右表为主,左表为辅,完整查询右表所有数据,左表没有的补null
3.全连接 union
# 1.左连接(左联查询 left join ) 以左表为主,右表为辅,完整查询左表所有数据,右表没有的补null select * from employee left join department on employee.dep_id = department.id; # 2.右连接(右联查询 right join ) 以右表为主,左表为辅,完整查询右表所有数据,左表没有的补null select * from employee right join department on employee.dep_id = department.id; # 3.全连接 select * from employee left join department on employee.dep_id = department.id union select * from employee right join department on employee.dep_id = department.id
part3:子查询
子查询: 嵌套查询
1.sql语句当中又嵌套了另外一条sql语句,用()括号抱起来,表达一个整体
2.一般应用在from 字符后面(表达一张表),where 子句后面(表达一个条件)
3.查询速度从快到慢 : 单表查询 -> 联表速度 -> 子查询
1.找出平均年龄大于25岁以上的部门
# (1) 普通where select d.id,d.name from employee as e,department as d where e.dep_id = d.id group by d.id,d.name having avg(e.age) > 25; # (2) inner join select d.id,d.name from employee as e inner join department as d on e.dep_id = d.id group by d.id,d.name having avg(e.age) > 25; # (3)子查询 # 1.先选出平均年龄大于25岁的部门id select dep_id from employee group by dep_id having avg(age) > 25; # 201 202 # 2.通过部门id,找部门的名字 select name from department where id in (201,202); # 3.综合拼接 select id,name from department where id in (select dep_id from employee group by dep_id having avg(age) > 25);
2.查看技术部门员工姓名
# (1) 普通where select e.name,d.name from employee as e , department as d where e.dep_id = d.id and d.name = "技术" # (2) inner join 写法 select e.name,d.name from employee as e inner join department as d on e.dep_id = d.id where # 非必要条件写在where字句中 d.name = "技术" # (3) 子查询 # 1.找计数部门对应的id select id from department where name ="技术" # 2.通过id找员工姓名 select name from employee where dep_id = 200; # 3.综合拼接 select name,dep_id from employee where dep_id = (select id from department where name ="技术");
3.查看哪个部门没员工
# 联表差生null值,谁是null谁就没员工 select d.id,d.name from department as d left join employee as e on e.dep_id = d.id where e.id is null # 1.查询员工都在哪些部门 (200 , 201 202 204) select dep_id from employee group by dep_id # 2.把不在这些部门的数据找出来 select id from department where id not in (200,201,202,204) # 3.综合拼接 select id,name from department where id not in (select dep_id from employee group by dep_id );
4.查询大于平均年龄的员工名与年龄
# 如果平均年龄是25; select name,age from employee where age > 25 # 计算平均年龄 select avg(age) from employee # 综合拼接 select name,age from employee where age > (select avg(age) from employee);
5.把大于其本部门平均年龄的员工名和姓名查出来
# 1.先计算各部门平均年龄是多少 select dep_id,avg(age) as avg_age from employee group by dep_id # 2.把查询各部门的平均年龄和过去employee做联表,变成更大的表方便后期做单表查询; select * from employee as t1 inner join (1号数据) as t2 on t1.dep_id = t2.dep_id # 3.综合拼接 select * from employee as t1 inner join (select dep_id,avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id # 4.做最后的条件帅选 select * from employee as t1 inner join (select dep_id,avg(age) as avg_age from employee group by dep_id) as t2 on t1.dep_id = t2.dep_id where t1.age > t2.avg_age
6.查询每个部门最新入职的那位员工 --->利用上一套数据表进行查询
# 1.找每个部门最大的入职时间 select post , max(hire_date) as max_date from employee group by post; # 2.把子查询搜索出来的数据和 employee 联合成一张更大的表,做一次单表查询 select * from employee as t1 inner join (1号查询出来的数据) as t2 on t1.post = t2.post where t1.hire_date = t2.max_date # 综合拼接 select t1.emp_name,t1.hire_date from employee as t1 inner join (select post , max(hire_date) as max_date from employee group by post) as t2 on t1.post = t2.post where t1.hire_date = t2.max_date
7.带EXISTS关键字的子查询
EXISTS 关键字,表达存在
如果内层sql 能够查询到数据,返回True ,外层sql执行查询语句
如果内层sql 不能够查询到数据,返回False ,外层sql不执行查询语句
select * from employee where exists ( select * from employee where id = 100);
8.关于子查询的总结
子查询总结:
子查询可以单独作为一个临时数据表,临时数据,临时字段
一般用在 from where select 子句后面
可以通过查询出来的临时数据和另外的表做一次联表,变成更大的表,然后做单表查询,以得到想要的结果.
9.distinct去重
# 额外 distinct 去重[尝试操作] select distinct depart_id from employee;