一、Hbase简介
- Hbase具有高可靠,高性能,面向列,可伸缩的特点。
- Hbase作为分布式数据库,可以用来存储非结构化和半结构化的松散数据。
- Hbase是一个稀疏的多维度的排序的映射表。
- Hbase通过行键,列族,列限定符,列时间戳来定义一个数据。
- Hbase每一个值都是未经解释的字符串也就是Bytes数组。
- Hbase一个行有一个行键和任意多个列。
- Hbase属于列式存储。
二、Hbase功能组件
- 库函数:一般用于键接每个客户端。
- Master服务器:分区信息进行维护和管理;维护了一个Region服务器列表;整个集群中有哪些Region服务器在工作;负责对Region进行分配;负载均衡。
- Region服务器:负责存储不同的Region。
三、Hbase设计了三层结构实现Region的寻址和定位
- 首先要构建一个元数据表,假设这个元数据表只有两列,第一列是Region的id,第二列是Region服务器的id。
- Hbase最开始构建时有一个映射表,这个映射表被称为.META表,.META表是用于存储元数据的。
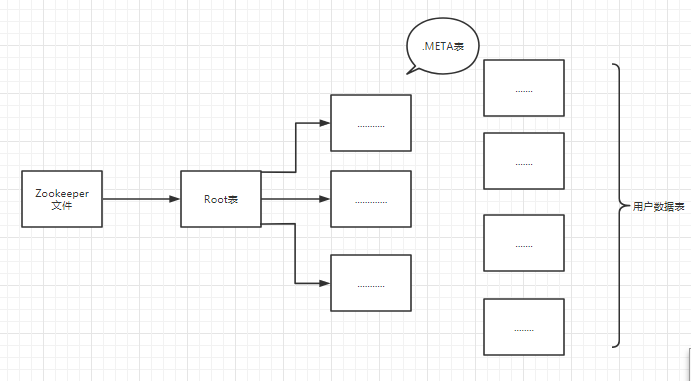
- 为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题,如何解决呢?先去寻找缓存,如果找不到,则判定失效→三层寻址。
四、用户读写数据
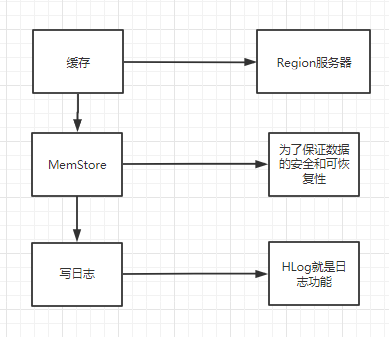
- 用户写入数据
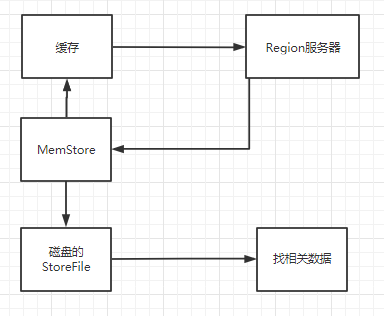
2.用户读取数据
五、缓存的刷新
- 系统会周期性的把MemStore缓存里的内容刷写到磁盘的StoreFile文件中,清空缓存,并在HLog里面写入一个标记。
- 每次刷新都生成一个新的StoreFile文件,因此,每个Store包含多个StoreFile文件。
- 每个Region服务器都有一个自己的HLog文件,每次启动都检查该文件,确认最近一次执行缓存刷新操作之后是否发生新的写入操作,如果发现更新,则先写入到MemStore,再刷写到StoreFile,最后删除旧的HLog文件,开始为用户提供服务。
六、Hbase性能优化方法
- 时间靠近的数据都存在一起→时间戳:a.按升序排序;b.越到后时间戳会越来越大;c.长整型变量64位。Long.MAX_VALUE_timestamp作为行键,用系统最大的整数值减去时间戳→排序就反过来了从而改变了排序的顺序。
- 提升读写性能:设置HColumnDescriptor.setInMemory选项为true→放入缓存中去。
- 设置HColumnDescriptor.setMaxVersionsMaxVersions,设置最大版本数。
- 设置TimeToLive参数,生命周期。
七、Hbase性能检测
- Master-status
- Ganglia
- OpenTSDB
- Ambari
八、Hbase使用SQL
- Hive
- Phoenix
九、Hbase利用Coprocessor特性去构建二级索引,Coprocessor提供了两个实现:
- endpoint:相当于存储过程。
- observer:相当于触发器。