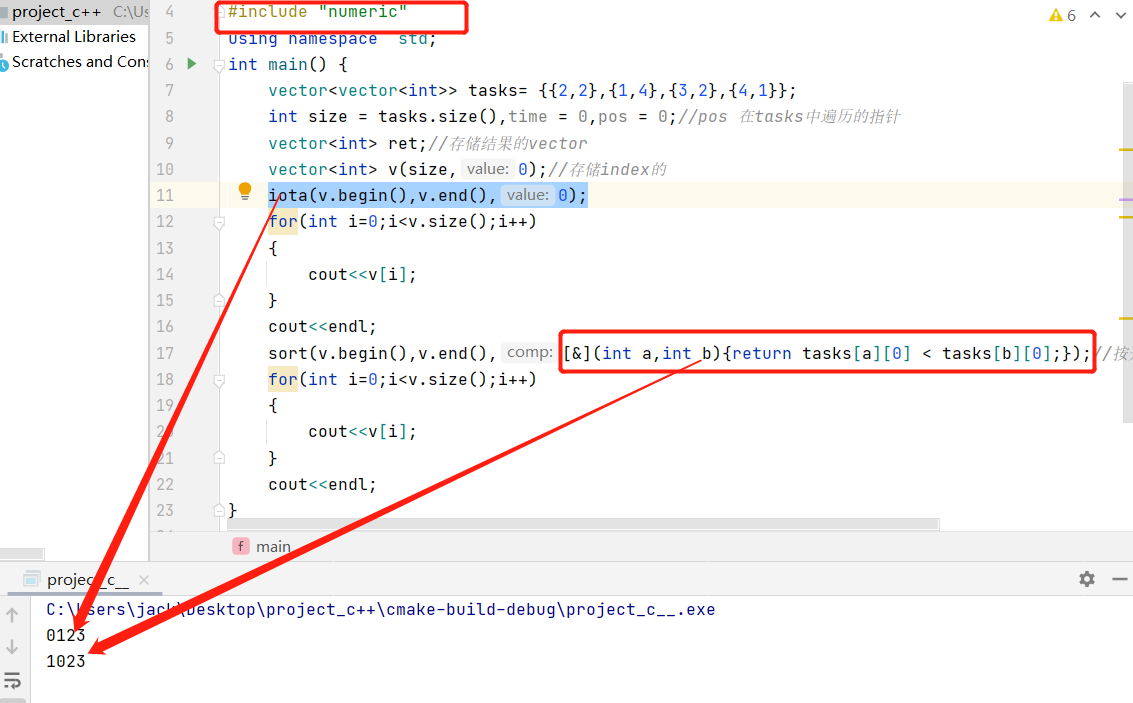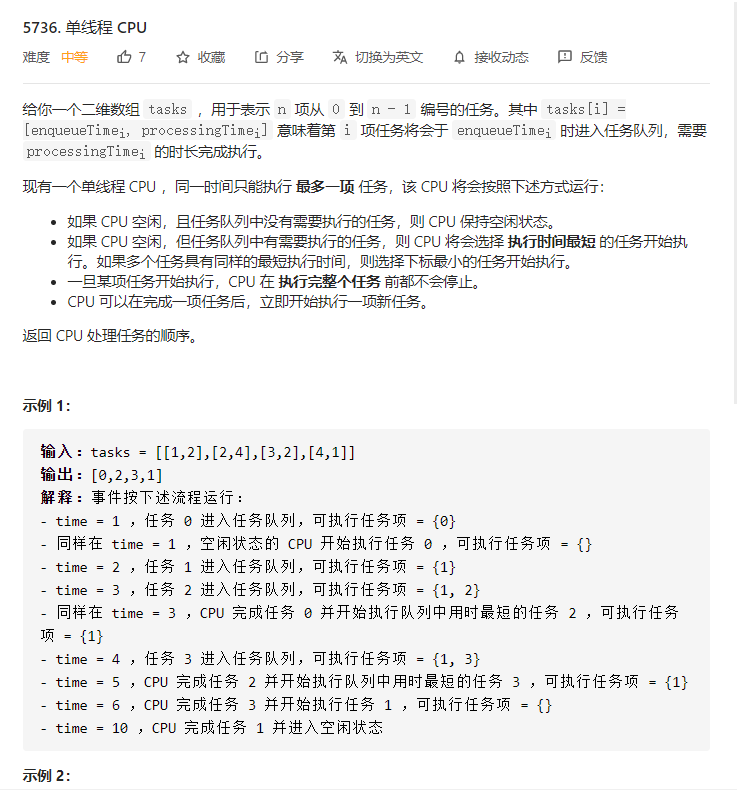
通过这个题熟悉了下iota的用法,vector自定义排序(根据另一个数组来排当前的数组) 优先队列对pair数据的处理方式,很好的一道题
1 class Solution { 2 public: 3 using PII = pair<int,int>;//type def 4 5 vector<int> getOrder(vector<vector<int>>& tasks) { 6 int size = tasks.size(),time = 0,pos = 0;//pos 对tasks按照开始执行时间排序,保存其index,pos对index数组遍历,然后从tasks中依次取出元素 7 vector<int> ret;//存储结果的vector 8 vector<int> v(size,0);//存储index的 9 iota(v.begin(),v.end(),0);//1,2,3,4...size 10 sort(v.begin(),v.end(),[&](int a,int b){return tasks[a][0] < tasks[b][0];});//按开始执行时间排序index 11 priority_queue<PII,vector<PII>,greater<PII>> q;//最小堆 12 13 while(pos<size) 14 { 15 if(q.empty())//队列为空 在当前时间点内无任务到达 就直接去跳到下一个任务 16 time = max(tasks[v[pos]][0],time); 17 while(pos<=size-1 && time >= tasks[v[pos]][0]) 18 q.emplace(tasks[v[pos]][1],v[pos++]);//入堆 19 //对于pair,堆会先比较第一个元素,再比较第二个元素,既满足了执行时间短的先执行也满足了时间相等时下标小的先执行 20 time += q.top().first; 21 ret.emplace_back(q.top().second);//存结果 22 q.pop(); 23 //if(ret.size() == size) break;//也可以等到全入堆后就break,然后依次pop 24 } 25 while(!q.empty()) 26 { 27 ret.emplace_back(q.top().second); 28 q.pop(); 29 } 30 return ret; 31 } 32 };
自定义函数也可以不用那么sao:还是常规写法看着舒服点
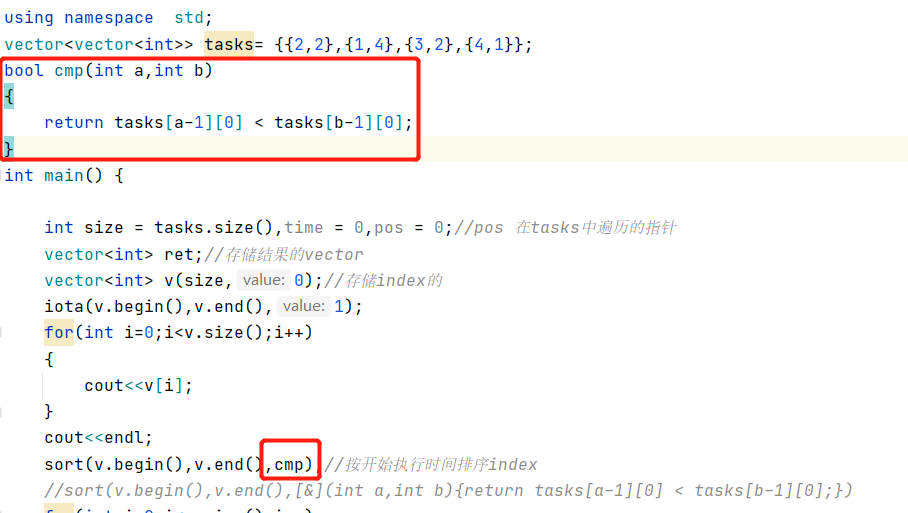
iota的用法