1.前言
上接 YFCC 100M数据集分析笔记 和 使用百度地图api可视化聚类结果, 在对 YFCC 100M 聚类出的景点信息的基础上,使用 Spark MLlib 提供的 ALS 算法构建推荐模型。
本节代码可见:https://github.com/libaoquan95/TRS/tree/master/Analyse/recommend
数据信息:https://github.com/libaoquan95/TRS/tree/master/Analyse/dataset
2.数据预处理
在用户数据(user.csv) 和 用户-景点数据(user-attraction.csv) 中,用户标识和景点标识都使用了字符串进行表示,但在 Spark MLlib 提供的 ALS 算法中,要求这两者是整数类型,所以首先要对数据进行预处理,将其转化为整数。
对于 userName, 联立 user.csv 和 user-attraction.csv,将 user-attraction.csv 中的 userName 转化为 userId 即可。
对于 provinceId, 可以考虑将其编码,provinceId 格式为 省份标识_省内景点编号,如 HK_100 标识使用在香港拍摄的照片聚类出的第 100 个景点。
编码方式很简单,首先将 _ 前的省份标识转化为数字,之后与 _ 后的数字连接即可。
编码与解码代码如下:
val provinceToCode = Map(
"LN" -> "10",
"ShanX" -> "11",
"ZJ" -> "12",
"CQ" -> "13",
"HLJ" -> "14",
"AH" -> "15",
"SanX" -> "16",
"SD" -> "17",
"SH" -> "18",
"XJ" -> "19",
"HuN" -> "20",
"GS" -> "21",
"HeN" -> "22",
"BJ" -> "23",
"NMG" -> "24",
"YN" -> "25",
"JX" -> "26",
"HuB" -> "27",
"JL" -> "28",
"NX" -> "29",
"TJ" -> "30",
"FJ" -> "31",
"SC" -> "32",
"TW" -> "33",
"GX" -> "34",
"GD" -> "35",
"HeB" -> "36",
"HaiN" -> "37",
"Macro" -> "38",
"XZ" -> "39",
"GZ" -> "40",
"JS" -> "41",
"QH" -> "42",
"HK" -> "43"
)
val codeToProvince = Map(
"10" -> "LN",
"11" -> "ShanX",
"12" -> "ZJ",
"13" -> "CQ",
"14" -> "HLJ",
"15" -> "AH",
"16" -> "SanX",
"17" -> "SD",
"18" -> "SH",
"19" -> "XJ",
"20" -> "HuN",
"21" -> "GS",
"22" -> "HeN",
"23" -> "BJ",
"24" -> "NMG",
"25" -> "YN",
"26" -> "JX",
"27" -> "HuB",
"28" -> "JL",
"29" -> "NX",
"30" -> "TJ",
"31" -> "FJ",
"32" -> "SC",
"33" -> "TW",
"34" -> "GX",
"35" -> "GD",
"36" -> "HeB",
"37" -> "HaiN",
"38" -> "Macro",
"39" -> "XZ",
"40" -> "GZ",
"41" -> "JS",
"42" -> "QH",
"43" -> "HK"
)
// 编码
def codeing(str: String): String = {
var code: String = ""
val Array(province, index) = str.split('_')
code = provinceToCode(province) + index
code
}
// 解码
def decodeing(str: String): String = {
var decode: String = ""
decode = codeToProvince(str(0).toString+str(1).toString) + "_"
for (i <- 1 to str.length-1){
decode += str(i).toString
}
decode
}

之后加载用户数据 user.scv,并去除头标题。
val dataDirBase = "..\dataset\"
val userIdToName = sc.read.
textFile(dataDirBase + "user.csv").
flatMap{ line =>
var Array(userId, userName) = line.split(',')
if(userId == "userId"){
None
} else {
Some((userId, userName))
}
}.collect().toMap
val userNameToId = sc.read.
textFile(dataDirBase + "user.csv").
flatMap{ line =>
var Array(userId, userName) = line.split(',')
if(userId == "userId"){
None
} else {
Some((userName, userId))
}
}.collect().toMap
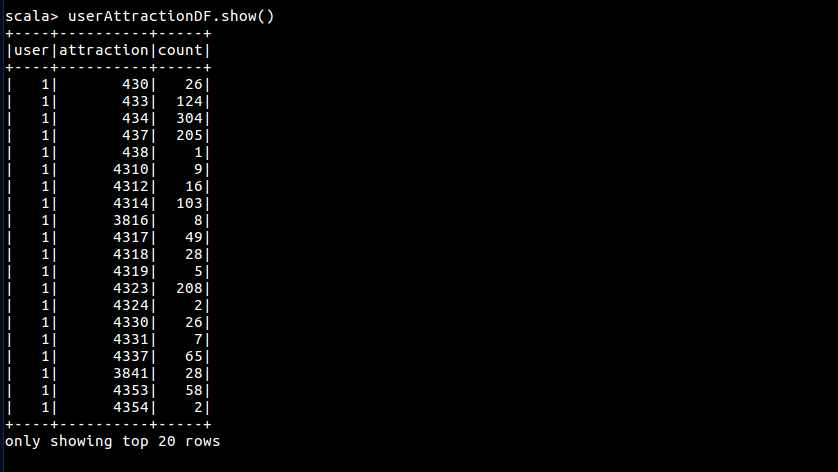
转化 user-attraction 数据
val userAttractionDF = sc.read.
textFile(dataDirBase + "user-attraction.csv").
flatMap{ line =>
val Array(userName, attractionId, count, rating) = line.split(',')
if (userName == "userName"){
None
} else {
Some((userNameToId(userName).toInt, codeing(attractionId).toInt, count.toInt))
}
}.toDF("user", "attraction", "count").cache()
3.建立推荐模型
Spark MLlib ALS 算法接受 三元组矩阵数据,分别代表 用户标识,景点标识,评分数据,其中 用户标识,景点标识 必须是整数。
ALS 是 最小交替二乘 的简称,是使用矩阵分解算法来填补稀疏矩阵,预测评分,具体参见矩阵分解在协同过滤推荐算法中的应用
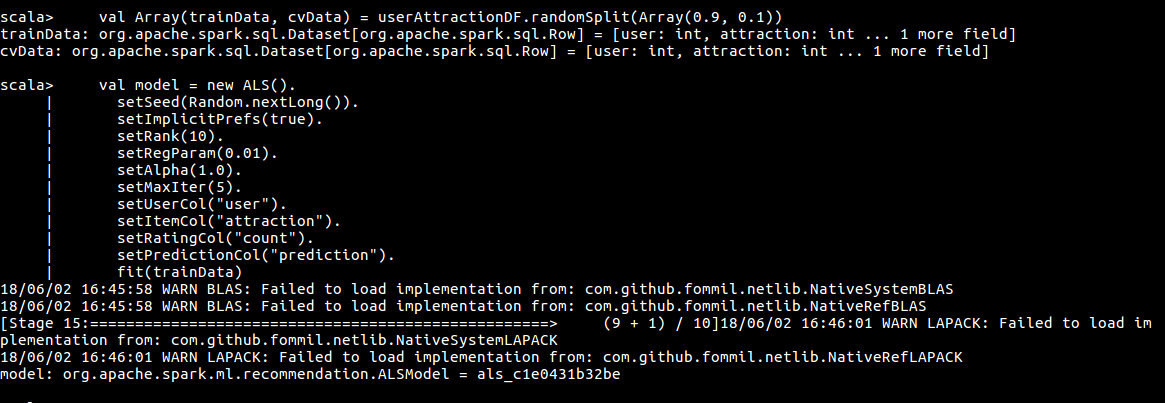
经历过上面的步骤后,userAttractionDF 已经转化为适应 ALS 算法的数据。之后可以建立推荐模型了,将数据拆分为训练集和测试集,使用训练集训练模型。具体算法如下:
val Array(trainData, cvData) = userAttractionDF.randomSplit(Array(0.9, 0.1))
val model = new ALS().
setSeed(Random.nextLong()).
setImplicitPrefs(true).
setRank(10).
setRegParam(0.01).
setAlpha(1.0).
setMaxIter(5).
setUserCol("user").
setItemCol("attraction").
setRatingCol("count").
setPredictionCol("prediction").
fit(trainData)
4.进行推荐
Spark MLlib ALS 一次只能对一个用户进行推荐,代码如下:
def recommendByUser(userId: Int, topN: Int): Array[String] = {
val toRecommend = model.itemFactors.
select($"id".as("attraction")).
withColumn("user", lit(userId))
val topRecommendations = model.transform(toRecommend).
select("attraction", "prediction").
orderBy($"prediction".desc).
limit(topN)
val recommends = topRecommendations.select("attraction").as[Int].collect()
recommends.map(line => decodeing(line.toString))
}
推荐效果如下:

5.评测系统
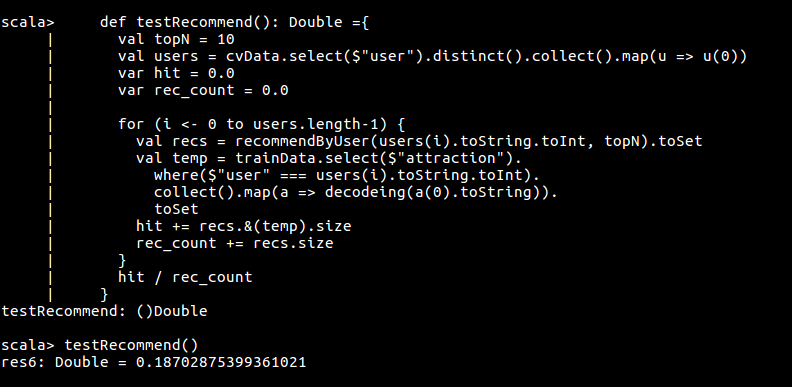
验证推荐模型的正确率
def testRecommend(): Unit ={
val topN = 10
val users = cvData.select($"user").distinct().collect().map(u => u(0))
var hit = 0.0
var rec_count = 0.0
var test_count = 0.0
for (i <- 0 to users.length-1) {
val recs = recommendByUser(users(i).toString.toInt, topN).toSet
val temp = cvData.select($"attraction").
where($"user" === users(i).toString.toInt).
collect().map(a => decodeing(a(0).toString)).
toSet
hit += recs.&(temp).size
rec_count += recs.size
test_count += temp.size
}
print ("正确率:" + (hit / rec_count))
print ("召回率:" + (hit / test_count))
}