本文基于《Spark 高级数据分析》第2章 用Scala和Spark进行数据分析。
完整代码见 https://github.com/libaoquan95/aasPractice/tree/master/c2/Into
1.获取数据集
数据集来自加州大学欧文分校机器学习资料库(UC Irvine Machine Learning Repository),这个资料库为研究和教学提供了大量非常好的数据源, 这些数据源非常有意义,并且是免费的。 我们要分析的数据集来源于一项记录关联研究,这项研究是德国一家医院在 2010 年完成的。这个数据集包含数百万对病人记录,每对记录都根据不同标准来匹配,比如病人姓名(名字和姓氏)、地址、生日。每个匹配字段都被赋予一个数值评分,范围为 0.0 到 1.0, 分值根据字符串相似度得出。然后这些数据交由人工处理,标记出哪些代表同一个人哪些代表不同的人。 为了保护病人隐私,创建数据集的每个字段原始值被删除了。病人的 ID、 字段匹配分数、匹配对标示(包括匹配的和不匹配的)等信息是公开的,可用于记录关联研究
下载地址:
- http://bit.ly/1Aoywaq (需翻墙)
- https://github.com/libaoquan95/aasPractice/tree/master/c2/linkage(已解压,block_1.csv 到 block_10.csv)
2.设置Spark运行环境,读取数据
val sc = SparkSession.builder().appName("Into").master("local").getOrCreate()
import sc.implicits._
读取数据集
// 数据地址
val dataDir = "inkage/block_*.csv"
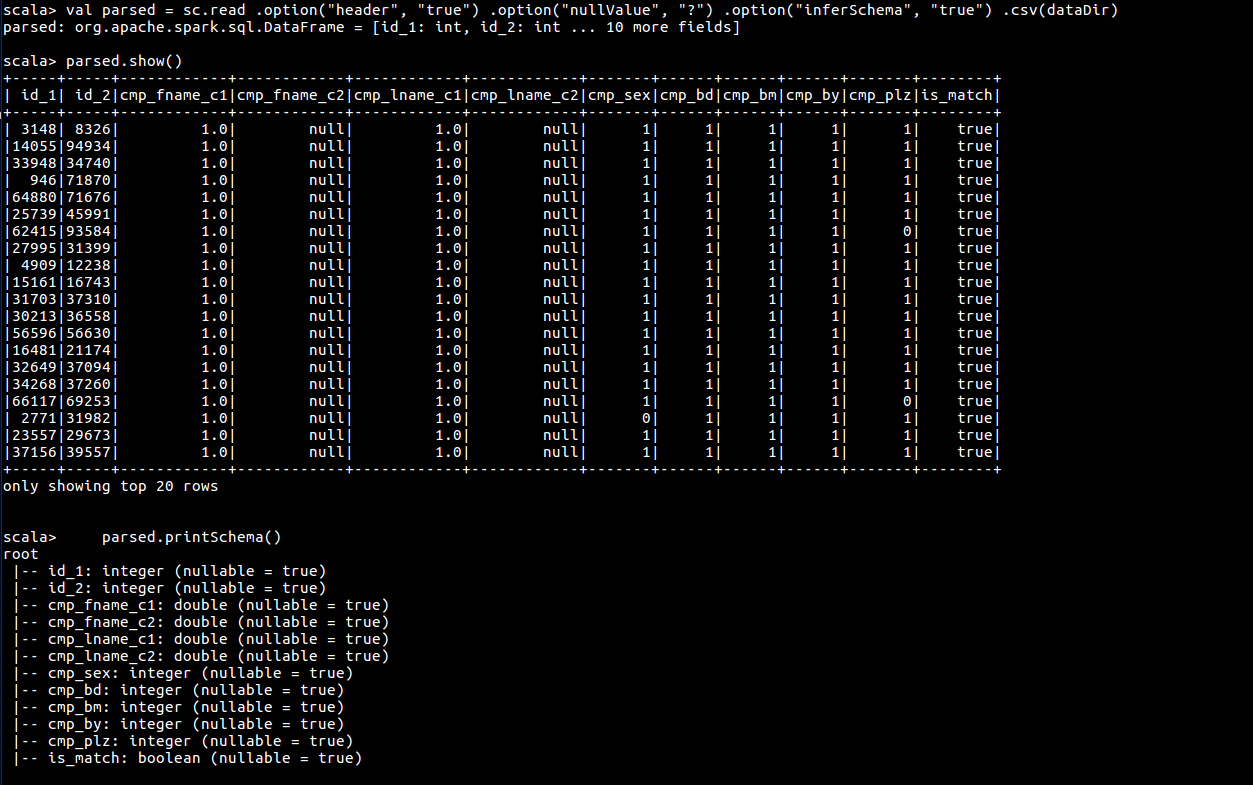
// 读取有头部标题的CSV文件,并设置空值
val parsed = sc.read .option("header", "true") .option("nullValue", "?") .option("inferSchema", "true") .csv(dataDir)
// 查看表
parsed.show()
// 查看表结构
parsed.printSchema()
parsed.cache()
3.处理数据
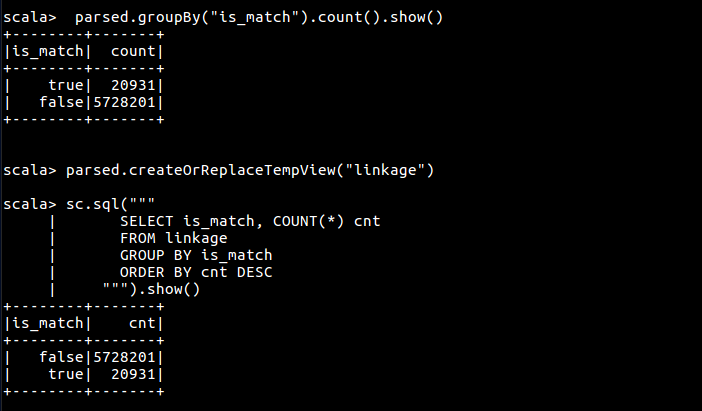
首先按 is_match 字段聚合数据,有两种方式可以进行数据聚合,一是使用 groupby 函数,二是使用 Spark Sql
// 聚合
parsed.groupBy("is_match").count().orderBy($"count".desc).show()
// 先注册为临时表
parsed.createOrReplaceTempView("linkage")
// 使用sql查询,效果同上
sc.sql("""
SELECT is_match, COUNT(*) cnt
FROM linkage
GROUP BY is_match
ORDER BY cnt DESC
""").show()
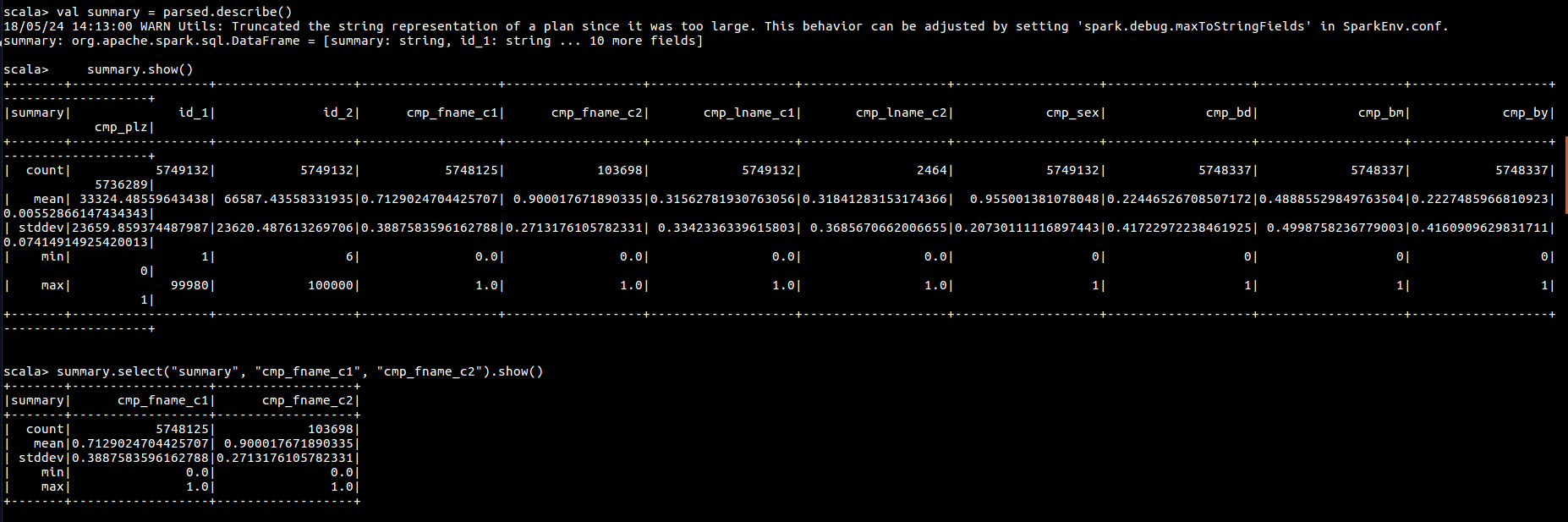
之后使用 describe 函数获取每个字段的最值,均值等信息
// 获取每一列的最值,平均值信息
val summary = parsed.describe()
summary.show()
summary.select("summary", "cmp_fname_c1", "cmp_fname_c2").show()
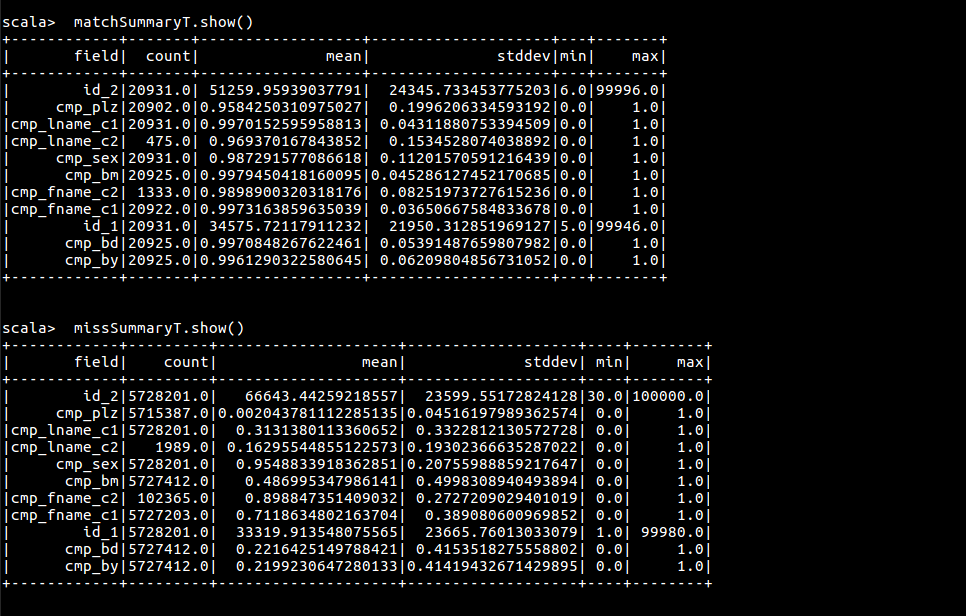
按此方式获取匹配记录和不匹配记录的 describe
// 获取匹配和不匹配的信息
val matches = parsed.where("is_match = true")
val misses = parsed.filter($"is_match" === false)
val matchSummary = matches.describe()
val missSummary = misses.describe()
matchSummary .show()
missSummary .show()
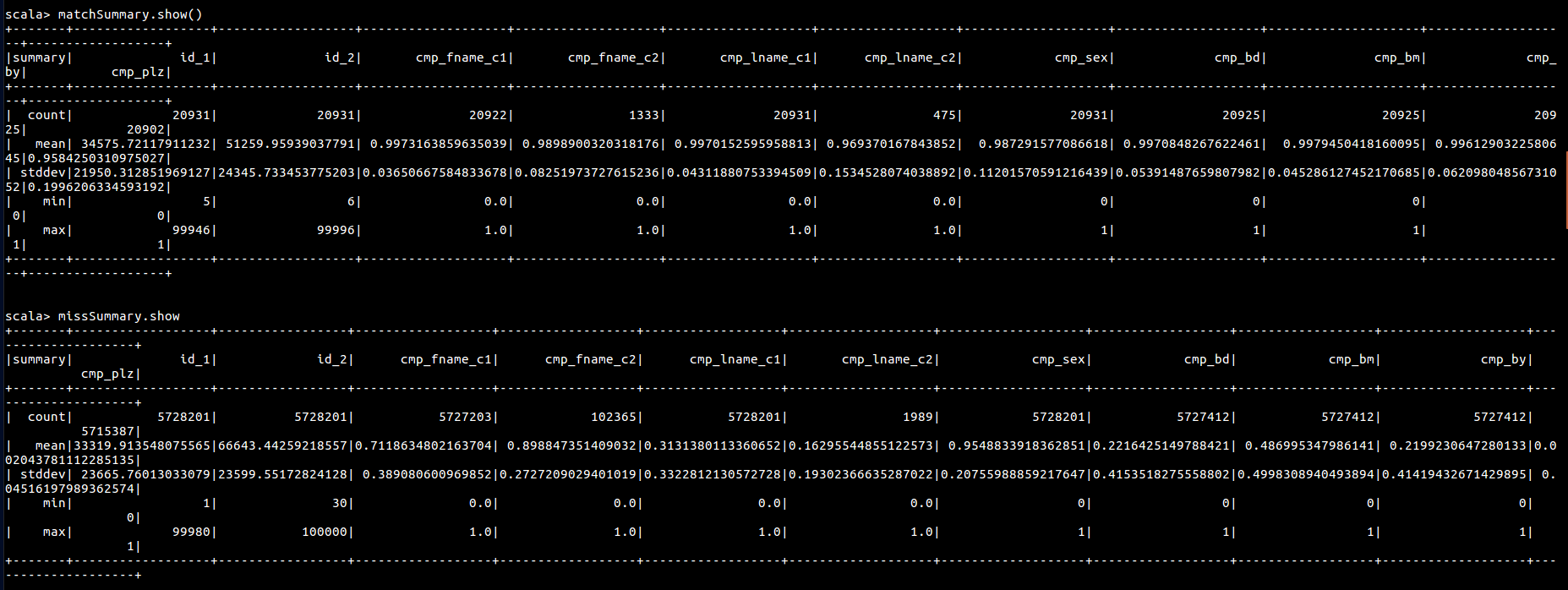
可以看到这个数据不方便进行操作,可以考虑将其转置,方便使用sql对数据进行分析
def longForm(desc: DataFrame): DataFrame = {
import desc.sparkSession.implicits._ // For toDF RDD -> DataFrame conversion
val schema = desc.schema
desc.flatMap(row => {
val metric = row.getString(0)
(1 until row.size).map(i => (metric, schema(i).name, row.getString(i).toDouble))
})
.toDF("metric", "field", "value")
}
def pivotSummary(desc: DataFrame): DataFrame = {
val lf = longForm(desc)
lf.groupBy("field").
pivot("metric", Seq("count", "mean", "stddev", "min", "max")).
agg(first("value"))
}
// 转置,重塑数据
val matchSummaryT = pivotSummary(matchSummary)
val missSummaryT = pivotSummary(missSummary)
matchSummaryT.createOrReplaceTempView("match_desc")
missSummaryT.createOrReplaceTempView("miss_desc")
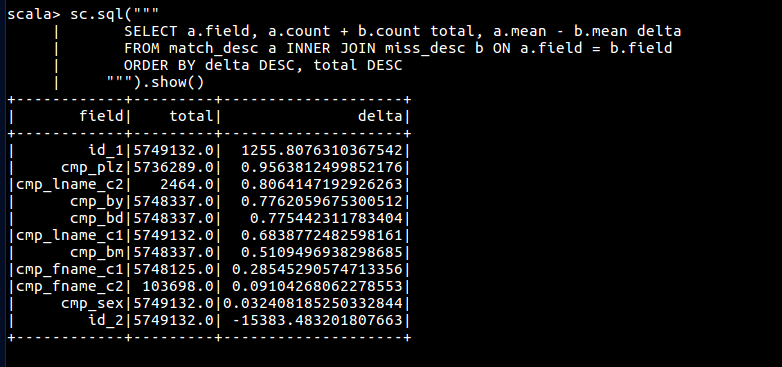
sc.sql("""
SELECT a.field, a.count + b.count total, a.mean - b.mean delta
FROM match_desc a INNER JOIN miss_desc b ON a.field = b.field
ORDER BY delta DESC, total DESC
""").show()