JVM?JDK?JRE?关系?
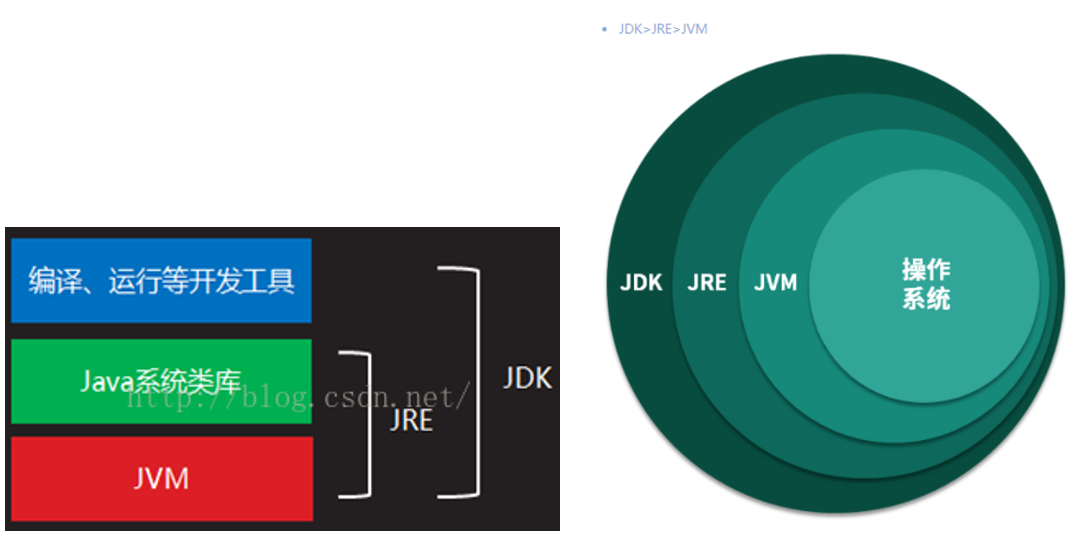
JDK(Java Development Kit),它是实际上存在的,它包含JRE+编译、运行等开发工具.
JRE(Java Runtime Environment),它用于提供运行时环境。它是JVM的实现。它是实际存在的。它包含一组系统类库和JVM。
JVM是什么?
JVM(Java Virtual Machine,Java 虚拟机)顾名思义就是用来执行 Java 程序的“虚拟主机”,实际的工作是将编译生成的.class 文件(字节码)翻译成底层操作系统可以运行的机器码并且进行调用执行,这也是 Java 程序能够跨平台(“一次编写,到处运行”)的原因(因为它会根据特定的操作系统生成对应的操作指令),Java语言最重要的特点就是跨平台运行。使用JVM就是为了支持与操作系统无关,实现跨平台。
JVM 的种类有很多,比如 HotSpot 虚拟机,它是 Sun/OracleJDK 和 OpenJDK 中的默认 JVM,也是目前使用范围最广的 JVM。我们常说的 JVM 其实泛指的是 HotSpot 虚拟机,还有曾经与 HotSpot 齐名为“三大商业 JVM”的 JRockit 和 IBM J9 虚拟机。但无论是什么类型的虚拟机都必须遵守 Oracle 官方发布的《Java虚拟机规范》,它是 Java 领域最权威最重要的著作之一,用于规范 JVM 的一些具体“行为”。
JVM 和操作系统的关系?
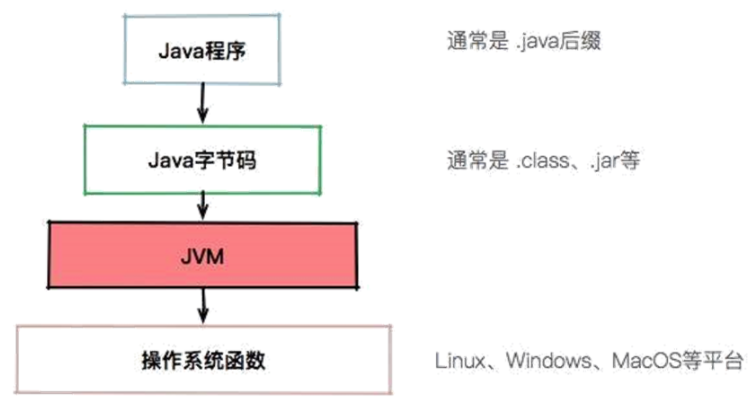
我们用一句话概括 JVM 与操作系统之间的关系:JVM 上承开发语言,下接操作系统,它的中间接口就是字节码。
有了 JVM 这个抽象层之后,Java 就可以实现跨平台了。JVM 只需要保证能够正确执行 .class 文件,就可以运行在诸如 Linux、Windows、MacOS 等平台上了。而 Java 跨平台的意义在于一次编译,处处运行,能够做到这一点 JVM 功不可没。比如我们在 Maven 仓库下载同一版本的 jar 包就可以到处运行,不需要在每个平台上再编译一次。
怎么理解Java跨平台?
https://blog.csdn.net/Iamthedoctor123/article/details/84451622
Java 虚拟机规范和 Java 语言规范的关系?
广义上来讲,JVM 是一种规范,它是最为官方、最为准确的文档;
狭义上来讲,由于我们使用 Hotspot 更多一些,我们一般在谈到这个概念时,会将它们等同起来。
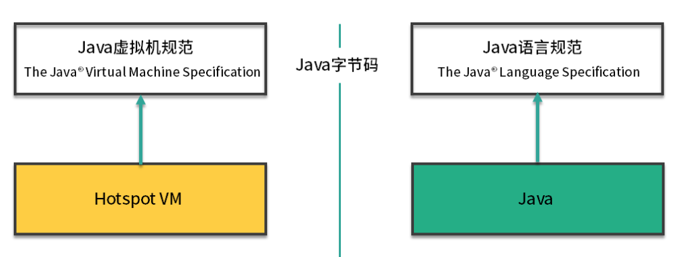
左半部分是 Java 虚拟机规范,其实就是为输入和执行字节码提供一个运行环境。
右半部分是我们常说的 Java 语法规范,比如 switch、for、泛型、lambda 等相关的程序,最终都会编译成字节码。而连接左右两部分的桥梁依然是 Java 的字节码。
JVM 的内存布局(内存结构)?
Java运行时数据区:Java虚拟机在执行Java程序的过程中会将其管理的内存划分为若干个不同的数据区域,这些区域有各自的用途、创建和销毁的时间,有些区域随虚拟机进程的启动而存在,有些区域则是依赖用户线程的启动和结束来建立和销毁。
根据《Java虚拟机规范》的规定,Java虚拟机所管理的内存包括以下几个运行时数据区域,如图:
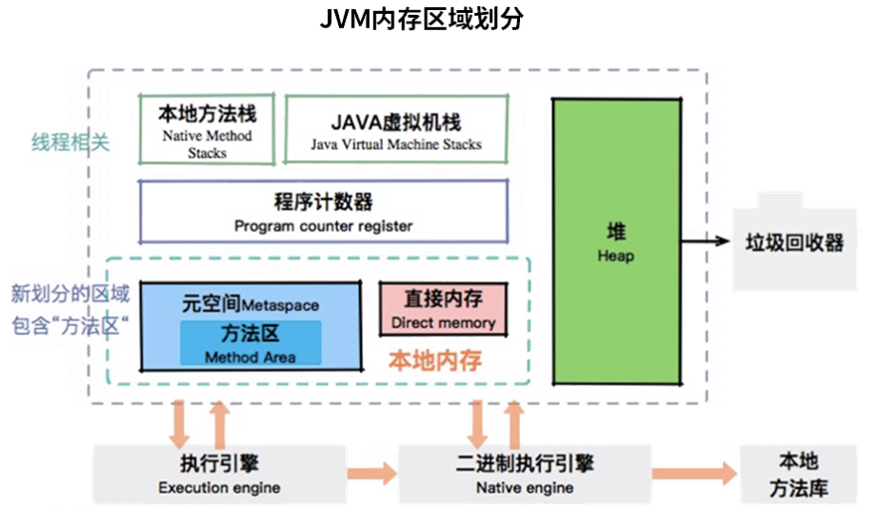
方法区和堆是所有线程共享的内存区域;而虚拟机栈、本地方法栈和程序计数器是运行线程私有的内存区域。
1)堆
堆(Java Heap),也叫 Java 堆或者是 GC 堆(Java堆是垃圾收集器管理的内存区域,因此很多时候称为“GC堆”),在虚拟机启动时创建,是一个线程共享的内存区域,也是 JVM 中占用内存最大的一块区域,Java对象存储的地方。
《Java虚拟机规范》对 Java 堆的描述是:“所有的对象实例以及数组都应当在堆上分配”。但这在技术日益发展的今天已经有点不那么“准确”了,比如 JIT(Just In Time Compilation,即时编译 )优化中的逃逸分析,使得变量可以直接在栈上被分配。当对象或者是变量在方法中被创建之后,其指针可能被线程所引用,而这个对象就被称作指针逃逸或者是引用逃逸。
比如以下代码中的 sb 对象的逃逸:
public static StringBuffer createString() { StringBuffer sb = new StringBuffer(); sb.append("Java"); return sb; }
sb 虽然是一个局部变量,但上述代码可以看出,它被直接 return 出去了,因此可能被赋值给了其他变量,并且被完全修改,于是此 sb 就逃逸到了方法外部。
想要 sb 变量不逃逸也很简单,可以改为如下代码:
public static String createString() { StringBuffer sb = new StringBuffer(); sb.append("Java"); return sb.toString(); }
通过逃逸分析可以让变量或者是对象直接在栈上分配,从而极大地降低了垃圾回收的次数,以及堆分配对象的压力,进而提高了程序的整体运行效率。
堆大小的值可通过 -Xms 和 -Xmx 来设置(设置最小值和最大值),当堆超过最大值时就会抛出 OOM(OutOfMemoryError)异常。
2)方法区
方法区(Method Area), 也被称为非堆区,用于和“Java 堆”的概念进行区分,方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,用于存储已经被 JVM 加载的类信息、常量、静态变量、即时编译后的代码等数据。
永久代:
说到方法区有人可能会联想到“永久代”,但对于《Java虚拟机规范》来说并没有规定这样一个区域,同样它也只是 HotSpot 中特有的一个概念。这是因为 HotSpot 技术团队把垃圾收集器的分代设计扩展到方法区之后才有的一个概念,可以理解为 HotSpot 技术团队只是用永久代来实现方法区而已,但这会导致一个致命的问题,这样设计更容易造成内存溢出。因为永久代有 -XX:MaxPermSize(方法区分配的最大内存)的上限,即使不设置也会有默认的大小。例如,32 位操作系统中的 4GB 内存限制等,并且这样设计导致了部分的方法在不同类型的 Java 虚拟机下的表现也不同,比如 String::intern() 方法。所以在 JDK 1.7 时 HotSpot 虚拟机已经把原本放在永久代的字符串常量池和静态变量等移出了方法区,并且在 JDK 1.8 中完全废弃了永久代的概念。
运行时常量池:
A、是方法区的一部分
B、存放编译期生成的各种字面量和符号引用
C、Class文件中除了存有类的版本、字段、方法、接口等描述信息,还有一项是常量池,存有这个类的 编译期生成的各种字面量和符号引用,这部分内容将在类加载后,存放到方法区的运行时常量池中。
3)程序计数器
程序计数器(Program Counter Register), 线程独有一块很小的内存区域,保存当前线程所执行字节码的位置,包括正在执行的指令、跳转、分支、循环、异常处理等。
4)虚拟机栈
虚拟机栈也叫 Java 虚拟机栈(Java Virtual Machine Stack),线程私有,是Java执行方法的内存模型,在每个方法被执行时就会同步创建一个栈帧,用来存储局部变量表、操作数栈、动态链接等信息。当调用方法时执行入栈,而方法返回时执行出栈(简洁面试回答版)。
详细版:
每个方法被执行的时候,都会创建一个栈帧,把栈帧压入栈,当方法正常返回或者抛出未捕获的异常时,栈帧就会出栈。
栈帧:栈帧存储方法的相关信息,包含局部变量表、返回值、操作数栈、动态链接
a、局部变量表:包含了方法执行过程中的所有变量。局部变量数组所需要的空间在编译期间完成分配,在方法运行期间不会改变局部变量数组的大小。
b、返回值:如果有返回值的话,压入调用者栈帧中的操作数栈中,并且把PC的值指向方法调用指令后面的一条指令地址。
c、操作数栈:操作变量的内存模型。操作数栈的最大深度在编译的时候已经确定(写入方法区code属性的max_stacks项中)。操作数栈的的元素可以是任意Java类型,包括long和double,32位数据占用栈空间为1,64位数据占用2。方法刚开始执行的时候,栈是空的,当方法执行过程中,各种字节码指令往栈中存取数据。
d、动态链接:每个栈帧都持有在运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法调用过程中的动态链接。
5)本地方法栈
本地方法栈(Native Method Stacks)与虚拟机栈类似,它是线程独享的,并且作用也和虚拟机栈类似。只不过虚拟机栈是为虚拟机中执行的 Java 方法服务的,而本地方法栈则是为虚拟机使用到的本地(Native)方法服务。
补充说明
JDK 1.7 之后把永生代换成的元空间,把字符串常量池从方法区移到了 Java 堆上。
需要注意的是《Java虚拟机规范》只规定了有这么几个区域,但没有规定 JVM 的具体实现细节,因此对于不同的 JVM 来说,实现也是不同的。例如,“永久代”是 HotSpot 中的一个概念,而对于 JRockit 来说就没有这个概念。所以很多人说的 JDK 1.8 把永久代转移到了元空间,这其实只是 HotSpot 的实现,而非《Java虚拟机规范》的规定。
我们写的 Java 代码到底是如何运行起来的?
或者说JVM 的运行原理?执行流程是怎么样的?
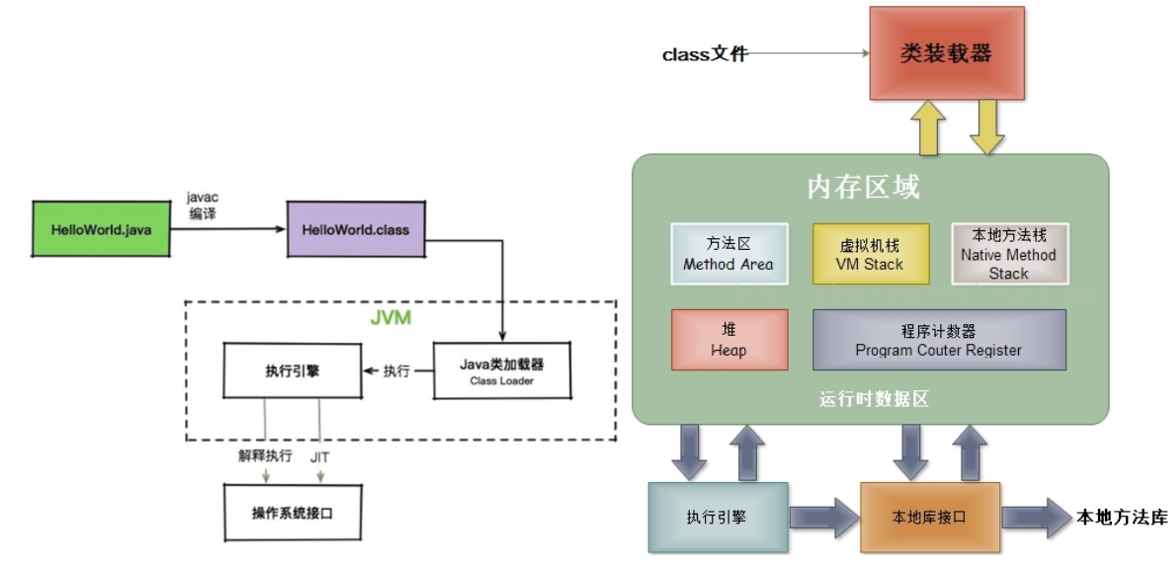
过程如下:Java 文件->编译器>字节码->JVM->机器码。
把我们写好的*.java文件,通过javac命令编译(包含词法分析、语义分析等步骤)成字节码文件,也就是我们常说的.class文件。当我们使用 Java 命令运行 .class 文件的时候,实际上就相当于启动了一个 JVM 进程。然后 JVM 会翻译这些字节码,它有两种执行方式。常见的就是解释执行,将 opcode + 操作数翻译成机器代码;另外一种执行方式就是 JIT,也就是我们常说的即时编译,它会在一定条件下将字节码编译成机器码之后再执行。这些 .class 文件会被加载、存放到 metaspace 中,等待被调用,这里会有一个类加载器的概念。而 JVM 的程序运行,都是在栈上完成的,这和其他普通程序的执行是类似的,同样分为堆和栈。比如我们现在运行到了 main 方法,就会给它分配一个栈帧。当退出方法体时,会弹出相应的栈帧。你会发现,大多数字节码指令,就是不断的对栈帧进行操作。
简洁答
写好的*.java文件,通过javac命令编译成字节码文件(.class文件),然后通过类加载器将字节码加载到内存(运行时数据区)中,存放到 `元数据`区(metaspace) 中等待被调用,使用特定的命令解析器也就是我们俗称的**执行引擎(Execution Engine)**将字节码翻译成可以被底层操作系统执行的指令再去执行,这样就实现了整个 Java 程序的运行,这也是 JVM 的整体执行流程。
常见面试题
JVM 是如何进行内存区域划分的?
JVM 如何高效进行内存管理?
为什么需要有元空间,它又涉及什么问题?
JVM的内存区域是怎么高效划分的?
说一下 JVM 的内存布局和运行原理?
类的加载分为几个阶段?每个阶段代表什么含义?加载了什么内容?
如何判断一个对象是否“死亡”?
垃圾回收的算法有哪些?