一。hdfs原理和架构
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
hdfs架构图
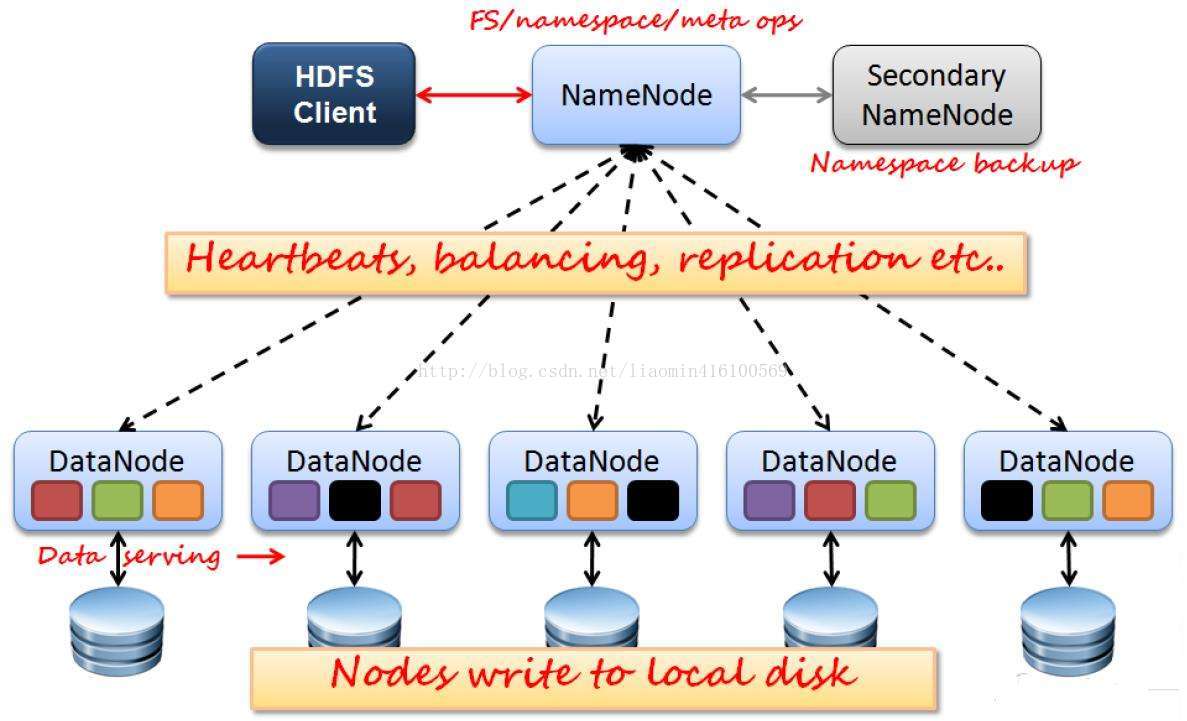
hdfs由 namenode secondarynamenode datanode三种节点类型组成
NameNode:管理HDFS的名称空间和数据块映射信息(一个文件包含的数据块信息)、
配置副本策略(每个数据块都应该有3个以上拷贝 用于容灾)
和处理客户端请求(客户端传送文件名 查询到所有快及快所在数据节点后
让客户端自己请求数据节点获取数据);
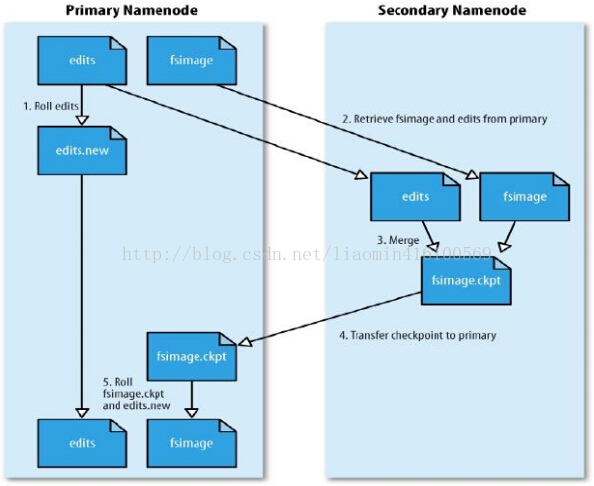
Secondary NameNode:辅助NameNode,分担NameNode工作,定期合并fsimage(元数据 就是保持文件和数据库的关系
不保存块所在的数据服务器 由datanode汇报的 该文件启动就会加载到内存 )
和fsedits(文件操作日志)并推送给NameNode,紧急情况下可辅助恢复NameNode;
DataNode:Slave节点,实际存储数据、执行数据块的读写并汇报存储信息给NameNode
(启动时将快数据加载到内存定时汇报快和当前服务器关系信息给NameNode);由于fsimage文件的重要性 一旦损坏 整个集群就崩溃 所以大并发下的频繁的文件修改 导致fsimage的频繁修改 会出现争抢io等各种情况 为了减少fsiamge
压力 hdfs默认将用户对文件的修改 先记录在日志文件 edtis中 由 SNN节点定时同步fsimage和edtis文件进行数据合并 写到namenode节点fsimage中持久化
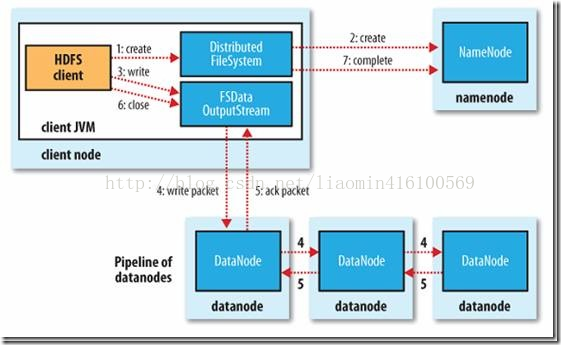
2》文件写流程
写过程:客户端调用hdfsapi发送请求给Namenode namenode返回请求文件的分块服务器信息 客户端将数据分块后 存储到指定datanode
datanode数据写入后 自动复制两份到其他的datanode上
二。hdfs集群安装
1》安装环境参考
模拟环境 :
/etc/hosts 在四台机器的hosts文件中分别添加主机名和ip的关联
192.168.58.147 node1
192.168.58.149 node2
192.168.58.150 node3
192.168.58.151 node4node1 -------------------------namenode
node2--------------------------secondarynode
node2-node4 ------------- - datanodecentos版本 7
hadoop版本:2.7.4
jdk版本 1.8(hadoop安装目录(sharehadoopcommonhadoop-common-2.7.4.jar)下找个jar包 用压缩工具打开
查看META-INF/ MANIFEST.MF Build-Jdk: 1.8.0_40)版本必须在1.8.0_40之上
安装参考http://hadoop.apache.org/docs/r2.7.4/hadoop-project-dist/hadoop-common/ClusterSetup.html
配置文件参考 上面地址所在页面左下角

2》安装步骤
》》四台机器同时安装以下环境
安装jdk
/etc/profile添加
JAVA_HOME=/usr/java/latest
export JAVA_HOME/etc/profile添加
HADOOP_HOME=/soft/hadoop-2.7.4
export HADOOP_HOME~/.bash_profile
PATH=$PATH:/soft/hadoop-2.7.4/bin:/soft/hadoop-2.7.4/sbinsource ~/.bash_profile
source /etc/profilehadoop所有配置文件位于 hadoop安装目录/etc/hadoop目录下
修改 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
</configuration><configuration>
<property>
<name>dfs.namenode.name.dir</name> <!--配置namenode的fsimage和edits文件的存储目录-->
<value>/namedata</value>
</property>
<property>
<name>dfs.datanode.data.dir</name><!--配置datanode数据库的存储目录-->
<value>/blockdata</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:50090</value>
</property>
</configuration>修改slaves文件(所有数据节点所在的服务器主机名 也可以写ip)
node2
node3
node4hadoop需要所有节点配置文件一致 就可以在任意机器进行文件的操作 拷贝node1上所有修改后的配置文件到node2-node4
scp -r ./ root@node2:/soft/hadoop-2.7.4/etc/hadoop
scp -r ./ root@node3:/soft/hadoop-2.7.4/etc/hadoop
scp -r ./ root@node4:/soft/hadoop-2.7.4/etc/hadoop配置 node1 免密登录 node2-node4
node1上生成公私钥
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys[root@node1 hadoop]# ssh localhost
Last login: Thu Oct 19 20:24:37 2017 from 192.168.58.1scp ./id_rsa.pub root@node2:~/
scp ./id_rsa.pub root@node3:~/
scp ./id_rsa.pub root@node4:~/
node2-node4执行
cat ~/id_rsa.pub >> ~/.ssh/authorized_keys[root@node1 ~]# ssh node2
Last login: Thu Oct 19 20:24:42 2017 from 192.168.58.1
[root@node2 ~]# ssh node3
root@node3's password:
[root@node2 ~]# exit
logout
Connection to node2 closed.
[root@node1 ~]# ssh node2
Last login: Thu Oct 19 20:33:14 2017 from node1
[root@node2 ~]# exit
logout
Connection to node2 closed.
[root@node1 ~]# ssh node3
Last login: Thu Oct 19 20:24:47 2017 from 192.168.58.1
[root@node3 ~]# exit
logout
Connection to node3 closed.
[root@node1 ~]# ssh node4
Last login: Thu Oct 19 20:26:10 2017 from 192.168.58.1
[root@node4 ~]# exit
logout
Connection to node4 closed.分别在namenode创建 namenode指定目录
datanode创建 datanode指定目录
node1执行
mkdir -p /namedatadata2-data4执行
mkdir -p /blockdata格式化namenode元数据文件(fsimage)
》hdfs namenode -format
17/10/17 19:32:51 INFO namenode.FSImageFormatProtobuf: Saving image file /namedata/current/fsimage.ckpt_0000000000000000000 using no compression
17/10/17 19:32:51 INFO namenode.FSImageFormatProtobuf: Image file /namedata/current/fsimage.ckpt_0000000000000000000 of size 321 bytes saved in 0 seconds.
17/10/17 19:32:51 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/10/17 19:32:51 INFO util.ExitUtil: Exiting with status 0
17/10/17 19:32:51 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.58.147
************************************************************/》》启动hadoop集群
一次性启动集群
namenode上执行
[root@node1 hadoop]# start-dfs.sh
Starting namenodes on [node1]
node1: starting namenode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-namenode-node1.out
node2: starting datanode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-datanode-node2.out
node3: starting datanode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-datanode-node3.out
node4: starting datanode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-datanode-node4.out
Starting secondary namenodes [node2]
node2: starting secondarynamenode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-node2.out
[root@node1 hadoop]# ll单独启动每一个hadoop
namenode上执行
[root@node1 hadoop]# hadoop-daemon.sh --config /soft/hadoop-2.7.4/etc/hadoop --script hdfs start namenode
starting namenode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-namenode-node1.out
[root@node2 hadoop]# hadoop-daemon.sh --config /soft/hadoop-2.7.4/etc/hadoop --script hdfs start secondarynamenode
starting secondarynamenode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-secondarynamenode-node2.out
每个datanode上执行
[root@node2 current]# hadoop-daemon.sh --config /soft/hadoop-2.7.4/etc/hadoop --script hdfs start datanode
starting datanode, logging to /soft/hadoop-2.7.4/logs/hadoop-root-datanode-node2.out三。hdfs客户端命令
hdfs命令下子命令dfs用于文件的操作 hdfs文件的存储结构和linux操作系统的目录树结构一致 根目录是/
该子命令和linux命令相差不大
[root@node1 ~]# hdfs dfs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...] 查看文件内容
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] 添加文件的权限
[-chown [-R] [OWNER][:[GROUP]] PATH...] 修改文件所属用户和组
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] <path> ...]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>] 从hadoop一个目录拷贝到另外一个目录
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-expunge]
[-find <path> ... <expression> ...] 搜索某个路径下是否有某些文件
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 下载hadoop文件到本地
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]] 查看目录下的文件 -R递归搜索
[-mkdir [-p] <path> ...] 创建目录
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>] 重命名
[-put [-f] [-p] [-l] <localsrc> ... <dst>] 上传本地文件到hadoop中
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...] 删除文件
[-rmdir [--ignore-fail-on-non-empty] <dir> ...] 删除目录
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
put上传时 出现错误
[root@node1 /]# cd aaa
[root@node1 aaa]# hdfs dfs -put a.txt /abc
17/10/19 21:23:54 WARN hdfs.DFSClient: DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /abc/a.txt._COPYING_ could only be replicated to 0 nodes instead of minReplication (=1). There are 0 datanode(s) running and no node(s) are excluded in this operation.
at org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.chooseTarget4NewBlock(BlockManager.java:1628)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getNewBlockTargets(FSNamesystem.java:3121) iptable --flush
systemctl stop firewalld[root@node1 /]# mkdir aaa
[root@node1 /]# cd aaa
[root@node1 aaa]# echo hello hdfs > a.txt
[root@node1 aaa]# hdfs dfs -put a.txt /
[root@node1 aaa]# hdfs dfs -ls / 注意这里默认上传用户账号就是系统账户 root
Found 2 items
-rw-r--r-- 3 root supergroup 11 2017-10-19 21:49 /a.txt
drwxr-xr-x - root supergroup 0 2017-10-19 21:23 /abc
[root@node1 aaa]# hdfs dfs -find a.txt /
find: `a.txt': No such file or directory
/
/a.txt
/abc
[root@node1 aaa]# hdfs dfs -ls -R /
-rw-r--r-- 3 root supergroup 11 2017-10-19 21:49 /a.txt
drwxr-xr-x - root supergroup 0 2017-10-19 21:23 /abc
[root@node1 aaa]# hdfs dfs -rm /a.txt
17/10/19 21:50:16 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /a.txt
[root@node1 aaa]# hdfs dfs -mkdir /ttt
[root@node1 aaa]# hdfs dfs -rmr /ttt
rmr: DEPRECATED: Please use 'rm -r' instead.
17/10/19 21:50:39 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /ttt三。hdfsjava客户端
创建maven项目 添加maven依赖
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.et</groupId>
<artifactId>hadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>
</project>package hadoop;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HadoopTest {
public static void main(String[] args) throws Exception {
//设置当前机器的hadoop目录
System.setProperty("hadoop.home.dir", "D:\learn\hadoop\hadoop-2.7.4");
//设置操作使用的用户 如果不设置为root 和 hadoop服务的相同 出现异常 本机账号是window账号
System.setProperty("HADOOP_USER_NAME","root");
String dst = "hdfs://192.168.58.147:9000";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst),conf);
fs.mkdirs(new Path("/ttt1"));
fs.close();
}
}
如果需要设置hdfs的uri 可以将服务器的
core-site.xml hdfs-site.xml log4j.properties拷贝到maven项目src/main/resources
记住主机名 node1-node5 必须在window c:/windows/system32/drivers/etc/hosts配置 代码修改为
package hadoop;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HadoopTest {
public static void main(String[] args) throws Exception {
//设置当前机器的hadoop目录
System.setProperty("hadoop.home.dir", "D:\learn\hadoop\hadoop-2.7.4");
//设置操作使用的用户 如果不设置为root 和 hadoop服务的相同 出现异常 本机账号是window账号
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
fs.mkdirs(new Path("/ttt1"));
fs.close();
}
}
其他操作代码 参考
package hadoop;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class HadoopTest {
public static FileSystem getSystem() throws IOException {
// 设置当前机器的hadoop目录
System.setProperty("hadoop.home.dir", "D:\learn\hadoop\hadoop-2.7.4");
// 设置操作使用的用户 如果不设置为root 和 hadoop服务的相同 出现异常 本机账号是window账号
System.setProperty("HADOOP_USER_NAME", "root");
String dst = "hdfs://192.168.58.147:9000";
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
return fs;
}
/**
* 创建目录
* @param dir 目录名
* @throws IOException
* @throws IllegalArgumentException
*/
public static void mkdir(String dir) throws IllegalArgumentException, IOException{
FileSystem fs= getSystem();
fs.mkdirs(new Path(dir));
fs.close();
}
/**
* 查看某个目录下所有的文件和目录
* @param dir 父目录
* @throws IOException
*/
public static void listFile(String dir) throws IOException{
FileSystem fs= getSystem();
FileStatus[] rtls=fs.listStatus(new Path(dir));
for(FileStatus fst:rtls){
String path=fst.getPath().toString();
System.out.println(path);
}
}
/**
* 上传文件
* @param localFile 本地需要上传文件的绝对路径
* @param destDir 需要上传的目标目录
* @throws IOException
*/
public static void upload(String localFile,String destDir) throws IOException{
FileSystem fs= getSystem();
if(!destDir.endsWith("/")){
destDir=destDir+"/";
}
File localF=new File(localFile);
OutputStream os=fs.create(new Path(destDir+localF.getName()));
InputStream is=new FileInputStream(localF);
IOUtils.copyBytes(is, os, 2048,true);
}
/**
* 下载hdfs文件到本地
* @param hdfsSrc hdfs需要下载的源文件 比如 /ttt/a.html
* @param localDest 本地文件存储的文件全路径 比如 c:/b.html
* @throws IOException
*/
public static void download(String hdfsSrc,String localDest) throws IOException{
FileSystem fs= getSystem();
InputStream is=fs.open(new Path(hdfsSrc));
OutputStream os=new FileOutputStream(localDest);
IOUtils.copyBytes(is, os, 2048, true);
}
/**
* 删除目录
* @param hdfssrc 目录路径
* @throws IOException
* @throws IllegalArgumentException
*/
public static void rmdir(String hdfssrc) throws IllegalArgumentException, IOException{
FileSystem fs= getSystem();
fs.delete(new Path(hdfssrc), true);
}
public static void main(String[] args) throws Exception {
listFile("/");
//upload("c:/a.html","/ttt");
//download("/ttt/a.html","c:/b.htm");
rmdir("/ttt");
}
}