阅读目录
configparser模块
subprocess模块
xlrd模块
xlwt模块
##configparser模块
configparser 定义:用来解析配置文件的: 对配置文件有各式要求: 只能由分区和选项 section 和 option 同一个section' 不能有重复的option 不能有重复的section 不区分数据类型 都是字符串 # 可以用来注释 任何option都必须包含在section 需要掌握的方法 read(文件路径,编码) get(分区名称,选项名称) 返回的是字符串 getint getfloat getboolean #示例 #配置文件mysql.cfg [db] db_host = 127.0.0.1 db_port = 3360 db_user = root db_pass = 123456 host_port = 69 [concurrent] thread = 10 processor = 20 #测试文件 #1、初始化示例,并读取配置文件 import configparser conf = configparser.ConfigParser() conf.read('mysql.cfg',encoding='utf-8') #2、获取所用的section节点 print(conf.sections()) #['db', 'concurrent'] #3、获取指定setion的options,即将配置文件某个section呢key读取到列表中 print(conf.options('db'))#['db_host', 'db_port', 'db_user', 'db_pass', 'host_port'] #4、获取指定setions下指定option值 print(conf.get('db','db_host'))#127.0.0.1 #5、获取section的所有配置信息,即values值 print(conf.items('db'))#[('db_host', '127.0.0.1'), ('db_port', '3360'), ('db_user', 'root'), ('db_pass', 'root'), ('host_port', '69')] #6、修改某个option值,不存在则会去创建 conf.set('db','db_pass','123456') conf.write(open('mysql.cfg','w')) #7、检查section或option是否存在,结果为boolean值 print(conf.has_section('db'))#True print(conf.has_option('db','db_root'))#False #8、添加section和option if not conf.has_section('username'): conf.add_section('username') if not conf.has_option('username','user'): conf.set('username','user','owen')
with open('mysql.cfg','w',encoding='utf-8) as f: conf.write(f) #9、删除section和option,没有不会报错 conf.remove_option('username','user1') conf.remove_section('username') with open('mysql.cfg','w',encoding='utf-8) as f:
conf.write(f)#10、理解点:写入文件 #以下的几行代码只是将文件内容读取到内存中,进过一系列操作之后必须写回文件,才能生效。 import configparser config = configparser.ConfigParser() config.read("ini", encoding="utf-8") #写回文件的方式如下:(使用configparser的write方法)with open('mysql.cfg','w',encoding='utf-8) as f:
with open('mysql.cfg','w',encoding='utf-8) as f:
conf.write(f)
##subprocess
#定义: 子进程 什么是进程? 指的是一个正在运行中的程序 子进程指的是由另个一进程开启的进程 a在运行过程中 开启了b b就是a的子进程 为什么要开启子进程? 当一个程序在运行过程中有一个任务,自己做不了或是不想做 就可以开启另一个进程来帮助其完成任务 例如 qq中收到一个链接 点击链接 就开启了; 浏览器 浏览器就是qq的子进程 可以理解为用于执行系统指令的模块 由于subprocess模块底层的进程创建和管理是由Popen类来处理的,因此,当我们无法通过上面哪些高级函数来实现一些不太常见的功能时就可以通过subprocess.Popen类提供的灵活的api来完成。 #1.subprocess.Popen的构造函数 class subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startup_info=None, creationflags=0, restore_signals=True, start_new_session=False, pass_fds=()) #参数说明: args: 要执行的shell命令,可以是字符串,也可以是命令各个参数组成的序列。当该参数的值是一个字符串时,该命令的解释过程是与平台相关的,因此通常建议将args参数作为一个序列传递。 bufsize: 指定缓存策略,0表示不缓冲,1表示行缓冲,其他大于1的数字表示缓冲区大小,负数 表示使用系统默认缓冲策略。 stdin, stdout, stderr: 分别表示程序标准输入、输出、错误句柄。 preexec_fn: 用于指定一个将在子进程运行之前被调用的可执行对象,只在Unix平台下有效。 close_fds: 如果该参数的值为True,则除了0,1和2之外的所有文件描述符都将会在子进程执行之前被关闭。 shell: 该参数用于标识是否使用shell作为要执行的程序,如果shell值为True,则建议将args参数作为一个字符串传递而不要作为一个序列传递。 cwd: 如果该参数值不是None,则该函数将会在执行这个子进程之前改变当前工作目录。 env: 用于指定子进程的环境变量,如果env=None,那么子进程的环境变量将从父进程中继承。如果env!=None,它的值必须是一个映射对象。 universal_newlines: 如果该参数值为True,则该文件对象的stdin,stdout和stderr将会作为文本流被打开,否则他们将会被作为二进制流被打开。 startupinfo和creationflags: 这两个参数只在Windows下有效,它们将被传递给底层的CreateProcess()函数,用于设置子进程的一些属性,如主窗口的外观,进程优先级等。 #2. subprocess.Popen类的实例可调用的方法 Popen.poll():用于检查子进程(命令)是否已经执行结束,没结束返回None,结束后返回状态码。 Popen.wait(timeout=None):等待子进程结束,并返回状态码;如果在timeout指定的秒数之后进程还没有结束,将会抛出一个TimeoutExpired异常。 Popen.communicate(input=None, timeout=None):该方法可用来与进程进行交互,比如发送数据到stdin,从stdout和stderr读取数据,直到到达文件末尾。 Popen.send_signal(signal):发送指定的信号给这个子进程。 Popen.terminate():停止该子进程。 Popen.kill():杀死该子进程。
#总结:当你需要执行系统指令时 你需要想起它 # subprocess需要掌握的方法 # 参数1 指令 # 2 是否是一个指令 # 3 错误输出管道 # 4 输入管道 # 5 输出管道 # p = subprocess.Popen("你的指令或是某个exe",shell=True,stderr=,stdin=,stdout=) # # 取出管道中的数据 # p.stderr.read() # p.stdout.read() # # 将输入写入管道 交给对方进程 # p.stdin.write(p.stdout.read())
#示例一:
内存中 每个进程的内存区域是相互隔离的不能直接访问 所以需要管道来通讯
# stdout=subprocess.PIPE就是指定了一个输出管道
# p = subprocess.Popen("dir",shell=True,stdout=subprocess.PIPE)
# # 从管道中读取出执行结果
# reuslt = p.stdout.read().decode("GBK")
#示例二:
# 案例:
# tasklist | findstr python # 先执行tasklist 把结果交给 findstr 来处理
# tasklist | findstr python # 先执行tasklist 把结果交给 findstr 来处理
p1 = subprocess.Popen("tasklist",shell=True,stdout=subprocess.PIPE)
p2 = subprocess.Popen("findstr QQ",shell=True,stdin=p1.stdout,stdout=subprocess.PIPE,stderr=subprocess.PIPE)
print(p2.stdout.read())#p2的输入来自p1的输出
print(p2.stderr.read())
print(p2.stderr.read())
##xlrd模块
#概念
#什么是xlrd模块?
#python操作excel主要用到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
#为什么使用xlrd模块?
#在UI自动化或者接口自动化中数据维护是一个核心,所以此模块非常实用。
#安装xlrd模块
#xlrd为第三方模块,需要在命令行终端pip install xlrd
# 在pycharm--->settings--->project interpreter-->选择+号--->搜索xlrd---->install Package--->如果超时---->manage repositories更换pip源码
import xlrd
data = xlrd.open_workbook('test.xls') # 打开xls文件
table = data.sheets()[0] # 打开第一张表
nrows = table.nrows # 获取表的行数
for i in range(nrows): # 循环逐行打印
if i == 0: # 跳过第一行
continue
print table.row_values(i)[:13] # 取前十三列
#基本操作方法
#机密数据.xlsx :工作表:Sheet1
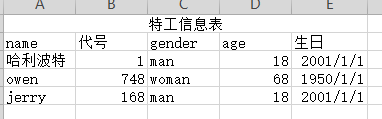
#常用单元格中的数据类型 # 0. empty(空的),1 string(text), 2 number, 3 date, 4 boolean, 5 error, 6 blank(空白表格) #打开excel文件读取数据,文件名以及路径,如果路径或者文件名有中文给前面加一个r表示原生字符。 workbook = xlrd.open_workbook("机密数据.xlsx") #查看所有工作表的名称 print(workbook.sheet_names()) #获取某个工作表 # sheet = workbook.sheet_by_index() sheet = workbook.sheet_by_name("Sheet1") #行的操作 #获取某一行 row = sheet.row(2) print(row)#[text:'name', text:'代号', text:'gender', text:'age', text:'生日'] #获取该sheet中的有效行数 nrows = sheet.nrows print(nrows)#5 #返回由该列中所有的单元格对象组成的列表 print(sheet.row_slice(1)) #列(colnum)的操作 #获取列表的有效列数 print(sheet.ncols)#5 #返回由该列中所有的单元格对象组成的列表 print(sheet.col(1,start_rowx=0, end_rowx=None)) #返回由该列中所有的单元格对象组成的列表 print(sheet.col_slice(1,start_rowx=0, end_rowx=None)) #返回由该列中所有单元格的数据类型组成的列表 print(sheet.col_types(1,start_rowx=0, end_rowx=None))#[0, 1, 2, 2, 2] #返回由该列中所有单元格的数据组成的列表 print(sheet.col_values(1,start_rowx=0, end_rowx=None)) #获取单元格:第一行第五个单元格,下标从零开始 cell = row[4] print(cell.ctype)# 单元格的数据类型 print(cell.value)# 单元格的数据 #返回单元格中的数据类型 print(sheet.cell_type(1,1)) #返回单元格中的数 print(sheet.cell_value(1,1))#代号 #转换日期 print(str(xlrd.xldate_as_datetime(cell.value,0)))#0为datemode,设置为1 相差四年 #某个单元格数据 print(sheet.cell(0,0))#text:'特工信息表' # 案例 将边个数据提取为python数据类型:[{},{},{}] import xlrd ls =[]#定义一个列表 #打开excel 获取工作簿 workbook = xlrd.open_workbook("机密数据.xlsx") #获取工作表 sheet = workbook.sheet_by_name("Sheet1") #列出第二行的名称 keys =sheet.row_values(1) print(keys)#['name', '代号', 'gender', 'age', '生日'] #从第三行开始读 for i in range(2,sheet.nrows): #列出所有行 row = sheet.row_values(i) dic={} #列出第二行的每一列 for k in keys: # print(k) dic[k]= row[keys.index(k)]#keys.index(k)为第二行每个值所对应的索引,row[keys.index(k)]表示当前行的每个值,进行添加到字典 if k == '生日': # 如果是生日字段 需要转换时间类型 dic[k] = str(xlrd.xldate_as_datetime(row[keys.index(k)], 0)) ls.append(dic) print(ls)
##xlwt模块
import xlwt xlwt 是第三方的用于生成一个Exel表格 # 创建一个工作薄 wb = xlwt.Workbook() # 创建一个工作表 sheet = wb.add_sheet("特工信息") # type:xlwt.Worksheet # 字体对象 font = xlwt.Font() font.bold = True # style样式对象 style = xlwt.XFStyle() style.font = font # 将字体设置到样式中 # 写入数据 # sheet.write(0,0,"这是标题") # 写入 并合并单元格 sheet.write_merge(0,0,0,4,"这是标题",style) # 将工作薄写入到文件 wb.save("abc.xls") #示例 "将数据写入到表格中" import xlwt data = [{'name': '哈利波特', '代号': 1.0, 'gender': 'man', 'age': 18.0, '生日': '2001-01-01 00:00:00'},
{'name': 'owen', '代号': 748.0, 'gender': 'woman', 'age': 68.0, '生日': '1950-01-01 00:00:00'},
{'name': 'jerry', '代号': 168.0, 'gender': 'man', 'age': 18.0, '生日': '2001-01-01 00:00:00'}] wb = xlwt.Workbook() sheet = wb.add_sheet("特工信息") # 写入标题 sheet.write_merge(0,0,0,4,"特工信息表") # 写入列名称 keys = data[0].keys() i = 0 for k in keys: sheet.write(1,i,k) i += 1 # 写入数据 for dic in data: values = list(dic.values()) row_index = 2 + data.index(dic) for v in values: sheet.write(row_index,values.index(v),v) # 保存文件 wb.save("机密数据副本.xls")