一:tensorflow中的计算定义和执行
首先,对于tensorflow来说,最重要的概念就是图(Graph)和会话(Session),tensorflow的计算思想是:以图的形式来表示模型,表示和计算分隔开。
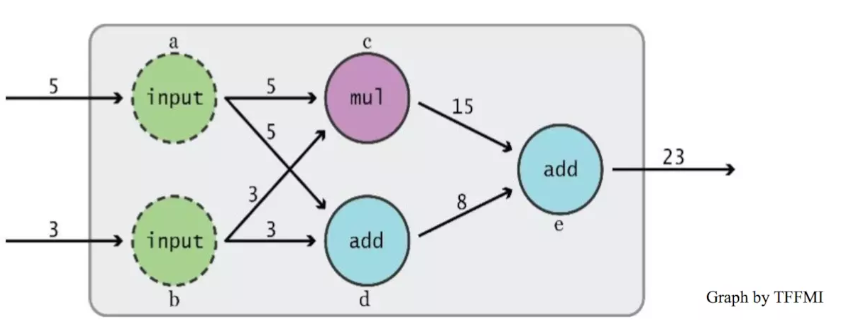
这就是一个Data Flow Graph,最核心的就是定义和计算不等于执行,一个模型跑起来只需要两步:先描述整幅图,然后在session中执行运算。tensorflow==tensor + flow,tensor是张量,flow流动,可以理解为张量在图中通过上图所示里面的a,b,c,d,e这些运算(这里把他们叫做op)进行流动(传递和变换)。下面通过一个简单的实例看一下:
v1 = tf.constant([1,2,3]) v2 = tf.constant([4,5,6]) v3 = tf.add(v1, v2) print(v1) print(v2) print(v3) with tf.Session() as sess: print(sess.run(v3))
在上面,定义了两个常量类型的张量(后面会说)v1、v2,v3把v1、v2相加,然后通缩Seeion执行运算,看一下输出结果:
Tensor("Const:0", shape=(3,), dtype=int32) Tensor("Const_1:0", shape=(3,), dtype=int32) Tensor("Add:0", shape=(3,), dtype=int32) [5 7 9]
可以看到,此时的v3并不是我们想要的数据,而是一个张量,括号里面显示了张量的类型,形状,以及里面的数据类型。这就是上面说的tensorflow中计算定义和执行是分开的,要想得到结果就必须用session来执行运算,首先初始化session,然后调用run()方法来执行定义的v3这个运算,这样我们就可以输出结果了,经过run之后再次输出,此时的结果就是我们想要的数据[5 7 9]了。session在执行的时候会找到你让他执行的运算a的依赖,把依赖的节点都进行计算,不需要的节点则不用计算。
二:tensorflow中的张量类型
张量:可理解为一个 n 维矩阵,所有类型的数据,包括标量、矢量和矩阵等都是特殊类型的张量。
TensorFlow 支持以下三种类型的张量:
- 常量constant:常量是其值不能改变的张量。
- 变量variable:当一个量在会话中的值需要更新时,使用变量来表示。例如,在神经网络中,权重需要在训练期间更新,可以通过将权重声明为变量来实现。变量在使用前需要被显示初始化。另外需要注意的是,常量存储在计算图的定义中,每次加载图时都会加载相关变量。换句话说,它们是占用内存的。另一方面,变量又是分开存储的。它们可以存储在参数服务器上。
- 占位符placeholder:用于将值输入 TensorFlow 图中。它们可以和 feed_dict 一起使用来输入数据。在训练神经网络时,它们通常用于提供新的训练样本。在会话中运行计算图时,可以为占位符赋值。这样在构建一个计算图时不需要真正地输入数据。需要注意的是,占位符不包含任何数据,因此不需要初始化它们。
2.1:tensorflow常量
可以这样声明一个常量:
a = tf.constant(2, name="a") b = tf.constant(3, name="b") x = tf.add(a, b, name="add")
这里的name是为了在tensorboard中方便查看,至于tensorboard就是整个模型的图表示。
t_2 = tf.constant([4,3,2])
要创建一个所有元素为零的张量,可以使用 tf.zeros() 函数。这个语句可以创建一个形如 [M,N] 的零元素矩阵,数据类型(dtype)可以是 int32、float32 等:tf.zeros([M,N],tf.dtype)
例如:zero_t = tf.zeros([2,3],tf.int32) # Results in an 2x3 array of zeros:[[0 0 0],[0 0 0]]
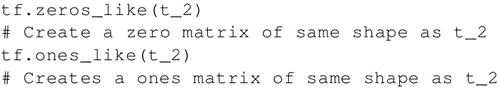
创建一个所有元素都设为 1 的张量。下面的语句即创建一个形如 [M,N]、元素均为 1 的矩阵:
tf.ones([M,N],tf,dtype)
例如:ones_t = tf.ones([2,3],tf.int32) # Results in an 2x3 array of ones:[[1 1 1],[1 1 1]]
更进一步,还有以下语句:
- 在一定范围内生成一个从初值到终值等差排布的序列:
tf.linspace(start,stop,num)
相应的值为 (stop-start)/(num-1)。例如:range_t = tf.linspace(2.0,5.0,5) #We get:[2. 2.75 3.5 4.25 5.]
- 从开始(默认值=0)生成一个数字序列,增量为 delta(默认值=1),直到终值(但不包括终值):
tf.range(start,limit,delta)
下面给出实例:range_t = tf.range(10) #Result:[0 1 2 3 4 5 6 7 8 9]
TensorFlow 允许创建具有不同分布的随机张量:
- 使用以下语句创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的正态分布随机数组:
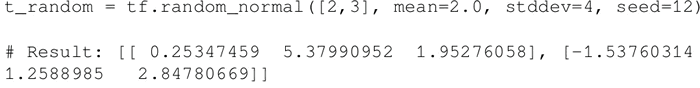
- 创建一个具有一定均值(默认值=0.0)和标准差(默认值=1.0)、形状为 [M,N] 的截尾正态分布随机数组:

- 要在种子的 [minval(default=0),maxval] 范围内创建形状为 [M,N] 的给定伽马分布随机数组,请执行如下语句:

- 要将给定的张量随机裁剪为指定的大小,使用以下语句:
tf.random_crop(t_random,[2,5],seed=12)
这里,t_random 是一个已经定义好的张量。这将导致随机从张量 t_random 中裁剪出一个大小为 [2,5] 的张量。
很多时候需要以随机的顺序来呈现训练样本,可以使用 tf.random_shuffle() 来沿着它的第一维随机排列张量。如果 t_random 是想要重新排序的张量,使用下面的代码:
tf.random_shuffle(t_random)
- 随机生成的张量受初始种子值的影响。要在多次运行或会话中获得相同的随机数,应该将种子设置为一个常数值。当使用大量的随机张量时,可以使用 tf.set_random_seed() 来为所有随机产生的张量设置种子。以下命令将所有会话的随机张量的种子设置为 54:
tf.set_random_seed(54)
TIP:种子只能有整数值。
2.2:tensorflow变量
它们通过使用变量类来创建。变量的定义还包括应该初始化的常量/随机值。下面的代码中创建了两个不同的张量变量 t_a 和 t_b。两者将被初始化为形状为 [50,50] 的随机均匀分布,最小值=0,最大值=10:
注意:变量通常在神经网络中表示权重和偏置。
下面的代码中定义了两个变量的权重和偏置。权重变量使用正态分布随机初始化,均值为 0,标准差为 2,权重大小为 100×100。偏置由 100 个元素组成,每个元素初始化为 0。在这里也使用了可选参数名以给计算图中定义的变量命名:
在前面的例子中,都是利用一些常量来初始化变量,也可以指定一个变量来初始化另一个变量。下面的语句将利用前面定义的权重来初始化 weight2: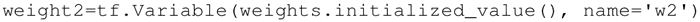
变量的定义将指定变量如何被初始化,但是必须显式初始化所有的声明变量。在计算图的定义中通过声明初始化操作对象来实现: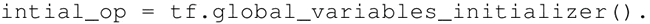
每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化:
保存变量:使用 Saver 类来保存变量,定义一个 Saver 操作对象:
saver = tf.train.Saver()
输出变量内容会用到Eval()函数:
# W 是一个700 x 100 随机变量 W = tf.Variable(tf.truncated_normal([700, 10])) with tf.Session() as sess: sess.run(W.initializer) print(w) print(w.eval())>> Tensor("Variable/read:0", shape=(700, 10), dtype=float32) >> [[-0.76781619 -0.67020458......
2.3:tensorflow占位符
可以使用下面的方法定义一个占位符:
tf.placeholder(dtype, shape = None, name = None)
通过一个例子看一下:
# create a placeholder of type float 32-bit, shape is a vector of 3 elements a = tf.placeholder(tf.float32, shape=[3]) # create a constant of type float 32-bit, shape is a vector of 3 elements b = tf.constant([5, 5, 5], tf.float32) # use the placeholder as you would a constant or a variable c=a+b #Shortfortf.add(a,b) with tf.Session() as sess: print sess.run(c)
上面这段程序会报错:# Error because a doesn’t have any value 对于a我们没有给任何数据,我们将代码修改为:
# create a placeholder of type float 32-bit, shape is a vector of 3 elements a = tf.placeholder(tf.float32, shape=[3]) # create a constant of type float 32-bit, shape is a vector of 3 elements b = tf.constant([5, 5, 5], tf.float32) # use the placeholder as you would a constant or a variable c=a+b #Shortfortf.add(a,b) with tf.Session() as sess: # feed [1, 2, 3] to placeholder a via the dict {a: [1, 2, 3]} print sess.run(c, {a: [1, 2, 3]}) # the tensor a is the key, not the string ‘a’ # >> [6, 7, 8]
我们通过字典的形式将数据传给placeholder,这是tensorflow中最普遍的方式
下面我们再看一个例子:先创建两个op
a = tf.add(2, 5)
b = tf.mul(a, 3)
然后创建一个replace_dict来修改a的值:
with tf.Session() as sess: # define a dictionary that says to replace the value of 'a' with 15 replace_dict = {a: 15} # Run the session, passing in 'replace_dict' as the value to 'feed_dict' sess.run(b, feed_dict=replace_dict) # returns 45
feed_dict是tensorflow中用于喂数据的方法,都以字典形式存入,就像上面这一段代码,feed_dict={a:15},那么就把b这个op中的a的值赋值为15。
文章参考:https://www.jianshu.com/p/f4cca870b893、http://c.biancheng.net/view/1885.html
***************不积跬步无以至千里***************