这次作业的要求来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881
1. 简单说明爬虫原理
通过代码从网页抓取所需的信息
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;

2).使用 requests 库抓取网站数据;
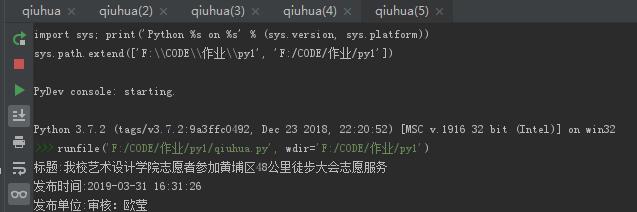
requests.get(url) 获取校园新闻首页html代码
#导入requests库 import requests from bs4 import BeautifulSoup url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0331/11111.html' news = requests.get(url) news.encoding = 'utf-8' print(news.text)
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>1</title>
<script type="text/javascript" src="js/jquery-1.9.0.js" ></script>
<script>
$(document).ready(function(){
$("form input").css("border","3px solid red");
})
</script>
<script>
function click(){
alert("你好");
}
</script>
<style>
form{
border: 2px green;
}
</style>
</head>
<body>
<form>
用户名:<input name="textname" type="text" value="" /><br>
密 码:<input name="textpass" type="password" /><br>
<button onclick="click()">提交</button>
</form>
表单外的文本框:<input name="none" />
</body>
</html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
import requests
from bs4 import BeautifulSoup
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0331/11111.html'
news = requests.get(url)
news.encoding = 'utf-8'
newSoup = BeautifulSoup(news.text,'html.parser')
#找出含有特定标签的html元素
newSpan = newSoup.select('span');
print('找出含有span标签的html元素:')
print(newSpan);
#找出含有特定类名的html元素
newInfo = newSoup.select('.show-info');
print('找出class=show-info的html元素:');
print(newInfo);
#找出含有特定id名的html元素
newContent = newSoup.select('#content')[0].text;
print('找出id=content的html元素:');
print(newContent);


3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其它是字符串类型。
import requests
from bs4 import BeautifulSoup
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0331/11111.html'
news = requests.get(url)
news.encoding = 'utf-8'
newSoup = BeautifulSoup(news.text,'html.parser')
#标题
title = newSoup.select('.show-title')[0].text
print('标题:'+title);
#发布时间
newDate = newSoup.select('.show-info')[0].text.split()[0].lstrip('发布时间:')
newTime = newSoup.select('.show-info')[0].text.split()[1]
newDateTime = newDate+' '+newTime
print('发布时间:'+newDateTime);
#发布单位
source = newSoup.select('.show-info')[0].text.split()[4].lstrip('来源:')
print('发布单位:'+source);