Python自然语言处理(1):初识NLP
Python自然语言处理(1):初识NLP
自然语言处理(Natural Language Processing,NLP):计算机科学领域和人工智能领域中的一个重要方向。它研究实现人与计算机之间用自然语言进行有效通信的各种理论和方法,涉及所有用计算机对自然语言进行的操作。
NLP的技术应用日益广泛。例如:收集和手持电脑对输入法联想提示和手写识别的支持;网络搜索引擎能够搜索到非结构化文本中的信息;机器翻译能把中文文本翻译成西班牙文。通过提供更自然的人机界面和获取存储信息的高级手段,语言处理正在这个多语种的信息社会中扮演着更核心的角色。
Python的安装
之前介绍过安装步骤,这里先略过。详情戳这里:Python学习总结之一--基础篇
NLTK的安装
NLTK:Natural Language Toolkit(自然语言工具包)。我们可以从http://www.nltk.org上免费下载符合自己操作系统的版本。下载完成后,跟着步骤直接安装 。

Python版本要求


然后我们在Python解释器里输入代码,下载我们后面学习时需要的数据。

首先,我们输入import nltk成功时就说明我们的nltk安装成功。但是很遗憾,这TM是个问题啊,自己下午搞了很久,下载了好几次都没有成功,我也不知道是怎么回事,网上查找到了一些资源,大家可以在这个博客里找到下载数据的地方。然后自行解压corpora文件里的压缩文件即可。

当你输入代码可以出现上图所示的text1到text9内容的时候,说明你的nltk_data下载成功。
http://www.nltk.org/
https://pypi.python.org/pypi/setuptools
http://www.nltk.org/data.html
NLTK是Python很强大的第三方库,可以很方便的完成很多自然语言处理(NLP)的任务,包括分词、词性标注、命名实体识别(NER)及句法分析。
NLTK安装教程:www.pythontip.com/blog/post/10011/
下面介绍如何利用NLTK快速完成NLP基本任务
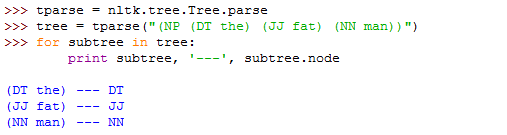
一、NLTK进行分词
用到的函数:
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词

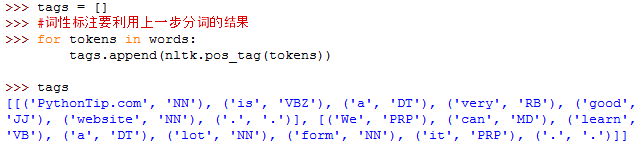
二、NLTK进行词性标注
用到的函数:
nltk.pos_tag(tokens)#tokens是句子分词后的结果,同样是句子级的标注
三、NLTK进行命名实体识别(NER)
用到的函数:
nltk.ne_chunk(tags)#tags是句子词性标注后的结果,同样是句子级
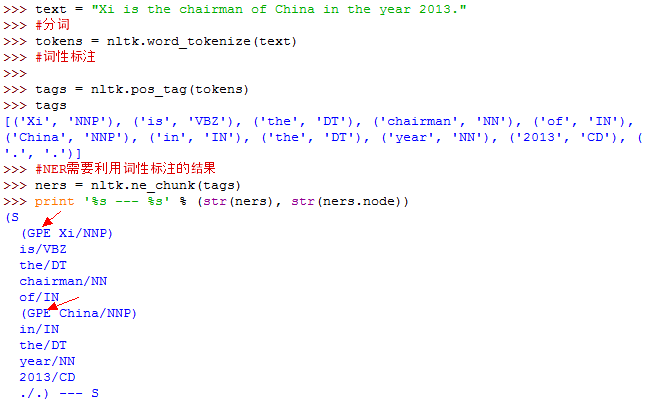
上例中,有两个命名实体,一个是Xi,这个应该是PER,被错误识别为GPE了; 另一个事China,被正确识别为GPE。
四、句法分析